“海量”专题(236)——深度学习因子的“模型动物园”
重要提示:《证券期货投资者适当性管理办法》于2017年7月1日起正式实施,通过本微信订阅号发布的观点和信息仅供海通证券的专业投资者参考,完整的投资观点应以海通证券研究所发布的完整报告为准。若您并非海通证券客户中的专业投资者,为控制投资风险,请取消订阅、接收或使用本订阅号中的任何信息。本订阅号难以设置访问权限,若给您造成不便,敬请谅解。我司不会因为关注、收到或阅读本订阅号推送内容而视相关人员为客户;市场有风险,投资需谨慎。
01
深度学习因子的“模型动物园”
那么,基于其他类别深度学习模型训练得到的因子是否具有显著的周度选股能力?与系列前期专题报告提出的双向AGRU(下简称BiAGRU)模型相比,两者的差异又有多少?为了回答这些问题,本章在保持输入特征、预测目标和训练设定一致的前提下,测试不同的深度学习模型训练所得因子的周度选股能力。具体设定请参考本系列前期的专题报告——《选股因子系列研究(八十八)——多颗粒度特征的深度学习模型:探索和对比》。由于笔者算力有限,本文仅使用日颗粒度的特征训练模型。
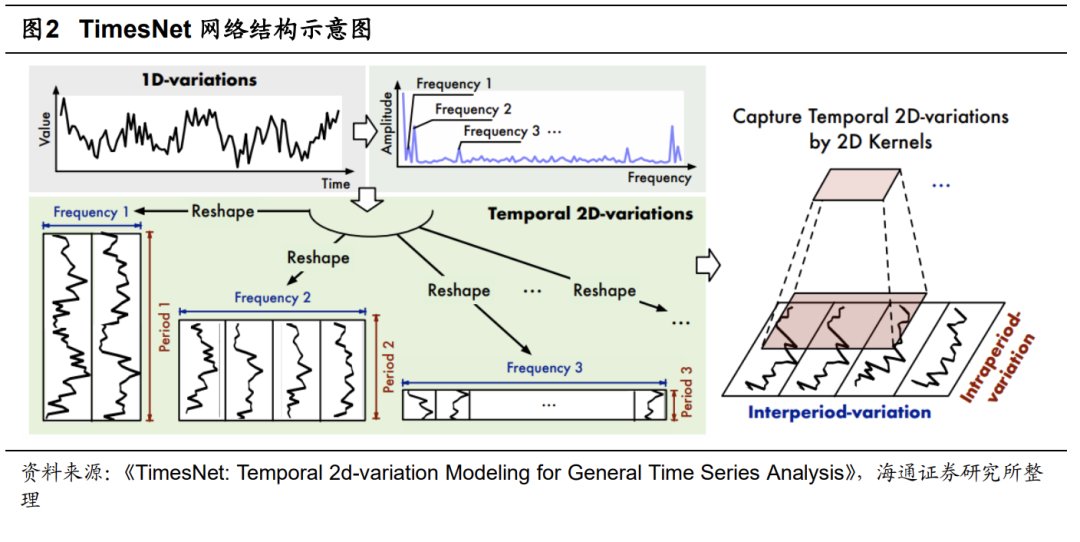
由于卷积类模型可有效捕获和学习局部特征,因此,我们对时间序列数据使用该类模型,捕捉股票特征序列中的短期趋势、周期性变化或局部模式。在众多卷积类模型中,本节重点测试TCN和TimesNet两种网络结构。
TCN(Temporal Convolutional Network)简称时域卷积网络,是一种专门针对时间序列数据设计的深度学习模型。结构源于卷积神经网络(CNN),但在处理序列数据时表现出了独特的优势。
TCN使用一维卷积层来捕捉时间序列中的局部依赖关系,并确保当前输出只依赖于过去的输入,即满足因果性要求,这对未来时间点的预测至关重要。通过使用空洞卷积技术,TCN可以在不增加计算复杂度的情况下,捕获更长时间跨度内的依赖关系,适合时间序列预测。此外,TCN还借鉴了ResNet等网络的成功经验,采用残差连接机制以解决深度网络训练过程中的梯度消失问题,使得网络可以构建得更深、表达能力更强。
