中金 | 另类数据策略(1):文本数据的可能性
Abstract
摘要
2022年底以来以GPT系列为代表的大语言模型引起广泛的讨论,文本数据在量化策略中的应用也开始受到重视。但多样的NLP模型和海量的文本信息本身都给量化策略应用另类数据带来了不小难度。本篇报告主要聚焦各类文本数据和NLP模型的特点与用法,探讨如何将文本数据有效融入量化投资的分析框架。
海量的另类数据:
文本信息的探索路径
从数据到最终的策略应用,量化模型的产生基本都可以被拆分数据、模型和场景三大板块。我们可以尝试的方向最多为数据种类D、模型类型M以及落地场景S之间的乘积:Strategy=D*M*S。面对多样的可能性,对于量化策略来说在有限的资源和时间约束下,更高效地挖掘隐藏在海量文本数据中的增量信息将是我们的重要任务之一。
综合信息增量和开发成本,我们认为探索性价比较高的另类数据有新闻文本、研究报告、定期报告等文本数据。文本数据信息含量丰富度较高、覆盖面广,NLP模型的复杂度和准确度对于量化策略效果的提升或不是唯一重点,尝试提高数据信噪比和提升数据与场景组合的丰富度,有针对性地应用NLP模型也是同样重要的探索方向。
多样的NLP模型:
文本相似度、情感判别和内容生成
文本数据具有丰富的信息含量,处理文本数据的NLP模型也较为多样。我们可以将文本处理模型按特点大致分为三类:词频模型、词向量模型、预训练模型;也可以按照使用方法分为三大类:文本相似度、情感判别与内容生成;每种模型分别具有不同的优缺点和应用场景。
词频模型:应用简单原理直观,对计算资源几乎无要求,但只考虑词频信息,信息提取能力弱,适合快速简单的情感判别;词向量模型:练成本相对较低,运算效率较高,过拟合、黑箱等问题较少,但无法解决一词多义问题,适合计算文本相似度;预训练模型:功能强大,判别准确,但可能有黑箱、虚假内容生成等问题,微调时需样本自带标签,训练成本相对较高,适合高精确情感判别与内容生成。
丰富的应用模式:
不仅限于情感判别
目前市面上常见的文本数据的应用方法主要以情感判断为主,但我们认为文本数据在量化领域发挥作用的场景应该更为丰富。我们在这一章展示当前我们在各类量化策略场景下应用不同文本数据的已有成功案例。
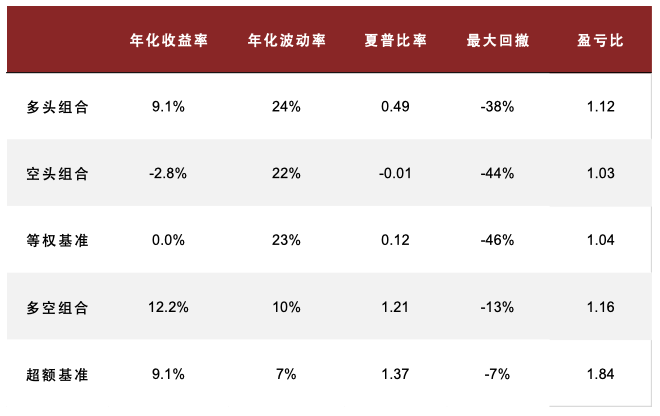
文本在选股与行业轮动:使用文本数据构建20日预期调整的情感因子,多空策略和多头超额的夏普比率为1.73和1.90,多头超额年化7.9%,且与现有因子相关性均较低。构建的高信噪比行业轮动因子多空与超额年化收益率12.2%与9.1%,超额基准的盈亏比达到1.84,单因子表现位于中金轮动2.0体系已有因子前列。
分析师研报用于判断市场主要矛盾:纳入使用分析师研报来判断主要矛盾的择时策略可以取得2010年以来共11.96的累计净值,优于通胀维度择时7.37的累计净值,显著强于经济增长、流动性维度的择时净值以及沪深300的同期表现。
基金定期报告用于大势研判和行业配置:使用基金定期报告文本预测乐观与悲观区间与市场大势较为相符。在乐观区间,展望文本词频变化率Top5行业在未来20日平均收益率、Top3行业在未来40日平均收益率表现较好,相对Wind全A指数,前者胜率89%,后者胜率78%。
风险提示
模型基于历史数据构建,未来可能存在失效风险;全文模型结果基于文本数据来源的稳定性,当文本数据来源发生变化时,模型效果也会出现偏差,例如数据商提供另类数据时可能会对数据进行初步筛选和处理,处理方法变更可能对模型表现有影响;本文提到的所有量化模型仅在特定的测试框架下可以达到文中展示的测试效果,测试框架变化会对模型表现有一定影响。
Content
正文
自去年年底以来,GPT等相关人工智能模型在NLP领域受到广泛的讨论和关注,关于如何挖掘另类数据特别是文本数据所隐含的信息的方式重新进入大众视野。但大模型的海量参数和更加海量的文本信息本身都给量化投资使用另类数据模型带来了不小的难度。本篇报告主要聚焦各类文本数据和NLP模型的特点与用法,探讨如何将文本数据有效融入量化投资的分析框架。
另类数据: 金融数据的蓝海
我们在《量化投资新趋势(3):驶向另类数据的信息蓝海》报告中提到量化策略的发展一直交织着明暗两条线索,明线是量化策略模型的发展,暗线则是金融数据体量的快速增长。从技术图形分析到因子理论再到高频交易,量化模型的发展与可用数据的发展紧密相关。近些年机器学习模型的井喷发展除了算力大幅提升外,更重要的是具有可供学习的对象,也即输入数据,例如社交媒体上大量图像数据可供如Google、Meta这样的互联网公司作为模型输入数据使用。
对于量化领域来说,现有的结构化数据在经历十几年发展后可供挖掘的信息逐渐匮乏,市场策略逐渐饱和且新策略开发速度难以跟上资金体量的增长。我们认为量化策略后续发展的重要趋势之一为量化策略对“另类数据”的挖掘和使用,如何发掘另类数据以及用合适的方法将其应用在合适的模型之中是量化策略未来发展的重要方向之一。我们发现海外已有不少大型资产管理公司积极布局另类数据在量化策略中的应用。
海外基金积极布局文本数据在投资中的应用
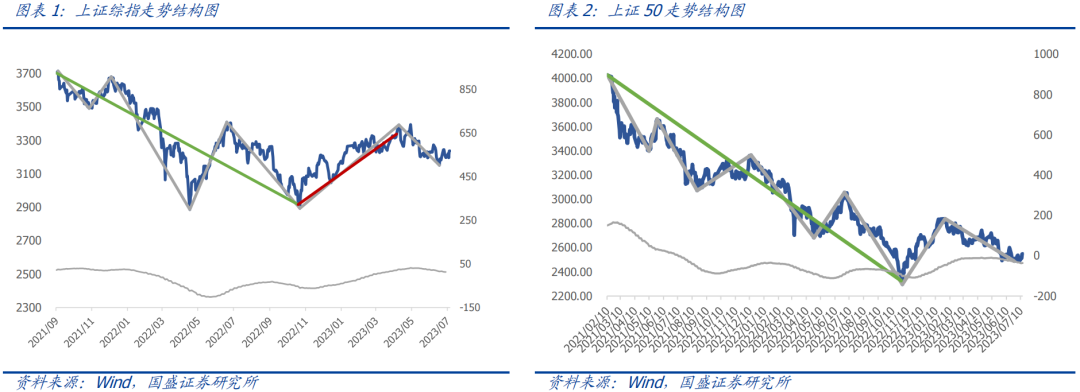
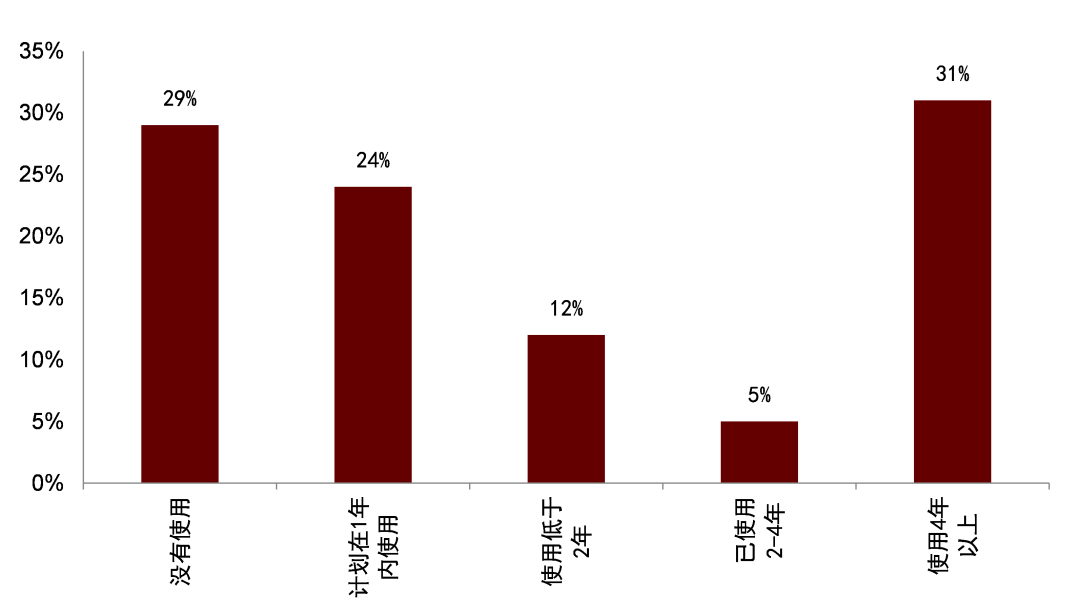
早在2019年Greenwich Associates[1] 采访了全球投资管理公司的42位CIO、投资组合经理和投资分析师。受访者回答了有关未来 5-10年投资研究将如何变化的问题。关于他们是否打算使用另类数据,近50%的投资经理表示他们正在使用另类数据,另有接近四分之一计划在未来 12个月内使用该数据。而在回答有关管理者期望增加或减少他们对哪些信息来源时,另类数据也是受访者回答中希望增加使用比例最高的信息来源。