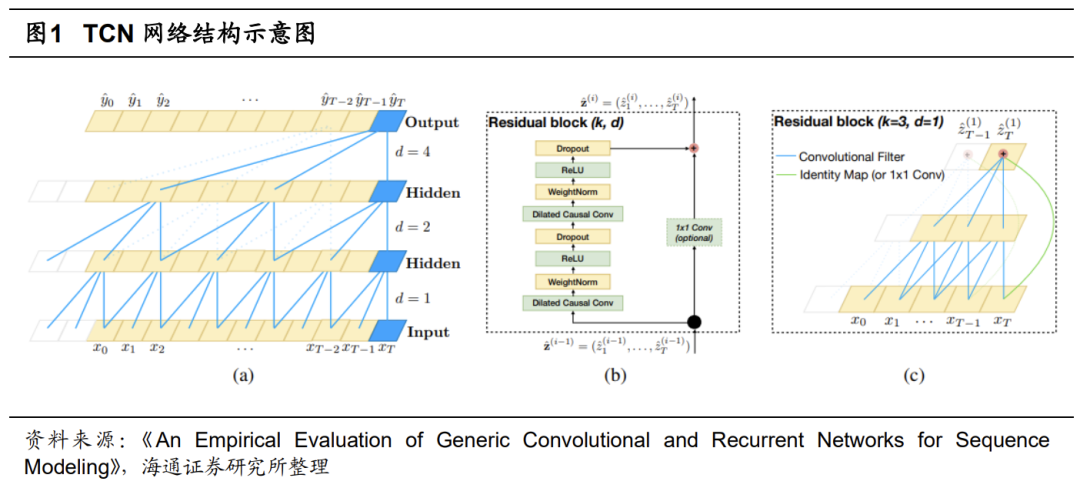
TimesNet是由清华大学研究团队开发的时序卷积类模型。它创新地将一维时间序列转换为二维空间表示,并运用特殊的网络结构来捕捉和提取时序数据中隐藏的数据变化规律。利用傅里叶变换和时空卷积模块,TimesNet能够深入挖掘时间序列中的内在关联和结构性信息,从而提升预测性能和准确性。
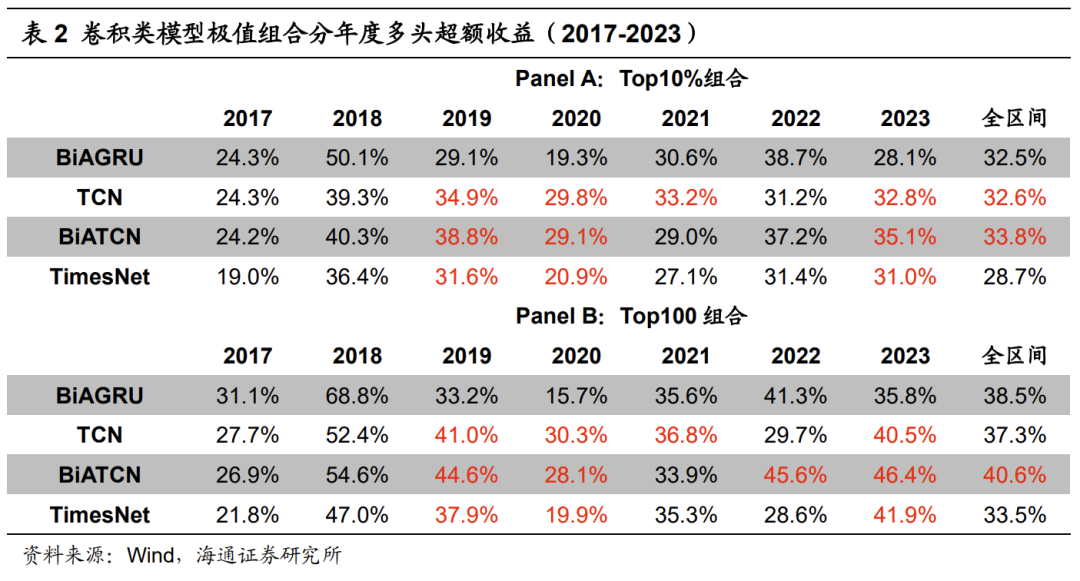
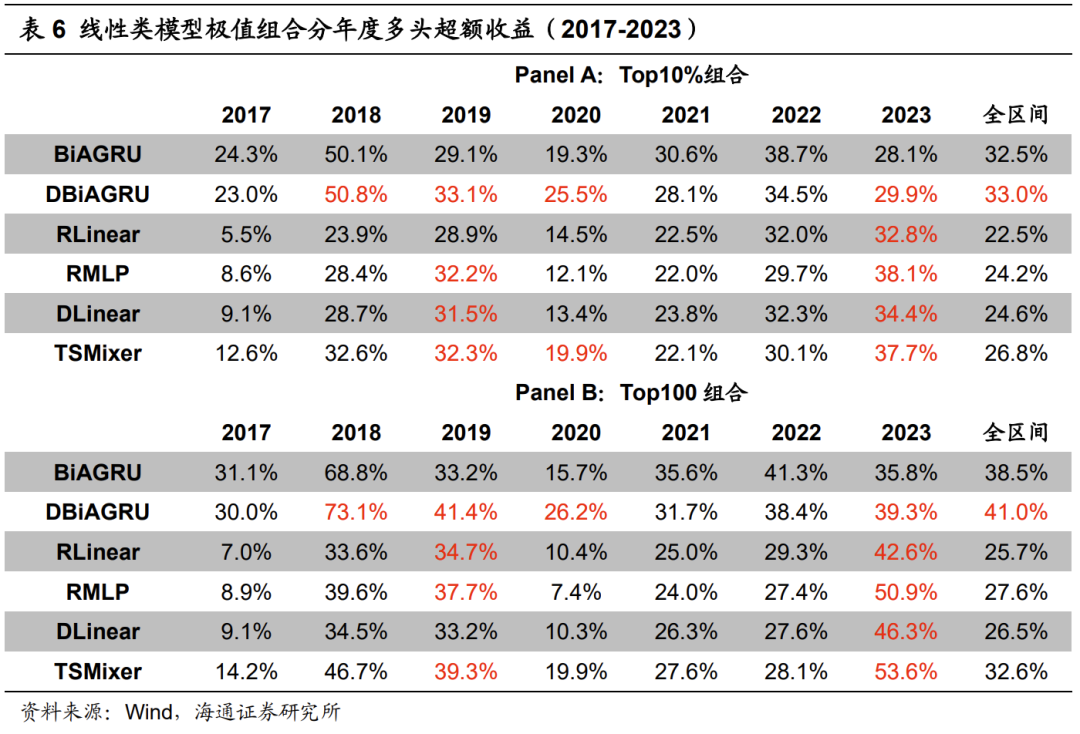
下表展示了基于卷积类模型训练得到的因子的周度选股能力。其中,BiATCN为叠加双向学习与注意力机制的TCN模型。
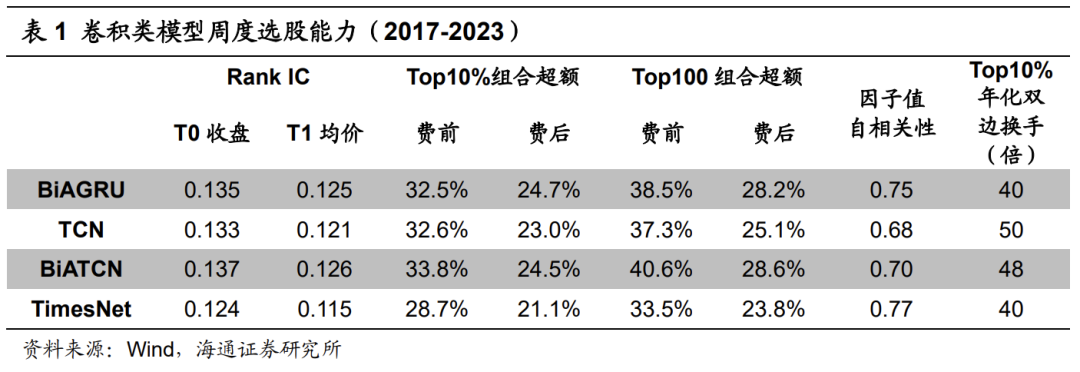
测试结果表明,卷积类模型呈现出显著的周度选股能力。其中,TCN类模型较优,因子周均Rank IC、极值组合(即Top10%和Top100组合,下同)超额收益与BiAGRU模型接近。BiATCN模型周均Rank IC为0.137,Top10%组合年化超额收益33.8%。但需要注意的是,TCN类模型的周度换手率较高,因子周均自相关性较低,Top10%组合年化双边换手40倍。BiATCN模型为48倍,明显高于BiAGRU模型的40倍。
下表展示了卷积类模型极值组合的分年度多头超额收益。2018年,卷积类模型大幅跑输BiAGRU模型,超额收益落后10%以上。在卷积类模型中,TCN类模型表现相对更好。2019-2021年及2023年,相对BiAGRU模型都能取得更高的超额收益。对比TCN模型与BiATCN模型可见,双向学习与注意力机制的引入,都可进一步提升模型在2018-2019年和2022-2023年的超额收益。