图表1:使用另类数据的时长分布
注: 问卷采集时间为2019年
资料来源:格林尼治协会,中金公司研究部
图表2:是否打算使用另类数据
注: 问卷采集时间为2019年
资料来源:格林尼治协会,中金公司研究部
图表3:基金公司应用另类数据种类
注: 问卷采集时间为2019年
资料来源:格林尼治协会,中金公司研究部
我们在《另类数据策略(3):文本信息助力主题投资》对多家海外知名对冲基金如何使用文本数据做了研究探讨。以主题投资这一话题为例,Fidelity、BlackRock、ManGroup 等知名基金公司均采用了文本信息进行主题策略的构建。
►Fidelity 结合价量数据和基本面数据,利用NLP技术对选定主题的成分股进行筛选。首先,他们会挖掘选中主题的子主题和相关业务活动,例如在清洁能源主题下的太阳能、风能和氢能。然后,他们通过市值和流动性等指标来筛选股票,从而过滤掉潜在风险较高的股票。
►BlackRock 根据主题评估体系构建主题轮动策略。BlackRock 使用直接和间接的方式充分捕捉相关主题的成分股。直接方式为获取主题指数的成分股标的以及卖方研究员构建的主题股票池;间接方式为采用NLP 技术,利用新闻、财报等另类数据将主题和公司相联系,从而识别主题的成分标的。
►ManGroup 采用麦肯锡的框架,将主题投资流程总结为几个关键步骤。首先利用另类数据和深度研究确定主题,另类数据包括 PE 和 VC 的交易数据,从中识别出较前沿的主题;其次匹配和主题相关的成分股,ManGroup 同样使用到NLP 技术识别和主题相关的关键词,并找到曝光率较高的公司。
图表4:Fidelity 主题投资步骤

注: 截止2023-08-31
资料来源:Fidelity,中金公司研究部
图表5:BlackRock 主题投资步骤

注:截止2023-08-31
资料来源:BlackRock,中金公司研究部
量化投资模式: 数据x模型x场景
我们认为从数据到最终的策略应用,一个量化模型的产生大致可以分为三大要素,即数据、模型和场景,所有量化模型基本都可以被拆分为这三大板块。量化模型的种类也可以按照这三大要素的组合来划分。例如,我们可以使用数据里的新闻数据,模型里的情感打分,再落地到因子选股层面,于是我们得到了一个使用新闻数据结合BERT模型情感打分的事件驱动策略。又或者我们可以使用调研数据,结合文本相似度模型,得到一个调研因子选股策略。我们可以尝试的方向即数据种类D、模型类型M以及落地场景S之间的乘积:Strategy=D*M*S。
图表6:量化应用另类数据的丰富组合

资料来源:数库,Wind,中金公司研究部
可以尝试的方向很多但我们可以投入的资源往往是受限的,特别是当涉及到深度学习等模型的时候,算力成本和训练模型的时间成本已经难以忽视。一旦方向选择有误,很有可能前期长期投入换来的模型效果不会非常理想。因此本文聚焦不同数据和模型的特性,希望能尽量找出适合不同另类数据类型的模型和在量化投资中的应用场景,我们希望在有限的资源和时间下,能够更加高效地挖掘隐藏在海量另类数据中宝贵的增量信息。
虽然另类数据的历史源远流长,但量化策略对非结构化数据的应用历史却是刚刚启程,主要原因是在NLP等模型及高效的信息采集与传输技术出现之前,量化策略开发者们不能批量使用非结构化数据来满足量化交易策略体系化的特点。因此在2010年之前,量化策略主要使用的数据仍然是价量交易数据和上市公司披露的年报数据等,通过对此类数据的分析以及在各类模型中的应用,构造出可以形成超额收益的量化模型帮助做出交易决策。
由于价量及基本面数据的易得性,多种基于该类数据的量化策略迅速发展,模型的复杂性也随之升高,市场策略拥挤度一再上升,导致模型失效的周期也进一步缩短。一方面,近年来量化私募的快速发展导致了规模快速扩张,而单个量化策略本身的容量有限,同时很多量化策略难以随着规模的快速上升而迅速调整。另一方面,去年以来的量化基金收益率高波动和去年末的大幅回撤也使得市场出现对于量化策略高度同质性的一些质疑。
由于金融市场发展阶段的差异性,这种情况在海外发生的时间更早。参考美国私募市场发展情况,量化策略在2000年到2008年经历过一段快速增长期,后来由于市场策略的拥挤度逐渐升高,增长速度逐渐放缓。随着近10年来的科技发展,机器学习和NLP等技术使得文本数据等非结构化数据得以作为量化模型的输入数据,量化投资公司开始逐渐重视另类数据在量化策略中的应用,并总结出下另类数据相对传统数据的优势。
图表7:另类数据和传统数据的优势对比
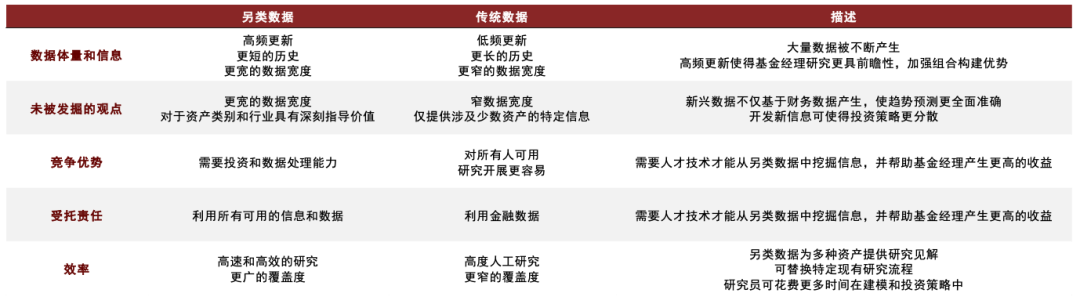 资料来源:Eagle Alpha,中金公司研究部
资料来源:Eagle Alpha,中金公司研究部
我们在《量化投资新趋势(3):驶向另类数据的信息蓝海》给另类数据下了这样一个定义:对量化策略来说,金融领域中应用较少的,或产生目的原本并非为了应用在投资和金融领域的数据即可被称之为另类数据。基于此,对于量化策略来说另类数据的范围十分广泛,从何入手是一个十分值得考虑的问题。我们可以考虑投入产出比指标,将该数据可能蕴含的信息量与处理该数据需要花费的资源的比例作为考虑的主要因素,再结合现有资源考虑尝试另类数据投资的顺序和方式。
对于量化投资来说我们考虑的信息量比较的基本原则为:如果该信息只含有部分行业信息,则其蕴含信息量小于具有全行业信息的数据,例如信用卡数据<新闻数据;更短历史的数据蕴含的信息量则小于更长历史的数据量。成本端我们则主要考虑获取难度、处理难度、所需计算资源和训练时间等因素。
从信息增量端和成本端综合来看,开发性价比较高的数据类型有:新闻文本、供应链、研究报告等。此类数据虽然需要使用一定的自然语言处理模型,但数据信息含量总体较高,且相对于港口和电商等数据类型,文本类数据覆盖面更广,如新闻文本数据涉及到上市公司基本可以覆盖全市场所有A股上市公司,而电商销售或港口交通数据则仅能分别覆盖部分消费类上市公司和交运类上市公司等。
中文文本数据处理方法
中文文本处理方法主要有以下几步:1.获取数据,2.语料预处理,3.特征工程,4.模型训练,5.模型表现评价。
图表9:NLP模型处理数据流程
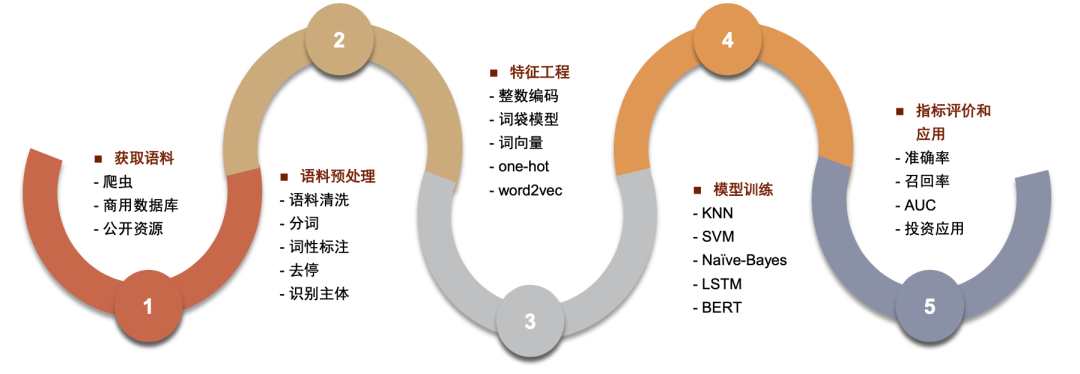
资料来源:数库,Wind,中金公司研究部
►获取数据
获取文本数据是NLP流程的第一步,主要途径有公开网页内容抓取,利用商用数据库和公开资源等方式。
►公开网页内容抓取是一种提取网络信息的自动化工具。设定目标网址后,利用特定编程库(如 Python的requests和urllib)模拟浏览器行为,向网址发送请求并获取响应数据。该数据可能呈 HTML、JSON 或 XML 格式,需借助解析工具(如BeautifulSoup 库)进行处理。 ►商业数据库则由各类商业实体运营,涵盖由新闻媒体、金融服务机构及市场研究公司发布的文本数据,如新闻报道、市场研究报告等。国内知名的金融商业数据库如Wind 资讯和同花顺 Choice、数库和米筐等。 ►公开资源为政府、学术机构或其他组织公开发布的数据,包含政府报告、公告,学术研究论文等。例如,国家统计局发布的社会经济统计公报、中国人民银行的金融政策解读,以及上海和深圳证券交易所的上市公司公告等,均可作为 NLP 的语料。
► 特征工程
特征工程是将预处理后的词序列转化为机器可读取的数据形式的过程。常见的文本表示方法包括整数编码、One-hot 编码、词袋模型和词向量方法等。
► 模型训练
选定特征向量后,我们需要将其输入到机器学习模型中进行训练。根据任务需求,可以选择不同的模型,包括传统的有监督或无监督学习模型(例如 KNN、SVM、朴素贝叶斯、决策树、GBDT、K-means 等),或者深度学习模型(例如 CNN、RNN、LSTM、Seq2Seq、FastText、TextCNN 等)。报告第二节将详细介绍在不同应用领域中具有代表性的模型的工作原理和结构。在模型训练过程中,我们需要特别关注过拟合、欠拟合,以及深度神经网络中的 梯度消失(Gradient Vanishing)和梯度爆炸(Gradient Exploding)问题。
►模型表现评价
评估模型的表现是机器学习流程中的重要一步,我们需要确保模型在未见过的数据上有良好的泛化能力。针对二分类问题,我们可以根据真实类别和预测类别,将样例分类为真正例(True Positive, TP)、假正例(False Positive, FP)、真反例(True Negative, TN)、假反例(False Negative, FN),分类结果的“混淆矩阵”(Confusion Matrix)如下。
图表10:混淆矩阵

资料来源:数库,中金公司研究部
基于这些统计量,我们可以计算准确率和召回率:准确率(Precision, P):预测为正的样本中,实际为正的比例;召回率(Recall,R):所有真实的正样本中,被正确预测出的比例。计算公式为
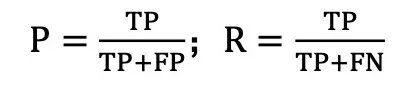
此外,ROC (Receiver Operating Characteristic) 曲线也是一个重要的评估工具。在构建 ROC曲线时,我们会调整模型的决策阈值,这个阈值是我们确定预测结果是正例还是反例的界定标准。具体操作是,将阈值从最小值(此时所有样本均预测为正例)逐步提高到最大值(此时所 有样本均预测为反例)。在此过程中,我们分别计算每个阈值下的真正例率(True Positive Rate,简称 TPR)和假正例率(False Positive Rate,简称 FPR),然后以 FPR 为横坐标,TPR 为纵坐标画图,即得到 ROC 曲线。
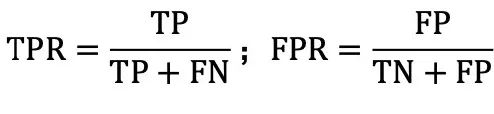
ROC 曲线还可以用于比较不同模型的性能。在 ROC 曲线图中,越靠近左上角的模型性能越好。因为左上角意味着模型在保持高真正例率的同时,假正例率较低,即模型对正例的识别能力强,且误判为正例的反例数量少。我们通常会比较 ROC 曲线下面积,即 AUC(Area Under the ROC Curve),作为衡量模型优劣的依据。AUC 值越大,说明模型的分类性能越好。
NLP模型: 文本相似度、情感判别和内容生成
本文第二部分我们将重点讨论量化模型构建三要素中的第二大要素:模型要素。另类数据从获取到落地可以大致分为两个步骤:1.从非结构化的另类数据到结构化数据;2.结构化数据到交易信号。对于文本数据来说,要真正挖掘文本数据中的信息还需要重点依赖于多种自然语言处理(NLP)模型。
图表11:文本数据在应用到量化投资的步骤
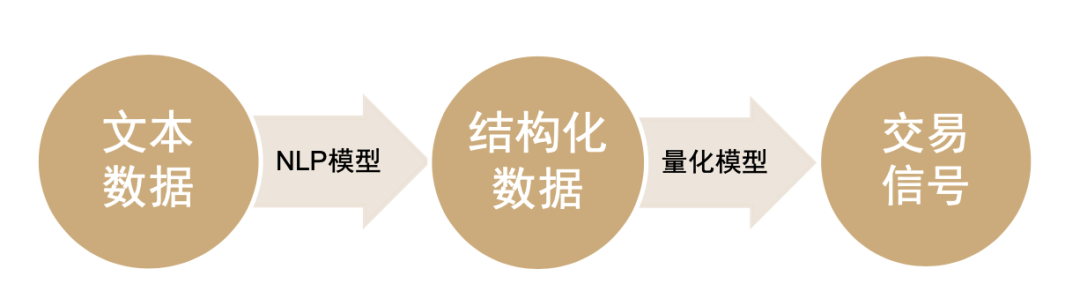
资料来源:数库,Wind,中金公司研究部
资料来源:数库,中金公司研究部
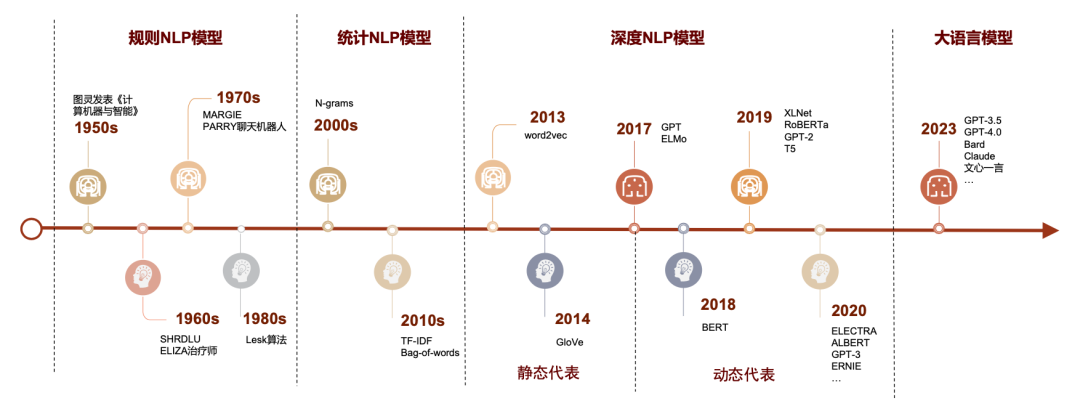