Transformer在2017年由Google提出,它最初被设计用于自然语言处理,并在机器翻译任务上取得了较大的成功。Transformer的核心特点是采用自注意力机制来捕获序列数据中的长期依赖关系。在时间序列预测方面,自注意力机制允许模型关注序列中任意两个时刻之间的相互影响,而不是局限于局部或近期历史信息。这些特性对于捕捉时间序列数据中的非线性、周期性和长期趋势非常有效。
系列前期报告中提出的BiAGRU就引入了这一机制,取得了较好的效果。近年来的一些研究表明,在适当改造后,Transformer及其变体在某些时间序列预测场景下可以大幅超越常规RNN类模型。在众多Transformer类模型中,本节重点测试Transformer、Informer和PatchTST三种网络结构。
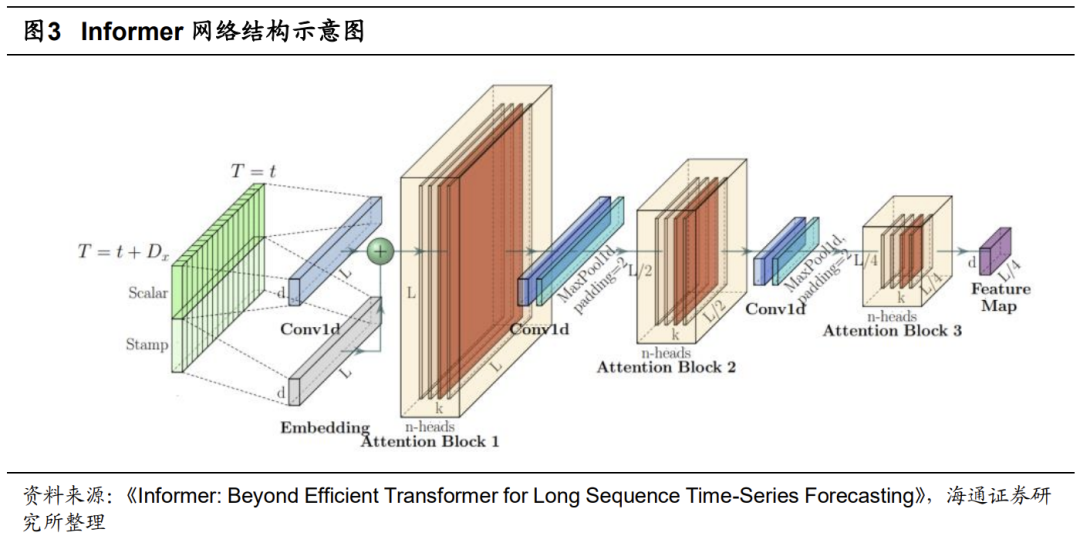
相比于经典的Transformer架构,Informer进一步引入时序编码、ProbSpare自注意力机制和蒸馏机制,进一步提升了Transformer类模型在时间序列预测问题上的效率和效果。该模型的网络结构示意图如下所示。
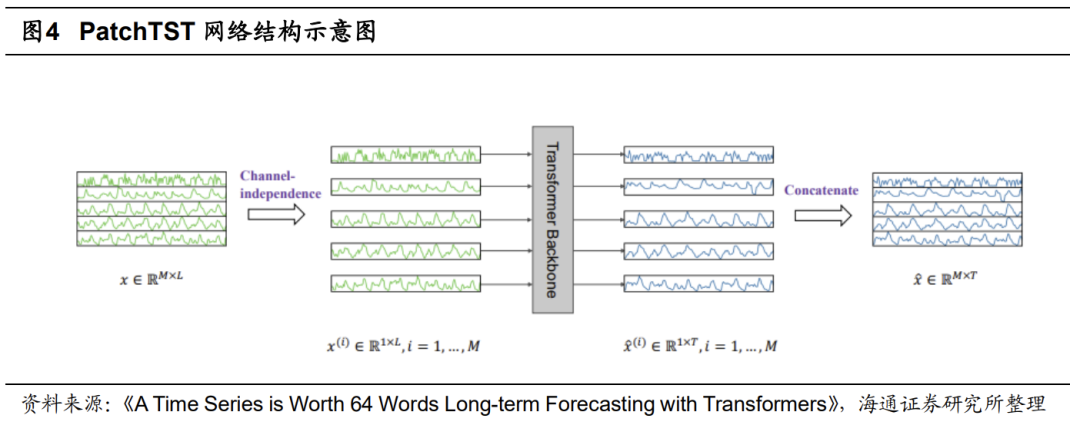
PatchTST在Transformer类模型的基础上,进一步引入通道独立和Patch划分的特性,利用独立通道高效地处理包含多个变量的时间序列数据。其中,每个变量被视为一个独立的通道。模型独立处理每个通道中的数据,并通过参数共享的方式,学习不同变量之间的交互关系。
此外,PatchTST借鉴了图像处理中,对图片进行Patch划分的方式,将时间序列数据分割成小的时间片段或窗口,即,Patch。这些Patch随后被输入Transformer主干网络中,进行信息提取。而且,PatchTST提供了两种训练模式,既可以采用有监督的方式直接根据历史数据预测未来值,也可以采用自监督方式从数据中自我学习潜在结构和规律,提升模型泛化能力。
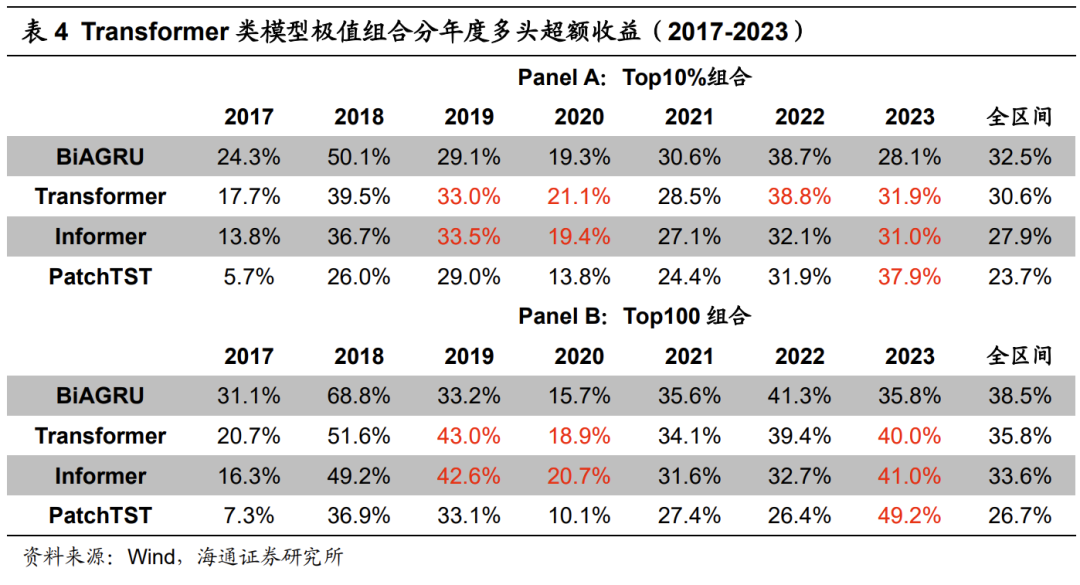