在深度 NLP 模型出现以前,各类模型的区别较为明显。规则与统计的 NLP 模型原理直观,计算资源少,速度快,但对于文本信息使用率较低,模型基本只使用词频信息,对于词与词的关系则无法建模。深度NLP 模型则尝试对词与词的关系进行建模,将词语通过神经网络模型转化为向量,通过向量间关系的映射对应词与词之间的关系。早期尝试如 word2vec 与 GloVe 模型通过词语之间的相对位置训练神经网络,将神经网络中的节点参数作为词语的代表向量。这种做法一方面显著提高了文本信息的利用率,另一方面在计算资源上的占用相对较小,其中训练所用神经网络模型结构较为简单,训练时间也通常较短;但此类模型也存在较大局限性,其中最明显的问题之一是无法解决一词多义问题,如苹果一词可指代苹果公司或一种水果,当两种用法在训练数据中同时出现时,苹果一词的词向量大概率会是以上两种截然不同语义代表的 词向量的简单混合,而这种结果基本会导致该词语具备的词向量信息的基本失效。2018 年后的以BERT、GPT等模型为代表的深度学习NLP模型则通过引入动态代表(dynamic representation)机制使得同一词语的词向量随其在文本中的位置不同动态调整有效解决了一词多义等多种问题,代价是参数量进入亿级,GPT3.5 模型则直接超过千亿级别,随模型参数上升的还有模型训练时间的提升,仅仅是在小样本上迁移学习的时间成本就难以忽略。
图表13:NLP主要模型横向对比
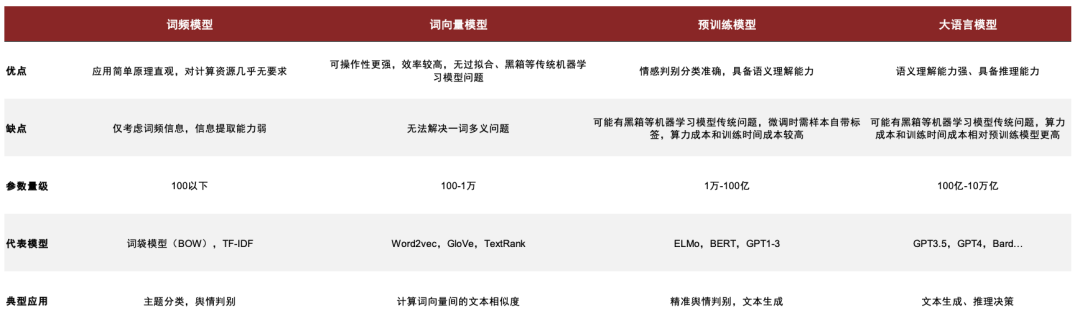
资料来源:数库,中金公司研究部
词频模型: 主题分类+情感判别?
词频模型是 NLP 模型发展初期原理最直观的模型类别之一。它忽略掉文本的语法和语序等要素,将其仅仅看作是若干个词汇的集合,文档中每个单词的出现都是独立的。它不考虑句子中单词的顺序,只考虑词表(vocabulary)中单词在句子中的出现次数。向量中每个位置的值为该编码对应的词在这段话中出现的次数。由于词频模型提取的信息相对较少,其的应用场景较为有限,主要可以用作文本主题分类和简单的情感判别。
词袋模型
资料来源:数库,中金公司研究部
►TF-IDF 原理
►TF-IDF 的应用实例:
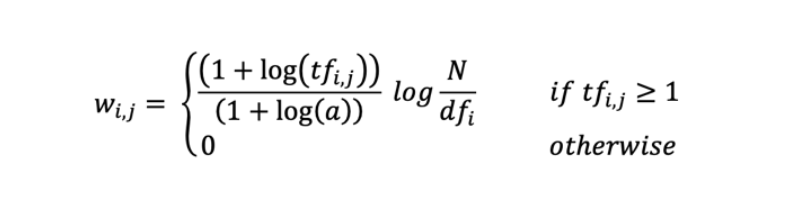
他们强调,在使用词袋模型时,如何选定词语的权重是一个关键的步骤,因为仅仅基于简单的词频计数得出的权重并不能充分反映词语在文本中的实际含义。他们还发现,选择更适合的词语权重可以有效地减少由于词语分类错误所产生的噪声。
静态向量模型: 文本相似度
计算文本相关性是 NLP 中的一类基本任务类型。主要是通过语义识别,计算两文本之间在语义上的相关关系,具体包含两句话意思的相似性及两句话在上下文中的关联度。LAURENCOHEN 通过计算上市公司年报文本在时间序列上的相似性,构造出文本相似性因子和有效的交易策略。
Word2Vec模型
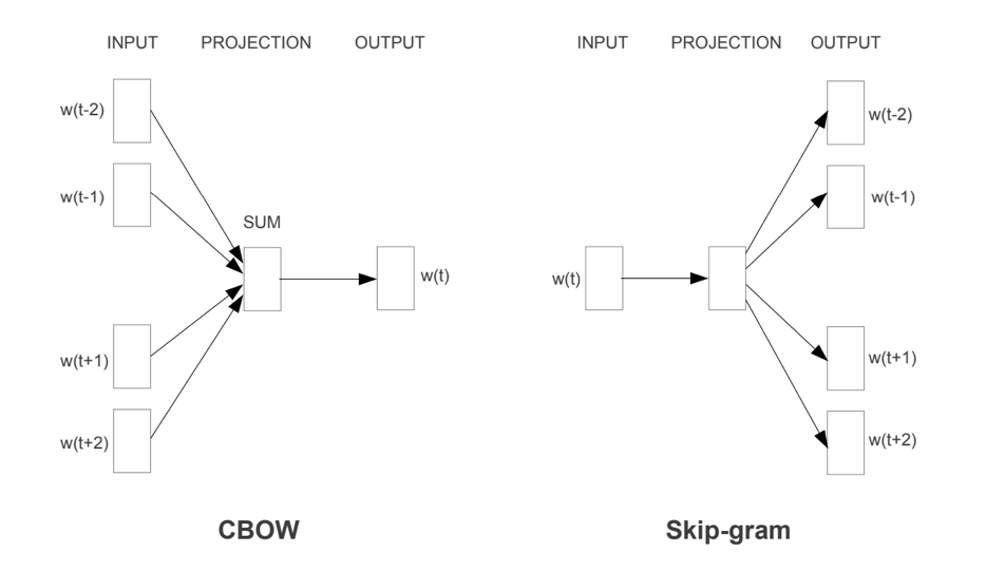
Mikolov 在 2013 年提出了在 NLP 领域具有里程碑意义的 word2vec 方法,利用词嵌入的概念将词汇从离散表示(one-hot 编码)转化为连续的数值向量,从而大大提高了词向量蕴含的信息以及模型效率。Word2vec 采用了两种训练方式(CBOW 和 Skip-gram),以及两种优化算法(Hierarchical Softmax 和 Negative Sampling)。
►Word2vec 模型原理
Word2vec 所用到的 CBOW 和 Skip-gram 都是轻量级的神经网络,本质上只有输入层和输出层两层,CBOW 是在知道中心词上下文的情况下预测中心词;而Skip-gram 则正好相反,是在知道词中心词的情况下对其上下文进行预测,简化示意图如下所示。
图表15:CBOW 和 Skip-gram 模型结构
注:数据截至2023-08-31
资料来源:Mikolov,T., Chen, K., Corrado, G.,&Dean,J.,2013,“Efficient Estimation of Word Representations in Vector Space”
具体而言,CBOW 模型的输入是周围上下文词的词向量(one-hot 编码)。CBOW 模型的输出是一个softmax函数计算出的概率分布向量,每个单词作为中心词的概率(训练的目标是使得实际的中心词在该概率分布中的概率最大)。另一方面,Skip-Gram模型的输入是中心词的词向量(one-hot编码),模型的输出是一组概率分布,每个概率分布对应一个上下文位置,表示所有词汇作为该上下文词的可能性。
图表16:CBOW 模型原理示意图

资料来源:中金公司研究部
在 word2vec 模型中,每个词生成的词向量是固定且与语境无关的(即“静态向量模型”),这导致同一词在不同语境下,即使含义不同,其词向量却相同。而深度学习的预训练模型(下文将展开介绍)可以克服这个限制,生成的词向量能根据上下文动态调整,即同一词在不同语境下,其词向量也能随之改变。文本相似度评估的一般步骤为:生成文本的向量表示,再将其输 入距离函数计算文本之间的距离。Word2vec 是一种常见的生成词向量方法,而文本距离描述了两个文本词的语义接近程度,常用的距离函数有余弦距离、欧氏距离、曼哈顿距离等。
►Word2vec 的应用实例
姜富伟等 2021 年发表的《媒体文本情绪与股票回报预测》3论文在 Loughran and McDonald(2011)词典(以下称作 LM 词典)的基础上通过人工筛选和 word2vec 算法扩充,构 建了一个更新更全面的中文金融情感词典。他们用到的文本素材来源于 infobank 数据库中的经 济新闻库,该数据库收集了 1992 年至今每日更新的新闻数据。
此词典的构建分为三个部分:1)将英文 LM 词典转为中文版本;2)从中文通用情感词典中筛选出在金融语境下适用的情感词汇;3)利用 word2vec 算法从语料中找到与前两部分词语高度相关并且具有合适情感倾向的词语。最后,将上述三种方法得到的词语合并去重后得到最终的中文金融情感词典。作者指出,根据 Mikolovetal(2013),Skip-gram 模型估计准确率高于CBoW,且在低频词上表现更加明显,所以文章采用 Skip-gram 作为词嵌入模型,并将词语向量的维度设置为 200 维。完成词向量训练后,作者采用了余弦相似度的度量方式来确定词语之间的相似度,然后为每个词语选取了五个最相似的词语,以扩充字典。我们在下文也将介绍如何在判断市场主要矛盾、判断基金经理前后一致性中应用 word2vec模型计算文本相似度,来得到文本样本之间的相关性。word2vec 在构建相关词表、文本主题聚类都有较稳定表现,其计算资源的占用也相对较低。其他的经典词向量模型如GloVe、TextRank等也有较丰富的用法。