下表展示了基于Transformer类模型训练得到的因子的周度选股能力。从中可见,Transformer类模型同样有着显著的周度选股能力,但是依旧小幅弱于BiAGRU模型。对比不同的Transformer类模型,Transformer周度选股能力最强,Informer次之,PatchTST相对较弱。Transformer模型周均Rank IC为0.129,Top10%组合年化超额收益30.6%。
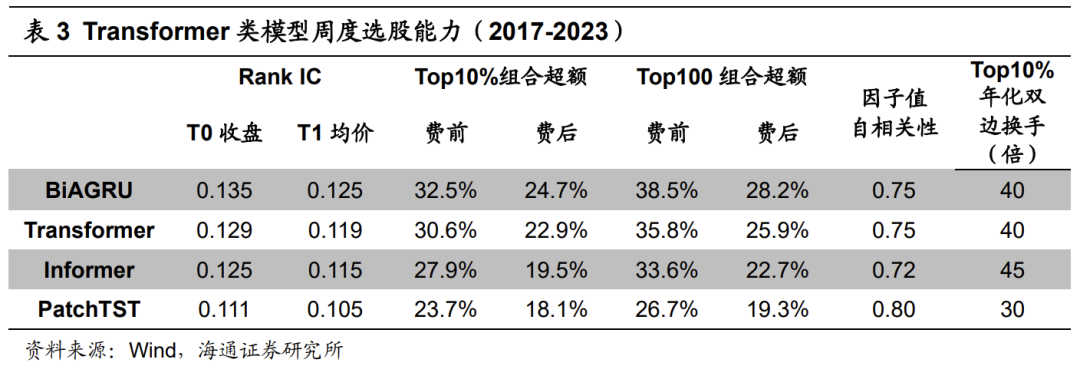
从下表的分年度表现看,Transformer和Informer模型在2019、2020和2023年皆取得更高的超额收益,而PatchTST仅在2023年有更强的超额收益。与卷积类模型类似,Transformer类模型2018年均明显跑输BiAGRU模型,极值组合超额收益落后10%以上。
近年来,除RNN类、卷积类和Transformer类外,线性类模型也开始被用于时间序列预测任务中。和其他类别模型相比,线性类模型的最大特点是结构简单、参数量少。而且,在部分时间序列预测任务上,线性类模型也呈现出不输于其他类别模型的效果。本节重点测试DLinear、RLinear、RMLP和TSMixer四种网络结构。
DLinear模型将时间序列分解为趋势序列和残差序列,然后使用两个单层线性网络分别对这两个序列建模,以完成预测任务。RLinear和RMLP模型的思路相同,但是在输入处理上更加简单,本文不再赘述。借鉴DLinear对输入特征的处理模式,可进一步构建DBiAGRU模型。
TSMixer借鉴计算机视觉领域中的MLP-Mixer架构,有效捕获了时序数据中蕴含的时间模式和交叉变量信息。TSMixer通过应用类似于MLP-Mixer的设计思路,引入时序混合层(Temporal Mixing)和特征混合层(Feature Mixing)。前者融合同一变量在不同时间步长上的特征,以捕捉时序依赖关系;而后者则跨越变量在同一时间点上融合信息,揭示特征间的相互作用。
下表展示了基于线性类模型训练得到的因子的周度选股能力。从中可见,线性类模型同样有较为出色的周度选股能力,但也明显不及BiAGRU模型。其中,TSMixer的周度选股能力最强,DLinear和RMLP次之,RLinear较弱。TSMixer周均Rank IC为0.122,Top10%组合年化超额收益26.8%。此外,在引入DLinear对于输入特征的进行处理后,DBiAGRU的极值组合超额收益小幅提升。
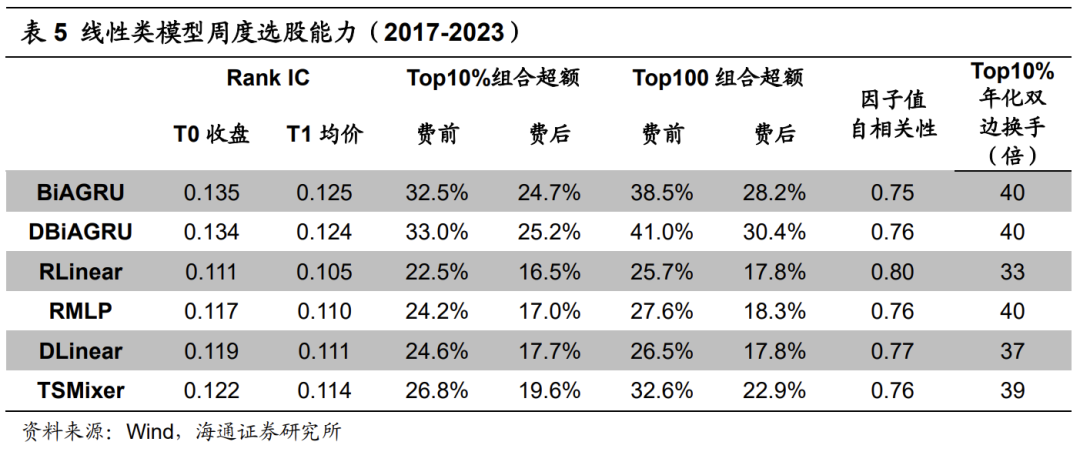
从下表的分年度表现看,线性类模型在2017-2018年显著弱于BiAGRU模型,Top10%组合多头超额收益的落后幅度超过15%。而RMLP、DLinear和TSMixer模型仅在2021和2023年有更高的多头超额收益。
本章在控制模型输入特征、预测标签、训练设定的前提下,对比基于不同深度学习模型训练所得因子的周度选股能力。根据我们的测试,卷积类模型最强、Transformer类模型次之、线性类模型较弱。其中,BiATCN模型、TCN模型、Transformer模型表现较好。此外,使用输入特征分解处理的DBiAGRU模型也有较为显著的周度选股能力。但我们认为,上述结论并不具备很强的迁移性。由于模型效果受到多方面因素的影响,部分模型在当前测试中效果偏弱,也可能是笔者对超参数、输入特征或预测/调仓频率的设定导致的。投资者可在实际应用中,根据自身需求对模型进一步调优。
02
“模型动物园”内的对比与集成
首先,我们考察不同模型训练所得因子的截面相关性。如下表所示,各模型之间的相关性整体较高,线性相关系数均处于0.7-0.8的范围内。而同一类别内,不同细分网络结构之间的相关性更是接近或高于0.85。我们认为,这些结果也较为符合直观认知。虽然各模型的网络结构及其特性存在较大差异,但共同点是,都具有很强的拟合能力。当输入特征、预测标签和训练设定均相同时,模型完全有可能得到相似的因子。
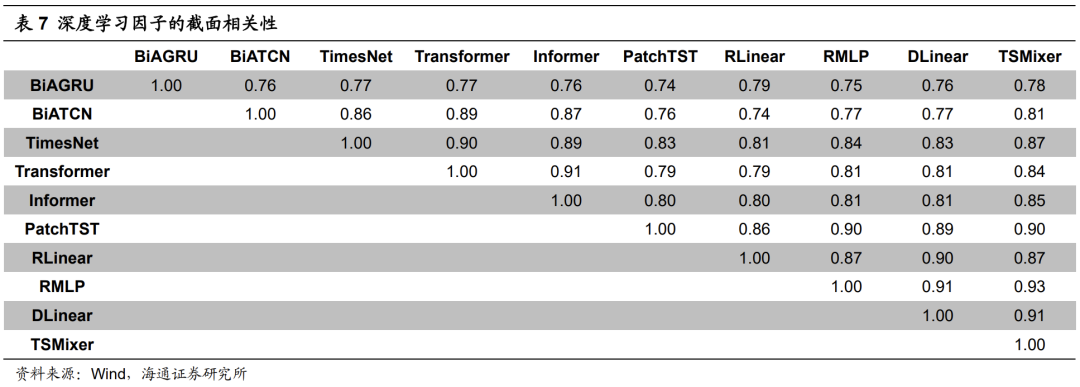