预训练模型: 情感判别+文本生成
预训练模型是指为节省算力和时间成本,预先在一个大型的数据集上进行过训练的模型。应用预训练模型实际包含两个过程:预训练和微调(fine-tuning),后者是一种针对单个任务的迁移学习过程。例如假设我们有大量的文本数据,那么我们可以用这部分体量较大的数据来训练一个泛化能力很强的模型,当我们需要在特定场景使用时,例如做命名实体识别,那么,只需要简单的修改一些输出层,再用我们自己的数据进行一个增量训练,对权重进行一个轻微的调整即可。预训练语言模型有多种,典型的如 ELMo、GPT、BERT 等。其中 GPT3.5 及以上版本又因为其参数量过于庞大(超千亿)被命名为大预言模型(LLMs)。BERT 由于采用了双向结构,其在情感判别等方面和同等参数量级的其他预训练模型对比优势更加明显。
图表17:BERT、GPT 与 ELMo 预训练模型结构差异
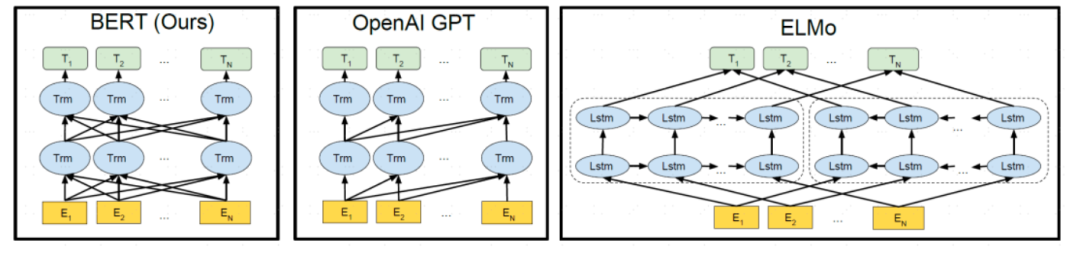
BERT资料来源:Devlin,J.,Chang,M.,Lee,K.,&Toutanova,K,2018,“BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding”
BERT模型
BERT 由 Google AI 团队的 Devlin 在 2018 年提出,全称为 Pre-training of Deep Bidirectional Encoder Representations from Transformers,BERT是一个基于 Transformers encoder 的深度双向预训练语言理解模型。Bidirectional 也是 BERT 的主要创新点:BERT 前的预训练语言模型,如 ELMO 和 GPT 的方向都为单向(ELMO 是两个方向相反的单向语言模型的拼接),都忽略了结合上下文的语义信息对文本理解任务的重要性。
图表17:BERT模型主要训练过程
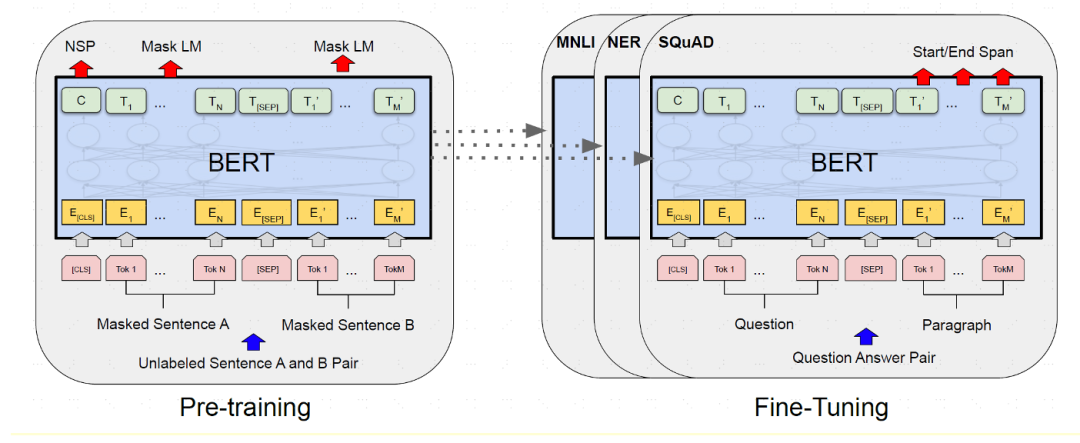
BERT资料来源:Devlin,J.,Chang,M.,Lee,K.,&Toutanova,K,2018,“BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding”
BERT 自推出以来受到广泛应用。Mingzheng Li 等人(2021)4使用预训练的 BERT 模型对中国股票评论文本进行情感分析。鉴于带有标签的数据量有限,他们选择了由逻辑回归生成的标签数据作为微调阶段的数据集,该数据集包含 9204 条评论,其中一半为正面评论,一半为负面评论,逻辑回归的准确率达到 88%,表明它可在微调后应用到其他数据集的任务中。
GPT系列模型
GPT-1 的提出要早于 BERT 模型,也是采用“预训练-微调”的模式,即在大规模无标记的文本语 料上进行无监督的预训练,然后再在特定任务上进行有监督的微调。与 BERT 双向掩码语言模 型不同,GPT 是自回归语言模型。BERT 由 Transformer 的 Encoder 部分堆叠组成,而 GPT使用的是 Transformer Decoder 部分,更适合文本生成任务。
GPT 预训练的流程可大体分为三步:1)使用 ftfy 库和 spaCy 对 BooksCorpus 语料库分别进 行清洗和分词,并将分好词的文本序列输入模型嵌入层。GPT 的嵌入层使用了 Token 嵌入和Position 嵌入。2)这些词嵌入被送入多层 Transformer Decoder(即 Decoder Stack)中,其 中每一层都包含自注意力机制和前馈神经网络;3)最后一层 Transformer Decoder 的输出经 过 softmax 函数,得到每个位置中有关下一个 token 的概率分布。
GPT-2:2019 年,GPT-1 的迭代版本 GPT-2 由 OpenAI 的 Alec Radford 和 Jeffrey Wu 等人 在论文《Language Models are Unsupervised Multi-task Learners》中提出。GPT-2 模型结构 和 GPT-1 同为自回归语言模型,仍由多层 Transformer Decoder 组成,但是相比 GPT-1,GPT-2 的预训练所使用的数据以及参数规模变得更大,参数规模约为 GPT-1 的 10 倍;此外,GPT-2 摒弃了 GPT-1 中的“微调”模式。此举是由于 OpenAI 认为语言模型应该直接冲击零 样本无监督多任务学习器的目标,即预训练好的模型可以直接用于下游任务。
GPT-3:OpenAI 于 2020 年继续提出了 GPT-3 模型,其延续了 GPT-2 中单向 Transformer 的 自回归语言模型结构,但它的模型参数规模是 GPT-2 的 100 倍,共有 1750 亿个参数。此外,GPT-3 不再追求 zero-shot 的设定,而是在下游任务中给定少量标注的样本让模型学习再进行 推理生成。因此,GPT-3 主要展示了超大规模语言模型的小样本学习能力。