尽管相关性不低,各个模型的Top10%组合历年的多头超额收益(表8)和BiAGRU相比,依旧有一定的差异,大部分年份也是互有高低。但2017和2018两年,却是BiAGRU模型全面优于其余模型。那么,是什么原因导致了这一结果呢?我们认为,不同模型对量价信息的学习和调整速度不一致,使得它们在特定时段的表现出现分化。
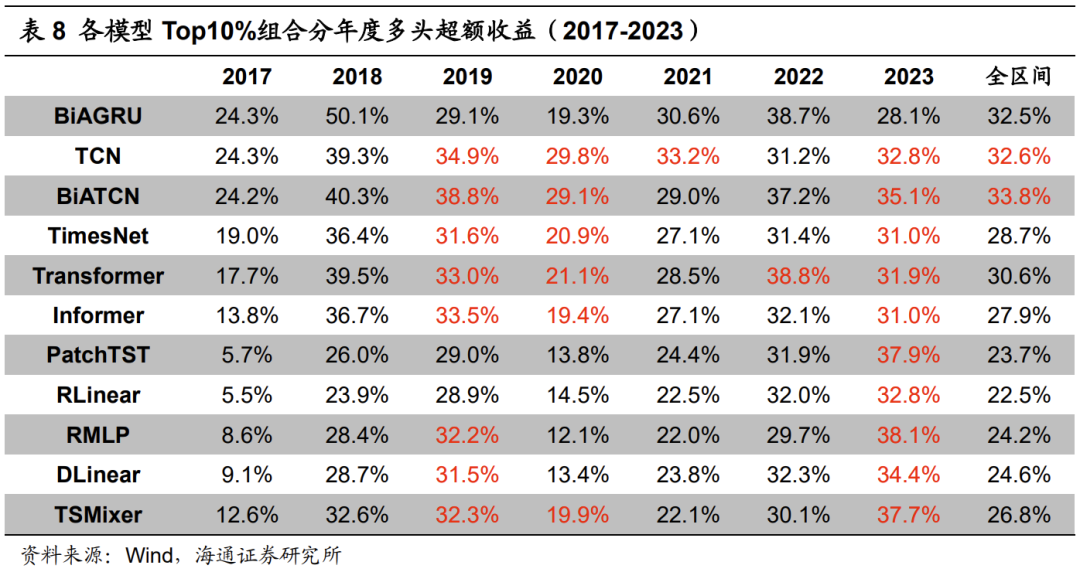
以2018年为例,下图展示了不同模型的Top10%组合与BiAGRU模型的相对强弱净值走势。不难发现,所有模型都是在上半年显著、持续地跑输BiAGRU模型。但经过2018年6月的迭代后,各模型在下半年都可以跑平、甚至小幅跑赢BiAGRU模型。
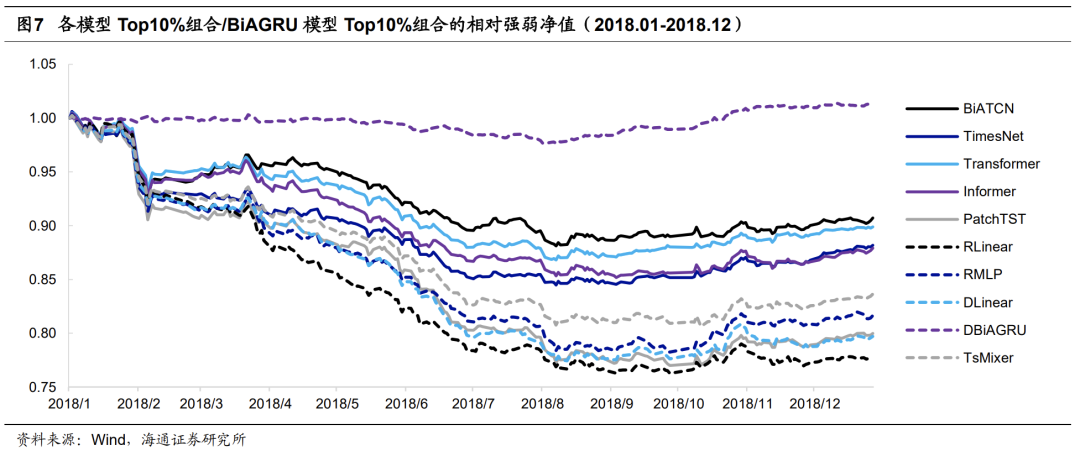
我们通过计算各模型与常规低频量价因子之间的相关性,来推断模型对量价信息的学习模式。当然,由于模型的输入特征同时包含低频和高频量价信息,因此终端因子并不仅仅由低流动性、反转和低波动驱动。但为了讨论方便,我们只计算模型在2017年12月和2018年6月分别迭代更新后,与这三个因子的相关性。
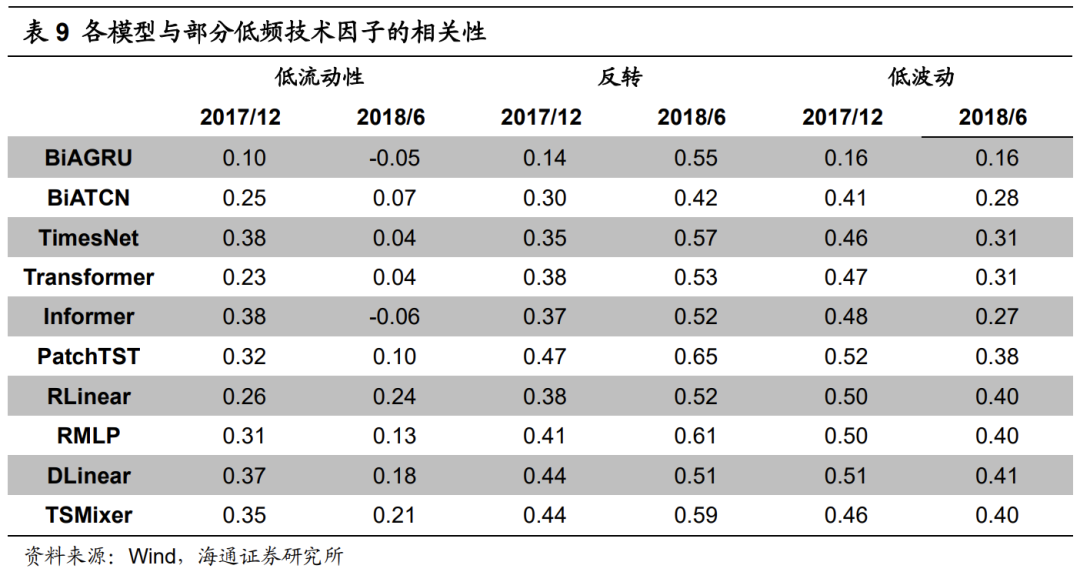
由上表可见,2017年12月更新后,BiAGRU模型与低流动性和反转因子的相关性已大幅低于其他模型。而观察下图可以发现,这两个因子的多头超额收益皆在2018年上半年出现一定幅度的回撤。这使得那些尚未在两者上降低相关性的模型,显著跑输BiAGRU模型。
2018年6月更新后,所有模型和反转因子的相关性较为接近。与此同时,其余模型和低流动性、低波动因子的相关性高于BiAGRU模型。2018年下半年,这三个因子的表现较为优异,推动其余模型得到的深度学习因子的超额收益跑赢(平)BiAGRU模型。
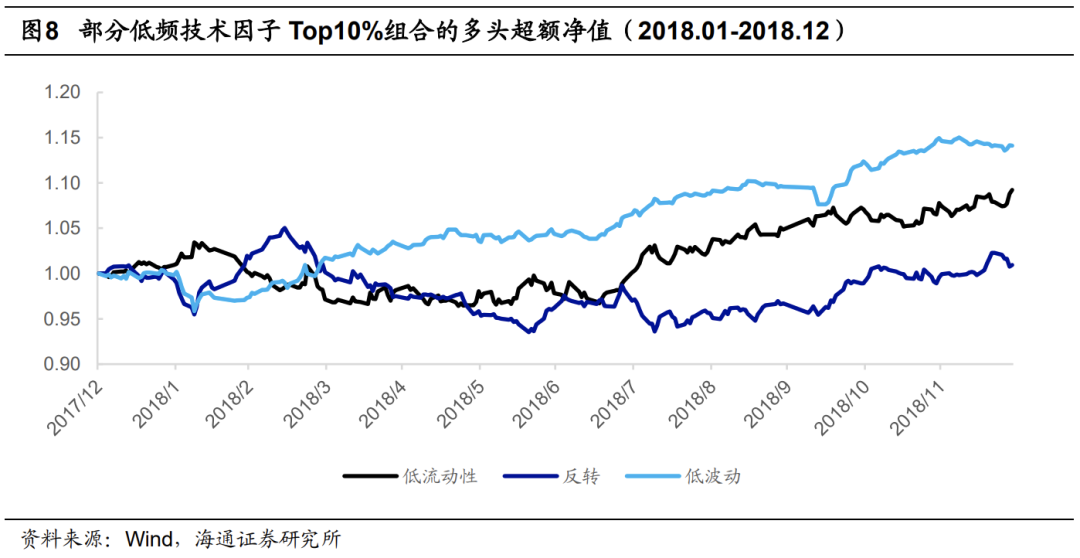
由此可见,模型因网络结构、超参数选择等因素的差异,对量价信息的学习和调整速度并不一致,使得极值组合的年化超额收益虽然接近,但在某一时段内的表现却大相径庭,这就给单一模型的使用带来了很大的不确定性。
为了构建更加稳健的深度学习因子,我们可集成不同模型训练得到的因子。考虑到因子之间较高的截面相关性,我们采用最简单的等权方式。下表展示了部分集成模型的因子周度选股能力。为了方便表述,我们将BiAGRU与其他模型的等权集成简写为+XXX模型。例如,BiAGRU与BiATCN的等权集成模型可简写为+BiATCN模型。
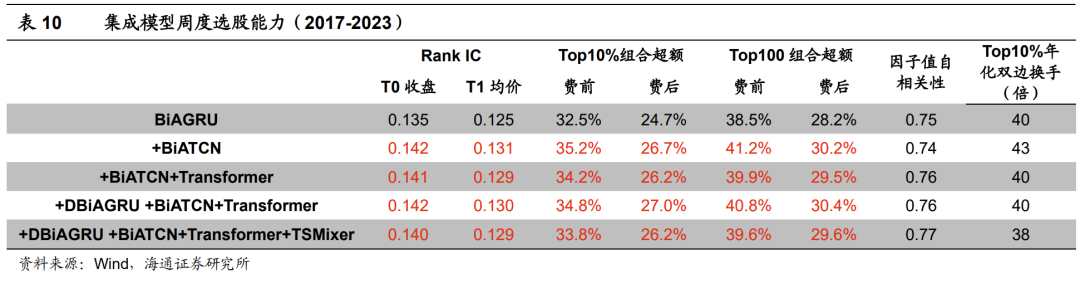
由上表可见,BiAGRU模型叠加BiATCN或Transformer后,因子表现得到进一步提升。周均Rank IC在0.14以上,Top10%组合和Top100组合的年化超额收益分别为34%和40%左右。综合来看,+BiATCN模型和+BiATCN+Transformer模型的周度选股能力更强。
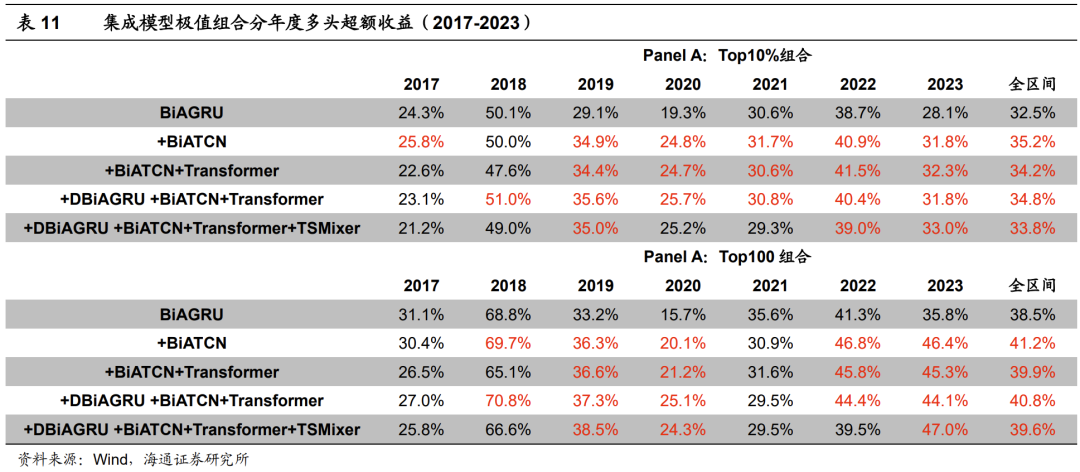
从下表的分年度超额收益可见,2019-2023年期间,集成模型大概率优于BiAGRU模型。其中,+BiATCN、+BIATCN+Transformer和+DBiAGRU+BiATCN+Transformer表现相对更好。较为明显的例外是2021年,集成模型的Top100组合均弱于BiAGRU模型。
03
基于模型集成的AI增强组合
我们以中证500和中证1000增强组合为例,将各集成模型训练得到的因子作为收益预测,考察它们在指数增强组合中的应用效果。
考虑到成分股约束对增强组合的收益有一定影响,本文分别测试全市场选股和80%指数成分内选股的两个增强组合的业绩表现。其中,风控模块包括以下几个方面的约束。
1) 个股偏离:相对基准的权重偏离不超过0.5%;
2) 因子暴露:估值中性、市值中性,常规低频因子:[-0.5, 0.5];
3) 行业偏离:中信一级行业中性;
4) 选股空间:全市场/80%指数成分股权重;