除 2022 年以来热度最高的CHATGPT 相关模型外,彭博(Bloomberg)在 2023 年 3 月发布了一篇 关于 BloombergGPT 发开情况的研究论文,详细介绍了这一专注于金融领域的大规模生成式 人工智能模型5。BloombergGPT 仍由多层 Transformer Decoder 组成,核心突破在于构建了 超 3,000 亿词例(token)的金融训练数据集。开发团队从彭博积累的大量英文金融文档数据 库中提取并创建了一个包含 3,630 亿词例的金融数据集。该数据集又与另外一个包含 3,450 亿 词例的公共数据集叠加,形成一个包含超 7,000 亿词例的大型训练语料库。BloombergGPT 基 于彭博研究人员开创的混合训练法,通过将金融数据与通用数据集结合起来训练模型,既可以 在金融基准上取得最佳结果,同时也可以在通用语言模型的基准上保持足够的竞争力。BloombergGPT 能够全方位地支持金融领域的各种任务,比如生成彭博查询语言(BQL),新闻标题建议,以及金融问题回答等。
文本数据、模型与投资场景的组合
在量化策略使用文本数据的场景中,是否上述更复杂更深度的模型在量化投资里的效果就一定 比一些简单模型更好呢?我们认为很多时候可能并非如此。比如在一个对最终模型效果对情感 判断准确度并不敏感的任务中,当一个精心设计的词袋模型对于情感判别模型到达了 85%的准确度,而一个 BERT 模型需要额外进行大规模长时间的微调才能勉强达到 90%时,前者并非毫无吸引力,特别是考虑 BERT 模型的一些黑箱问题和训练维护成。又或者使用一个已经使用 中文金融语料预训练好的 fin-BERT 模型可以达到 90%的判断水准,而对模型结构或参数的进 一步优化和训练可以令其达到 92%甚至 93%的水平,此时 NLP 模型的复杂度和情感判别准确 度对于量化策略效果的提升或许不是唯一重点,尝试提高数据信噪比和提高数据与投资的丰富 组合方式,有针对性地应用 NLP 也是量化策略同样重要的探索方向。因此我们在文本数据的 探索多样化程度较高,以下展示我们使用各类文本数据在因子选股、行业轮动、大势研判等多种场景下的应用案例。
新闻文本数据用于因子策略与热点主题获取
新闻数据是目前另类数据中使用场景最丰富,历史也相对较长的数据种类之一。不仅可以根据 新闻本身的热点属性创造市场热点轮动的投资组合,还可以根据新闻的情感倾向创造选股投资 的因子策略,或者将新闻数据聚合至行业风格做进一步轮动策略。我们在本篇报告中对其测试 结果做简单介绍展示,具体内容请参考《另类数据策略(2):如何优化新闻文本因子》。我们使用数库提供的文本数据聚合至个股和行业层面构造选股和行业轮动新闻文本因子。
数库科技提供的情感判别结果为 0 为中性,1 为乐观,2 是负面打分,在实际应用中被转换为-1。数库打分细节中还有对各类判断的置信度。数库的新闻数据数量总量在过去十年逐年上升,2016 年前涉及上市公司的新闻数量不超过 60 万篇,至 2022 年已超过 800 万篇;覆盖度在基本宽基指数种的覆盖率也较为稳定,近十年在中证 800 种的覆盖率稳定高于 97%,全 A 覆盖率也稳定高于 90%。
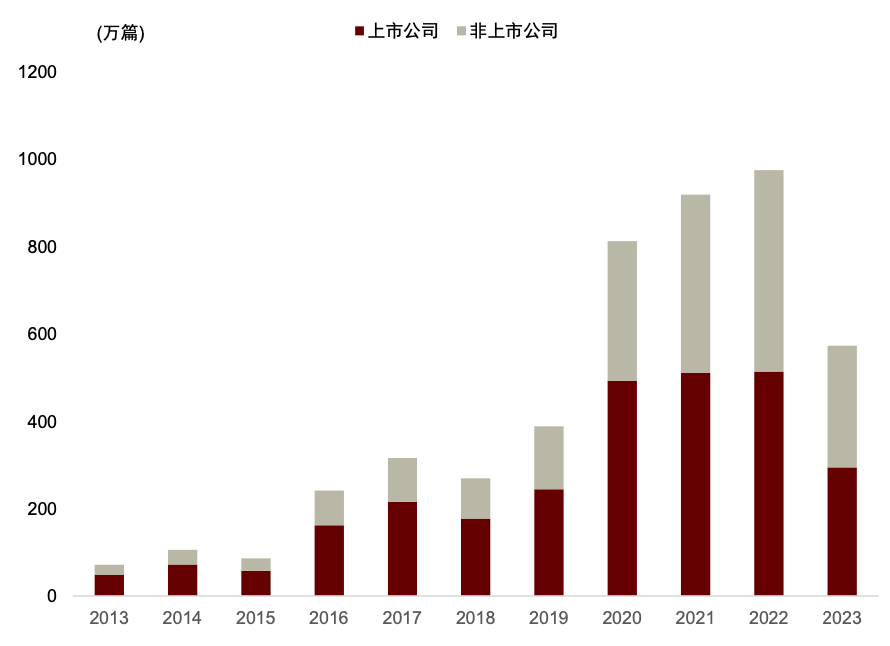
注:数据截至2023-08-31
资料来源:数库,Wind,中金公司研究部
图表21:数库新闻数据覆盖度
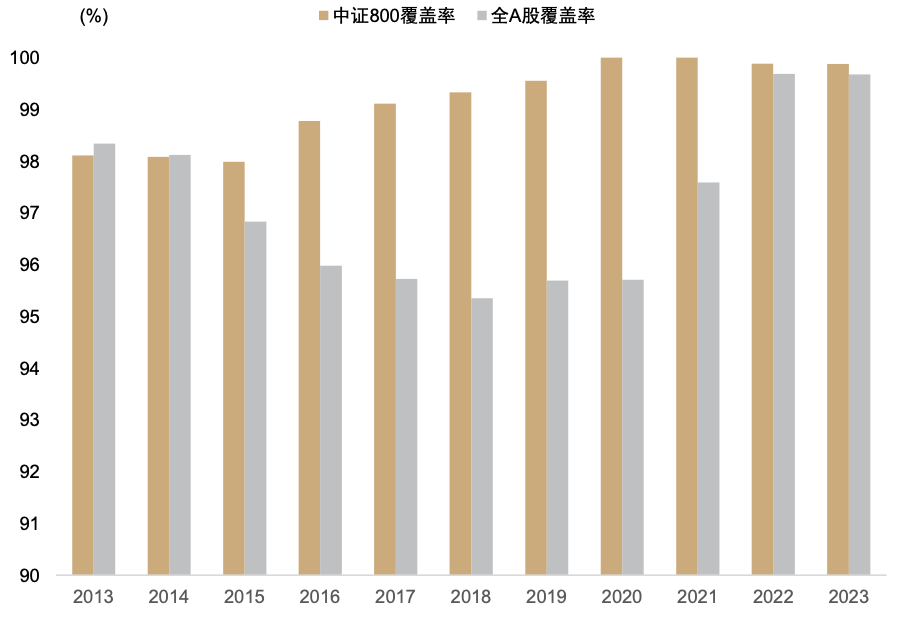
注:数据截至2023-08-31
资料来源:数库,Wind,中金公司研究部
新闻 X 情感判别 X 因子选股
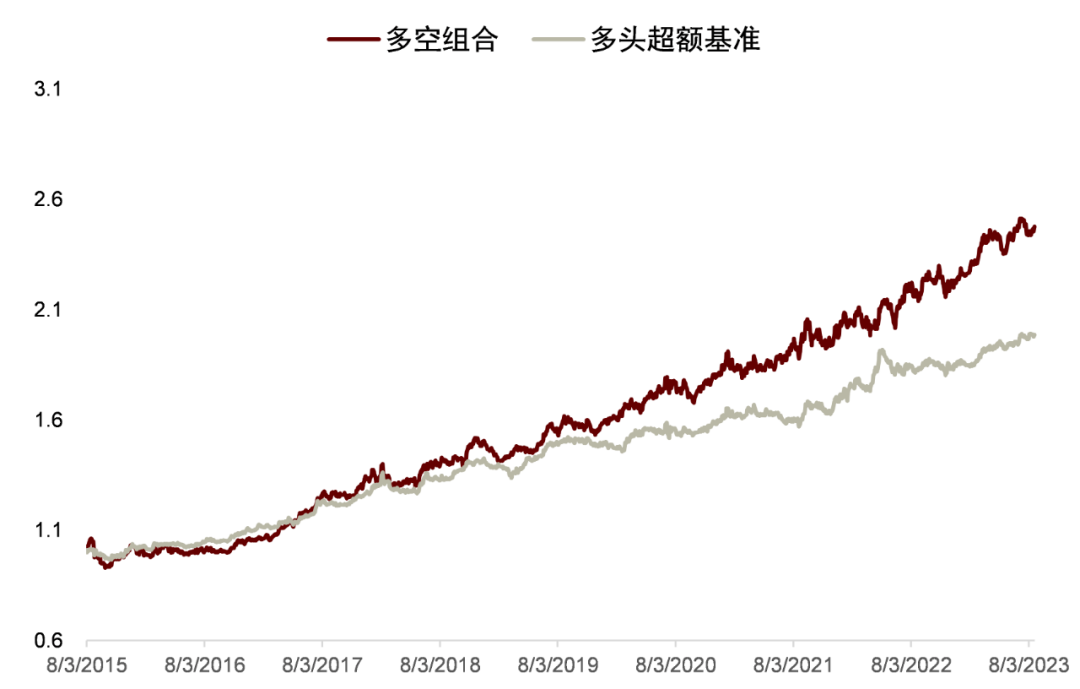
在《另类数据策略(2):如何优化新闻文本因子》中,我们根据公司相关性、新闻重要性对新闻文本进行筛选后发现提高信噪比的文本选股效果。测试得到使用 60%公司相关度、2 级重要性筛选新闻构建的高信噪比因子多空年化收益达 13.8%,夏普提升至 1.60,超额部分年化收益7.4%,夏普为 1.75。在此基础上我们进一步设计计入预期的新闻文本因子,其多空策略和多头超额的夏普可进一步提升至 1.73 和 1.90,且新因子与传统因子相关性均较低。
图表22:高信噪比新闻文本因子IC 与累计IC序列
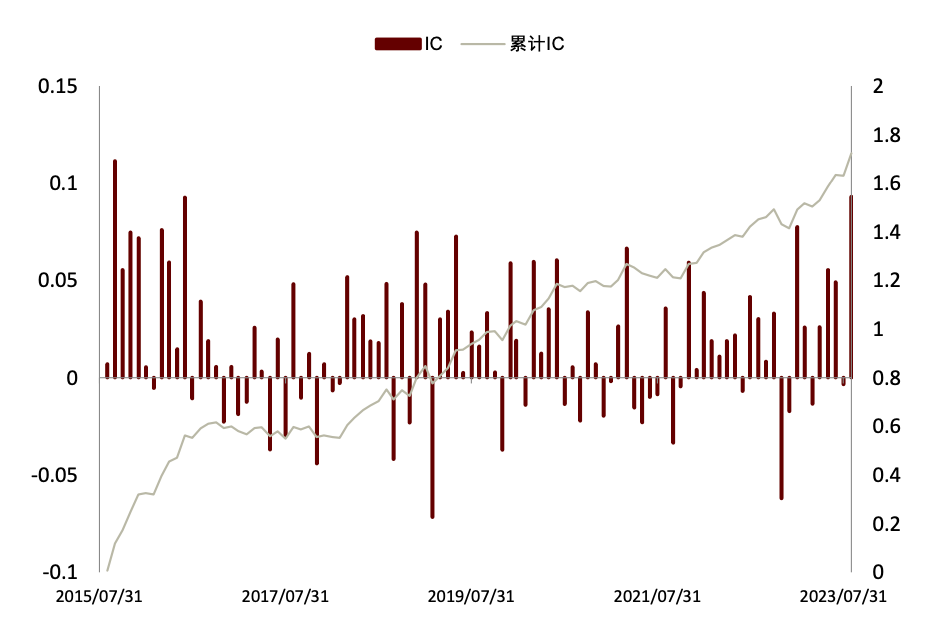
注:数据截至2023-08-31
资料来源:数库,Wind,中金公司研究部
图表23:高信噪比新闻文本因子分组收益表现
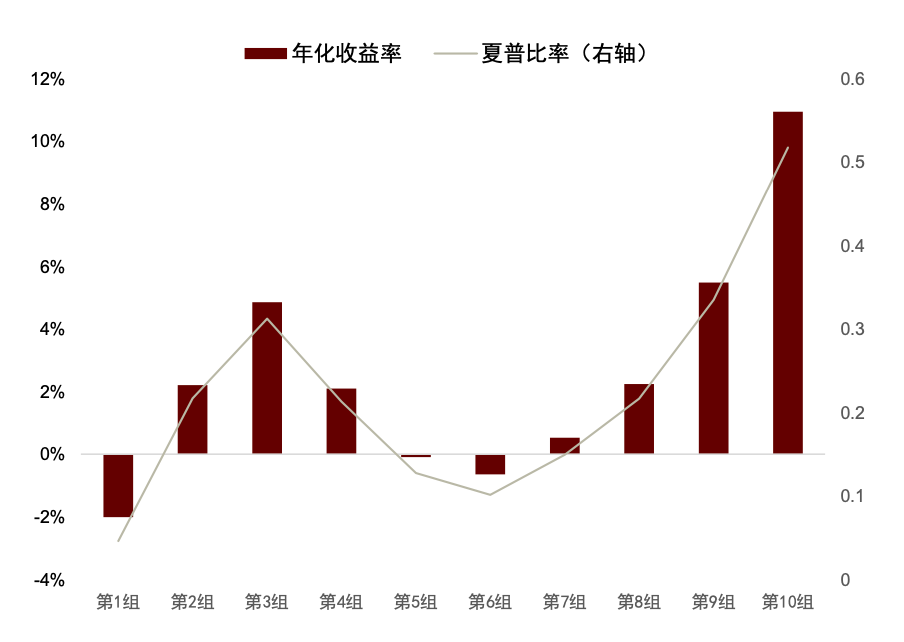
注:测试时段为 2015-07-01 至 2023-08-31
资料来源:数库,Wind,中金公司研究部
图表24:高信噪比新闻文本因子测试结果统计
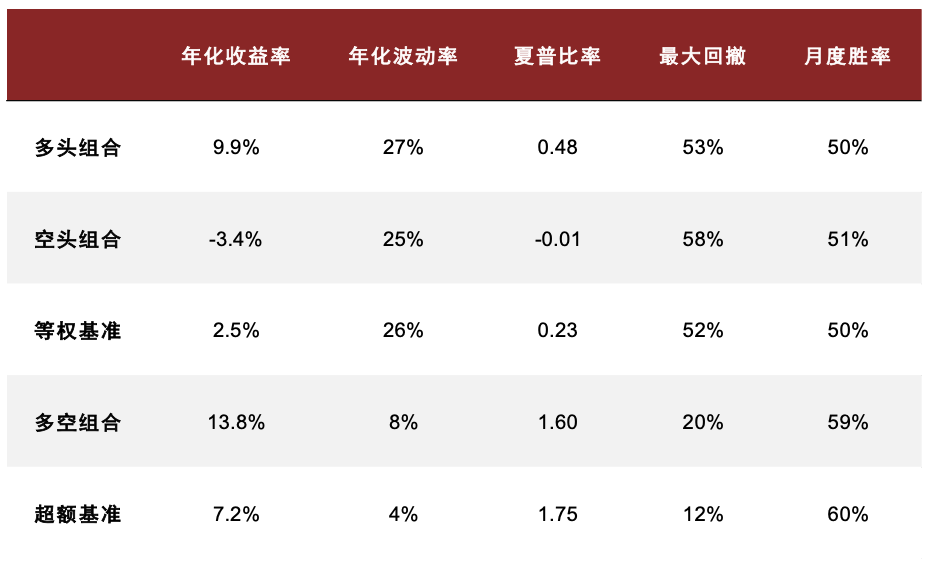
注:测试时段为 2015-07-01 至 2023-08-31
资料来源:数库,Wind,中金公司研究部
图表25:高信噪比新闻文本因子测试结果统计
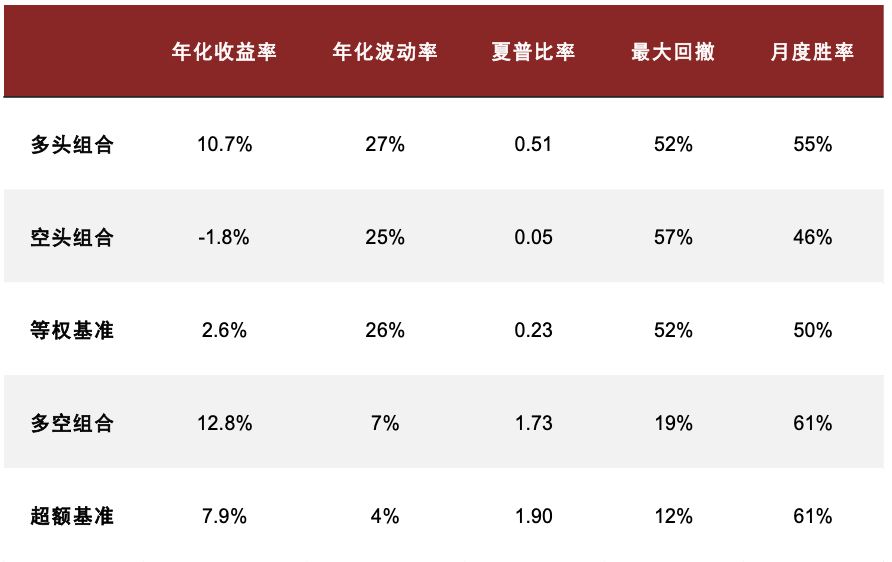
注:测试时段为 2015-07-01 至 2023-08-31
资料来源:数库,Wind,中金公司研究部
新闻 X 情感判别 X 行业轮动
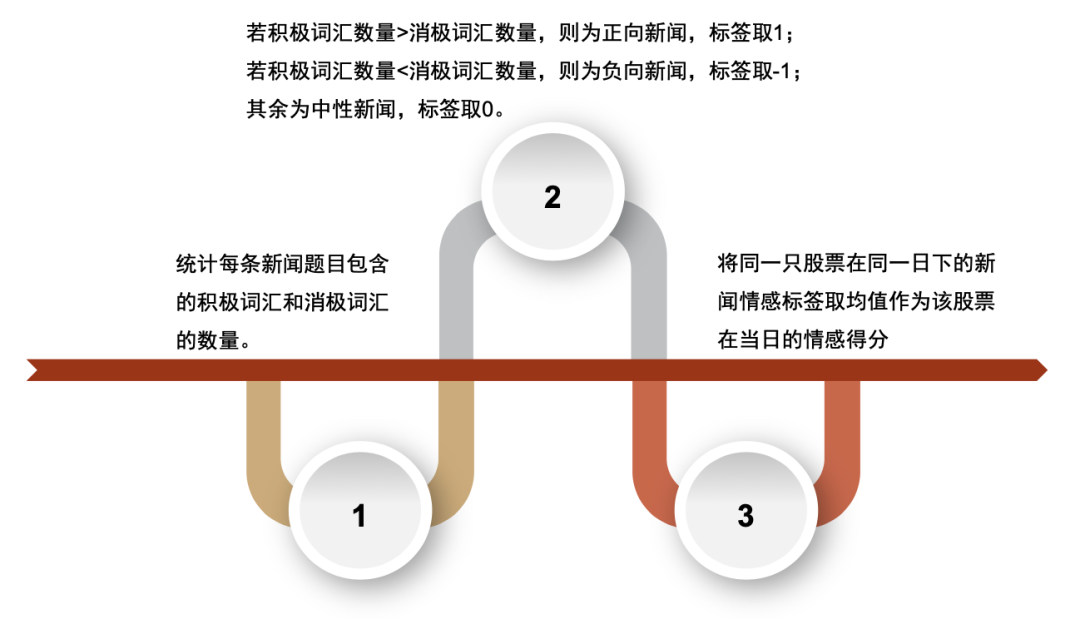
我们首先使用数库在新闻数据中为新闻标记的正负情感作为每条新闻的新闻情感得分,将每支股票每天的情感得分求算术平均,再使用 SAMI 方法将其映射到中信一级行业中。考虑到目前A 股市场中,主流的行业指数编制方式均为成分股自由流通市值加权,因此在行业指标构建过程中,个股数据也按照自由流通市场来加权,得到的行业指标值将更为契合行业指数。我们将这种方式构建的行业指标简称为 SAMI(Stock Alpha Mapping Indicator),该映射方式简称为SAMI 映射。具体映射方式如下。其中𝑤𝑖表示股票 i 在行业中的自由流通市值权重; 𝑎𝑙𝑝h𝑎𝑖表示股票 i 在指标 alpha 上的具体得分或取值。
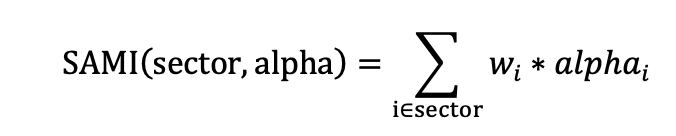
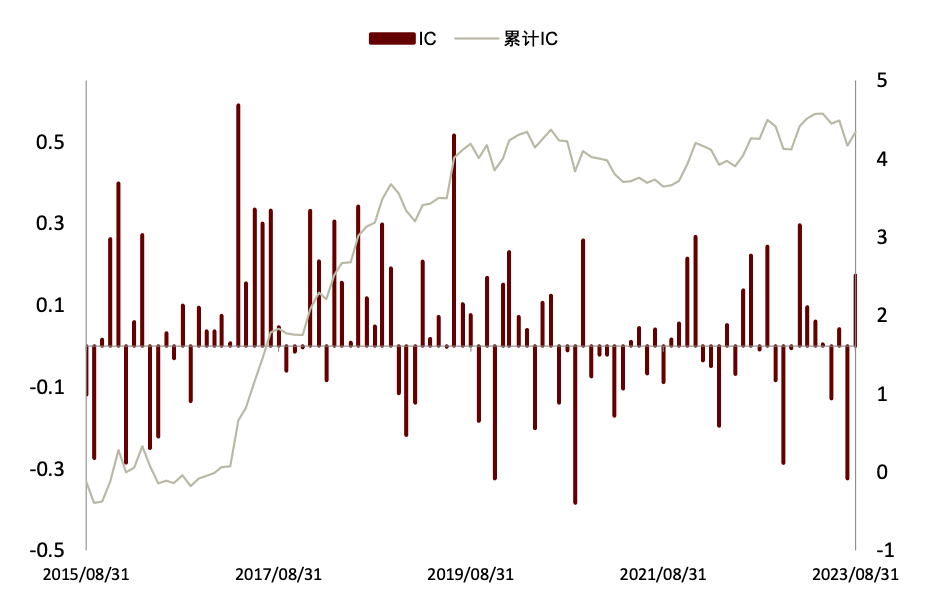
我们使用仅进行 60%相关性和 2 级重要性筛选的新闻文本因子聚合到行业效果如下:IC 均值 为 5.70%,ICIR 为 0.28。通过构建多空策略,买入因子得分最高的一组,卖出因子得分低的一组,得到最近 2016 年以来的收益曲线如图。2016 年来超额基准的年化收益为 9.1%,夏普比率为 1.37,最大回撤为 13%,盈亏比达 1.84。具体构建过程详见《另类数据策略(2)如何优化新闻文本因子》。
图表26:数库新闻数据数量
注:测试截止 2023-08-31
资料来源:数库,Wind,中金公司研究部
图表28:高信噪比新闻文本因子多空与超额净值表现
注:测试时段为 2015-07-01 至 2023-08-31
资料来源:数库,Wind,中金公司研究部
图表29:高信噪比新闻文本因子测试结果统计
注:测试时段为 2015-07-01 至 2023-08-31
资料来源:数库,Wind,中金公司研究部
新闻 X 情感判别 X 行业轮动
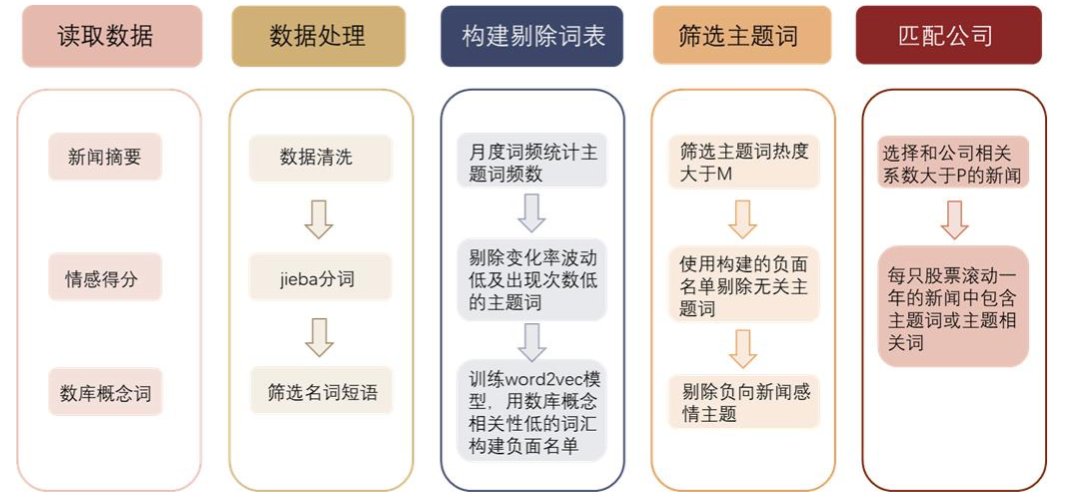
图表30:主题识别步骤
资料来源:中金公司研究部
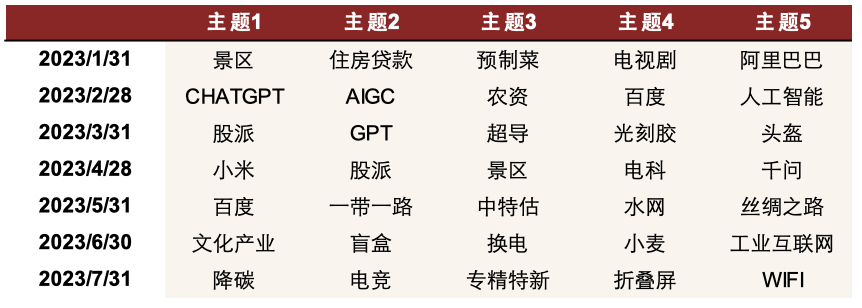
依靠上述方式定期选取热点,并使用一定手段筛选的优质主题股票池具有一定超额收益。具体策略效果和构建方法见《另类数据策略(3):文本信息助力主题投资》。
图表31:2023以来热点主题选取
资料来源:数库,中金公司研究部
分析师研报用于判断主要矛盾
我们使用朝阳永续提供的宏观、策略、固收以及大类资产的全市场分析师报告的摘要部分,通过统计分析师研究报告的摘要中对于不同主题的关心程度来判断当前市场关心的热点问题,进而从中发掘市场当前的主要矛盾。具体报告内容见《量化配置系列(10):如何利用市场主要矛盾辅助大势研判》。
总量研报 X 相似度 X 大势判断
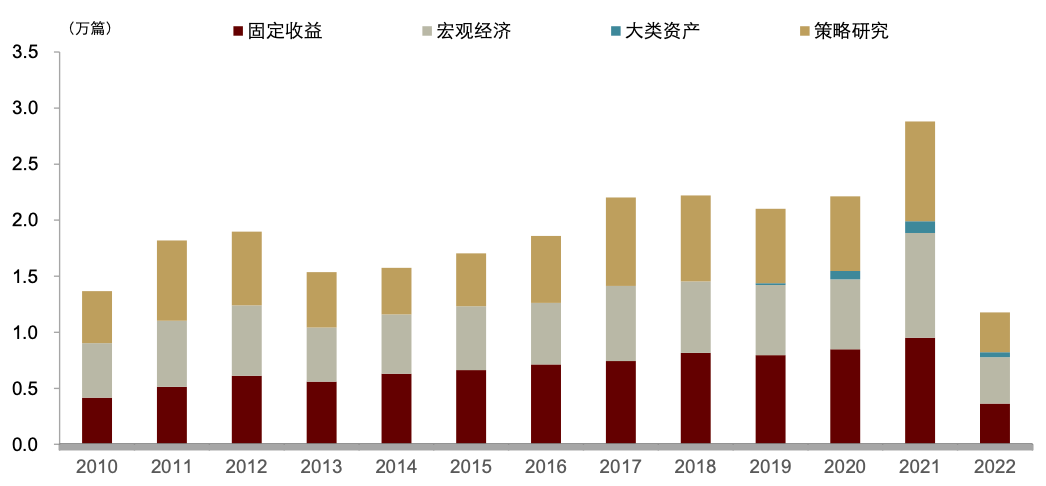
注: 数据截至2022年7月底
资料来源: 中金公司研究部
► 专业性强:观察报告摘要信息,由于其来源均为专业机构分析师,因此文本数据用词专业性更强,核心词更为突出。
► 结构稳定:研究报告通常具有一定格式要求,文本结构较为稳定。同时分析师摘要平均段落长度每段平均包含 800 字以上,内容更为丰富,后续文本处理较为便利。
► 用词规范:分析师研究报告摘要文本规范性较强,用词精准清晰,主题明确规范,易于进行文本解析。但同时由于存在不少的专有名词,导致后期直接使用 jieba默认词库分词带来了数据信息的过度切割并且破坏了专有名词的完整性,因此我们在 jieba分词中加载自己的词库进入分词系统,帮助其自动检索存在的专有名词,提高词语解析效率与准确性。
图表33:国内分析师研报主要矛盾时期划分示例
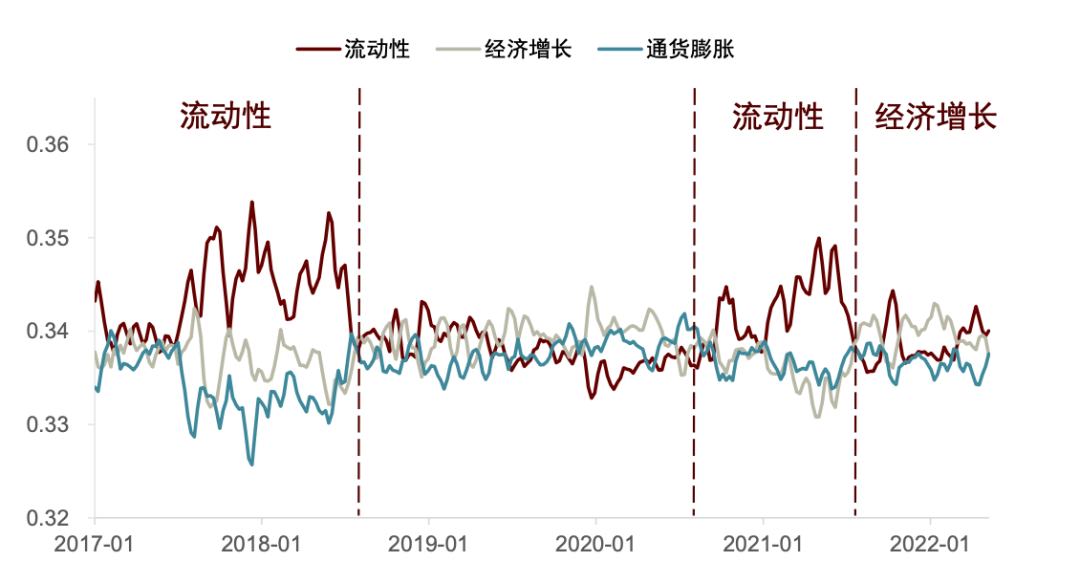
资料来源:朝阳永续, 中金公司研究部
使用研报生成的主要矛盾对A股择时效果有较明显提升。我们继续测试从研报角度得到的主要矛盾,对A股的择时效果。下图展示了 A 股历史回测的净值曲线。2010 年至今,纳入主要矛盾的择时策略可以取得11.96的累计净值,优于通胀维度择时7.37的累计净值,显著强于经济增长、流动性维度的择时净值以及沪深 300 的同期表现。从结果看,纳入研报角度的主要矛盾后,模型对未来A股走势的判断效果有较为显著的提升。
图表34:研报角度的主要矛盾对A股择时效果有较明显提升
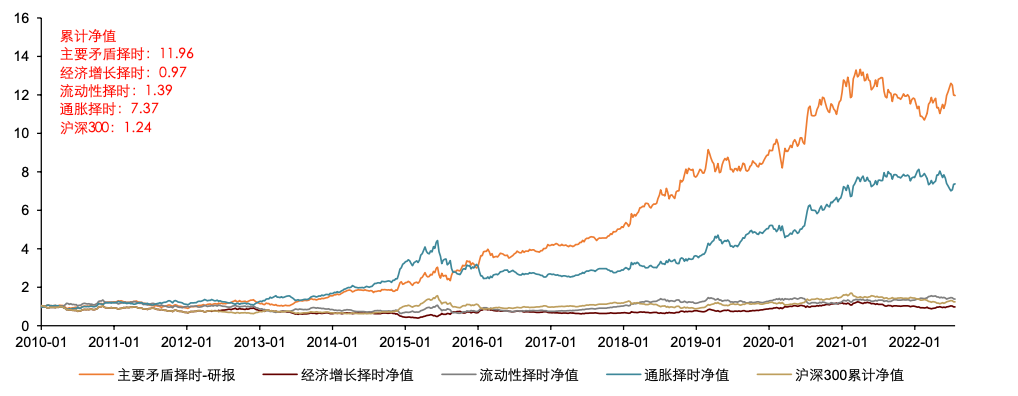
资料来源:Wind, 中金公司研究部
基金定期报告用于大势研判和行业配置
基金报告 X 情感判断 X 大势判断
具体而言,我们的情感分析框架基于如下原则搭建:
► 情感分析:对展望文本进行分词后,我们借助cnsenti库中的sentiment_count 接口,并添加中文金融情感词典(共9228 个词语,其中消极词语共5890词,积极词语共3338词)作为用户情感词典,丰富库中的积极情感与消极情感词汇语料。
► 词频统计: 统计基金年报、中报、季报展望文本中的积极情感词汇,记作 Epositive 。
► 平滑处理:就展望文本而言,季报时效性较好,但数据缺失值较多,而年报和中报数据虽然披露数据量较全,却有着时效性相对较差的问题。因此,我们对数据做平滑处理,基于季报(每年 1 月底、4 月底、7 月底、10 月底)发布时间点,按照时序混合年报和中报(每年3月底、8月底)的积极、消极词汇,从而计算每个季报发布期的积极、消极情绪词频。
► 指数构建:随后,我们依据下式构建积极情绪指数:

► 区间划分:相比于情绪指数的绝对数值,我们更加关注情绪指数的边际变化。因此,我们定义,若当前积极情绪指数的一阶差分大于 0,则下一期为乐观区间,反之,若积极情绪指数的一阶差分小于0,则下一期为悲观区间。
图表35:中文金融情感信息
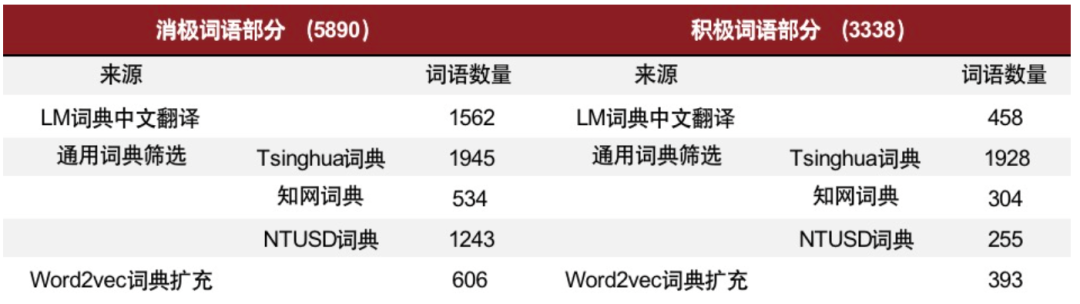
资料来源:姜富伟、孟令超、唐国豪,“媒体文本情绪与股票回报预测”,《经济学(季刊)》,2021 年第 4 期,第 1323-1344 页;中金公司研究部
按照上述步骤,我们得到了 4Q11 至 1Q23 期间,基于基金经理展望文本的乐观与悲观区间划分结果,并与沪深300指数走势进行比对。我们认为,若乐观与悲观区间能够与宽基指数的涨与跌形成较好的对应关系,即可以认为,基于基金经理展望文本得到的市场观点可以预测下一季度权益市场走势。
以季度频率来看,从2Q12 到1Q23,基金经理积极情绪指数对市场涨跌的判断胜率可以达到59%(26/44)。我们观察到在一些重要的历史时点,基于基金经理展望文本得到的乐观与悲观区间,能够与权益市场的实际涨跌呈现出一定的相关性。但是从 2022 年起,由于外围因素、疫情等多方面黑天鹅事件叠加,指标有所失效。
图表36:2012年以来股票市场乐观悲观区间划分
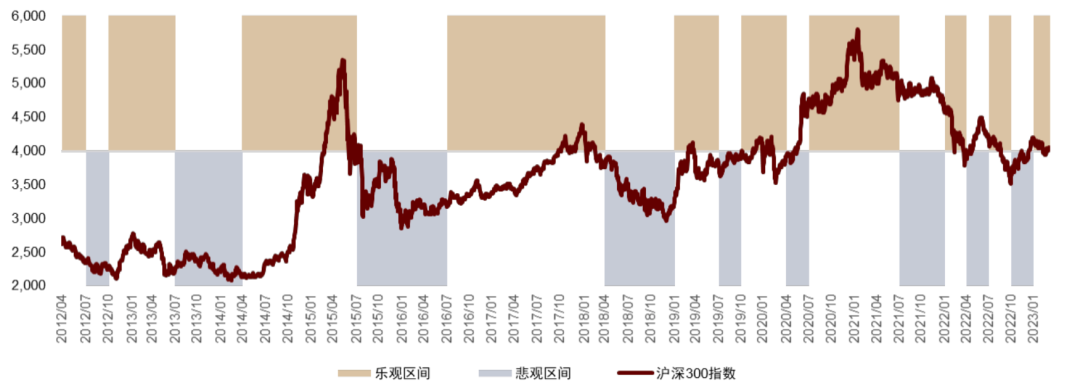
资料来源:Wind,中金公司研究部
基金报告 X 情感判断 X 行业配置
承接上文的乐观与悲观区间划分结果,我们还可以进一步挖掘基金经理展望文本中的行业配置观点。同时我们认为,若将基金经理的择时观点与行业观点相结合,展望文本信息的有效性或能够进一步提升,具体而言,在基金经理预期乐观区间,我们从文本中提取出行业观点可能更倾向于帮助我们找到未来收益弹性较高的行业;而在基金经理预期悲观区间,我们从展望文本中得到的行业则不一定具备非常好的上涨弹性,可能观点偏向于防御与保守。基于上述思想,我们按照如下步骤,检验基金经理展望文本中的行业配置观点是否具有投资指导意义:
► 首先,依据上文的情感分析框架,得到基金经理预期乐观与悲观区间;
► 随后,以年报和中报的行业词频为样本(其中,我们剔除了每期词频小于50 的行业以提高数据的稳定性),计算当期行业词频相对上期的变化率(具体计算原则见第一节的词频变化比例指标 𝑤𝑜𝑟𝑑𝑓𝑟𝑒𝑞𝑐h𝑔 𝑖);
► 最后,按照行业词频变化比例从高到低对行业进行排名,分别得到各期词频变化 Top3 行业组合与 Top5 行业组合,计算报告发布后(3 月末、8 月末)起 20、40、60 交易日内的行业收益率,并与Wind全A指数的同期涨跌幅进行对比。其中,对乐观与悲观区间的行业组合分别统计。
统计结果表明,在乐观区间,展望文本词频变化率 Top5 行业在未来 20 日平均收益率、Top3 行业在未来 40 日平均收益率表现较好,相对 Wind 全 A 指数,前者胜率89%,后者胜率 78%。即使在 2022 年极端行情下,例如2022 年3月31日之后,Top5 行业平均 20 日收益率为-5.34%,Wind 全 A 指数收益率为-8.91%;Top3 行业平均 40 日收益率为-0.82%,Wind 全 A 指数 40 日收益率为-3.44%。
另外,在悲观区间中,我们也对相应的 Top5 行业与 Top3 行业未来收益率均值进行统计,结果表明,从基金经理展望文本中提取出的行业观点难以超越市场,行业平均收益率跑输基准。值得注意的是,我们此处的择时观点与行业观点出现了一定的时间节点错配,即划分乐观与悲观区间的时间节点为 1、4、7、10月末,而获取行业词频的时间节点为3、8月末,因此,我们在依据行业词频变化进行 20、40、60 交易日的后市涨跌统计时,可能出现统计时段超出当期乐观或悲观区间的情况。在这一前提下,报告发布后20交易日涨跌幅的指标可参考性或相对更高。
图表37:乐观区间前五行业与前三行业 20 个交易日平均收益率
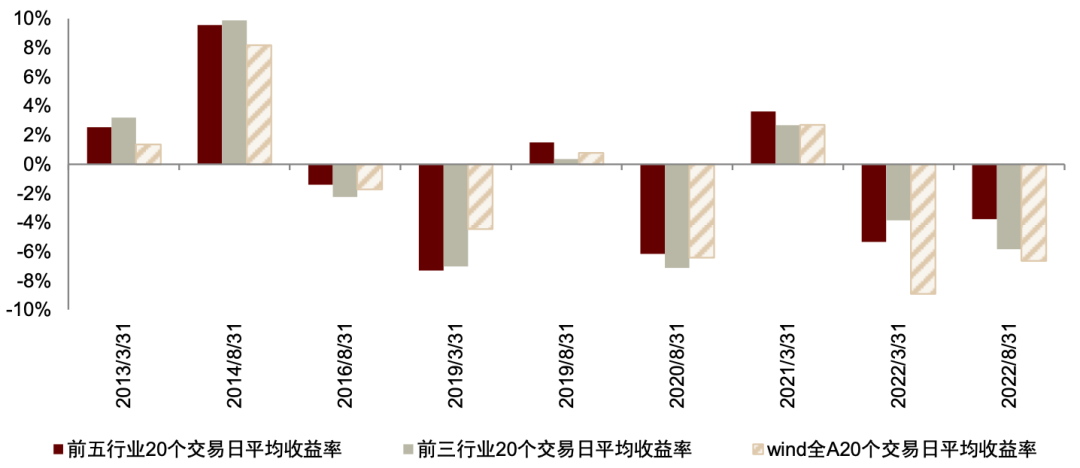
资料来源:Wind,中金公司研究部
图表38:乐观区间前五行业与前三行业 40 个交易日平均收益率
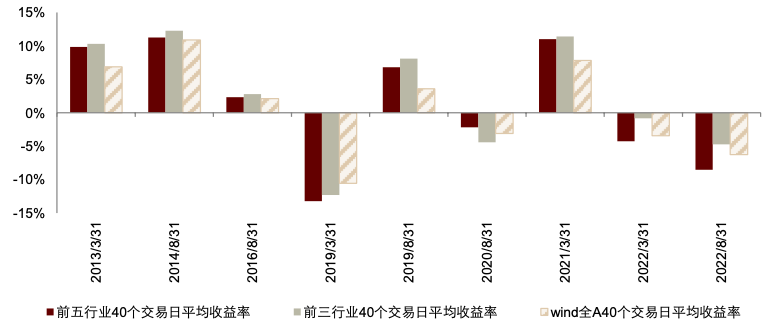
资料来源:数库,Wind,中金公司研究部
图表39:悲观区间前五行业与前三行业收益率统计

资料来源:Wind,中金公司研究部
文本数据的风险与可能性并存
我们展示了已有报告中尝试的文本选股、文本行业轮动、新闻热点主题优选、研报数据判断市场择时、基金定期报告用于大势判断等多种方向,均取得有效表现,应用场景丰富,在这些研究领域的挖掘也较为充分。但相对文本数据本身包含的信息来说这些尝试仍未能完全挖掘文本数据中的全部信息。仅以新闻数据为例,情感判别在选股是文本中最基础的应用方法之一,即使拓展到行业轮动层面,也还有如风格轮动、大势判别等方向可以尝试。此外,新闻数据包含的信息还有大部分不仅上市公司相关联,其他还有诸如地区热点、产品销量等与公司股价间接相关的信息,这些数据的信息含量也往往相当可观。总体而言,文本数据的信噪比较低,但由于其总量较大,因此信息总量可能相比传统数据更高。作为使用另类数据的量化策略的重要开发原料,文本数据的可能性还有待进一步发掘。
Source
文章来源
本文摘自:2023年9月12日已经发布的《另类数据策略(1):文本数据的可能性》
分析员 周萧潇 SAC 执业证书编号:S0080521010006 SFC CE Ref:BRA090
联系人 郑文才 SAC 执证证书编号:S0080121120041 SFC CE Ref:BTF578
分析员 古 翔 SAC 执业证书编号:S0080521010010 SFC CE Ref:BRE496
联系人 曹钰婕 SAC 执证证书编号:S0080122030141
分析员 宋唯实 SAC 执证证书编号:S0080522080003 SFC CE Ref:BQG075
联系人 李钠平 SAC 执证证书编号:S0080122070045
分析员 胡骥聪 SAC 执业证书编号:S0080521010007 SFC CE Ref:BRF083
分析员 刘均伟 SAC 执业证书编号:S0080520120002 SFC CE Ref:BQR365
Legal Disclaimer
法律声明

本篇文章来源于微信公众号: 中金量化及ESG