5) 换手率:单次单边换手不超过30%。
组合的优化目标均为最大化预期收益,目标函数如下所示。
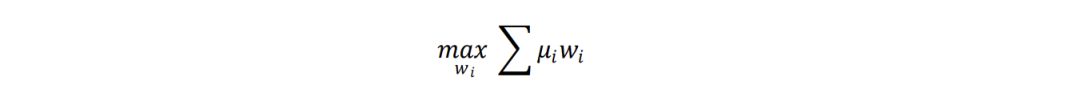
其中,wi为组合中股票i的权重,μi为股票i的预期超额收益。为使测试结果贴近实践,下文的测算均假定以次日均价成交,同时扣除双边3‰的交易成本。
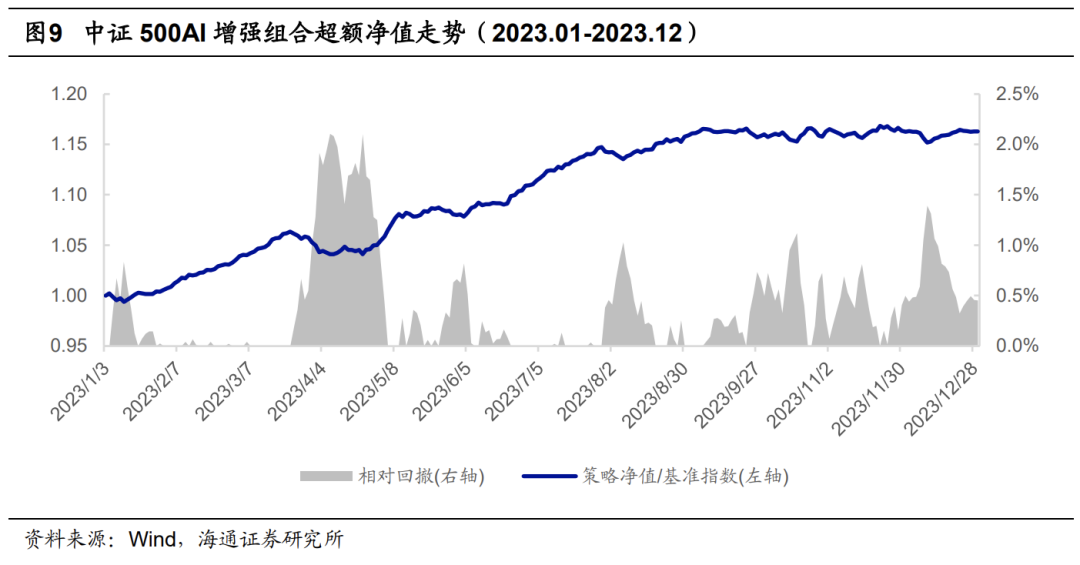
下表展示了使用不同集成模型构建得到的增强组合的超额收益。全市场选股的中证500增强组合的年化超额收益从16.5%提升至17.4%-18.5%;全市场选股的中证1000增强组合年化超额收益从22.5%提升至24.3%-25.1%,80%成分股约束的中证1000增强组合年化超额收益从20.0%提升至20.5%-21.4%。其中,+BiATCN和+BiATCN+Transformer模型的超额收益相对更高。
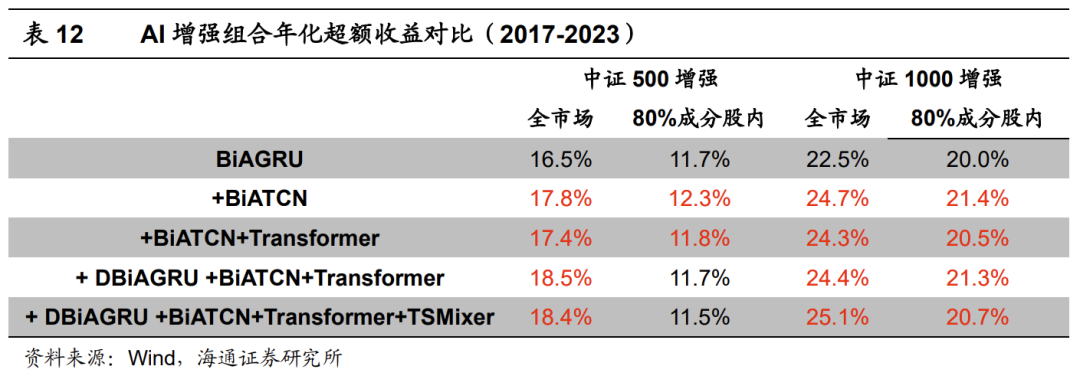
下表为+DBiAGRU+BiATCN+Transformer模型对应的全市场中证500 增强组合的分年度收益风险特征。2017年以来,组合年化超额收益18.5%,超额最大回撤4.0%,发生在2021年。分年度来看,2019和2021年表现相对较弱,2023年超额收益14.9%。
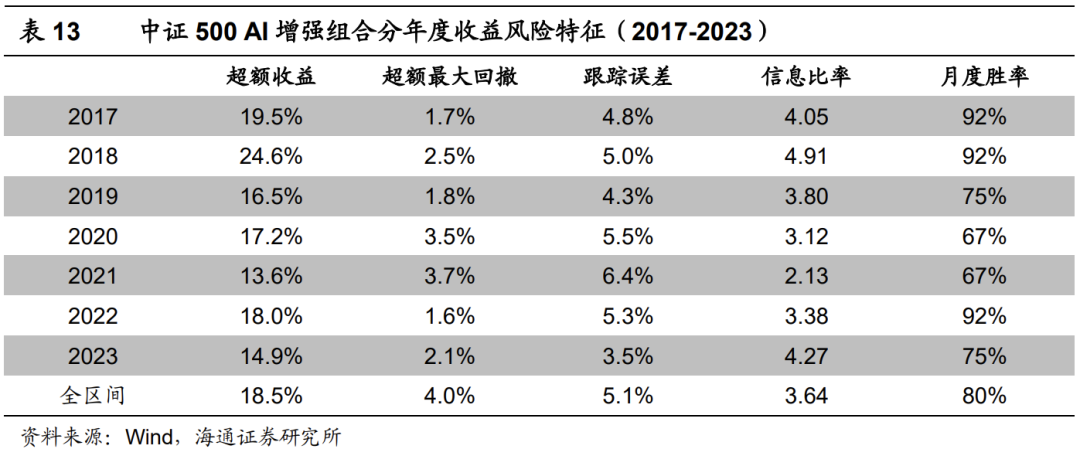
下图展示了该组合2023年以来的超额收益净值走势,区间超额最大回撤发生在2023年3月底至4月中旬,幅度略高于2%,其余时间的回撤均不超过1.5%。
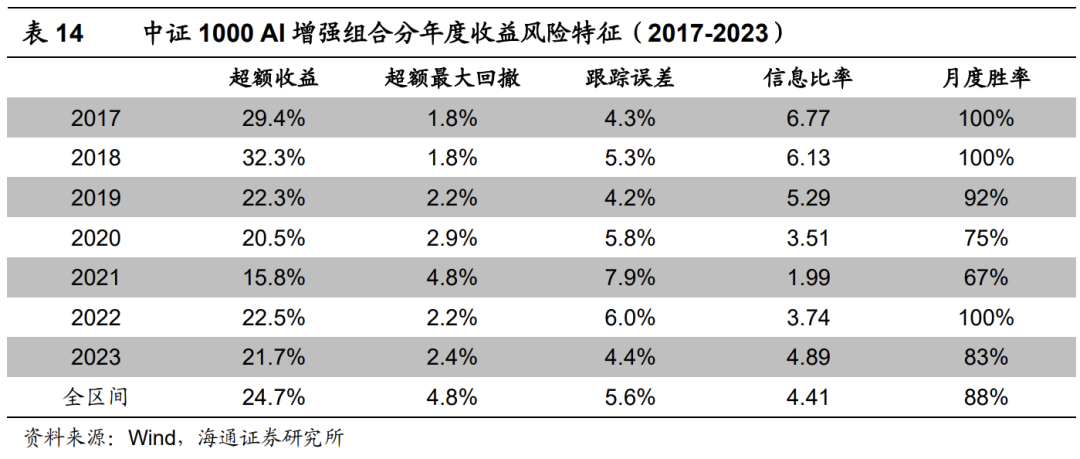
下表为+BiATCN模型对应的全市场中证1000增强组合的分年度收益风险特征。2017年以来,组合年化超额收益24.7%,超额最大回撤4.8%,发生在2021年。分年度来看,2020和2021年表现相对较弱,2023年超额收益21.7%。
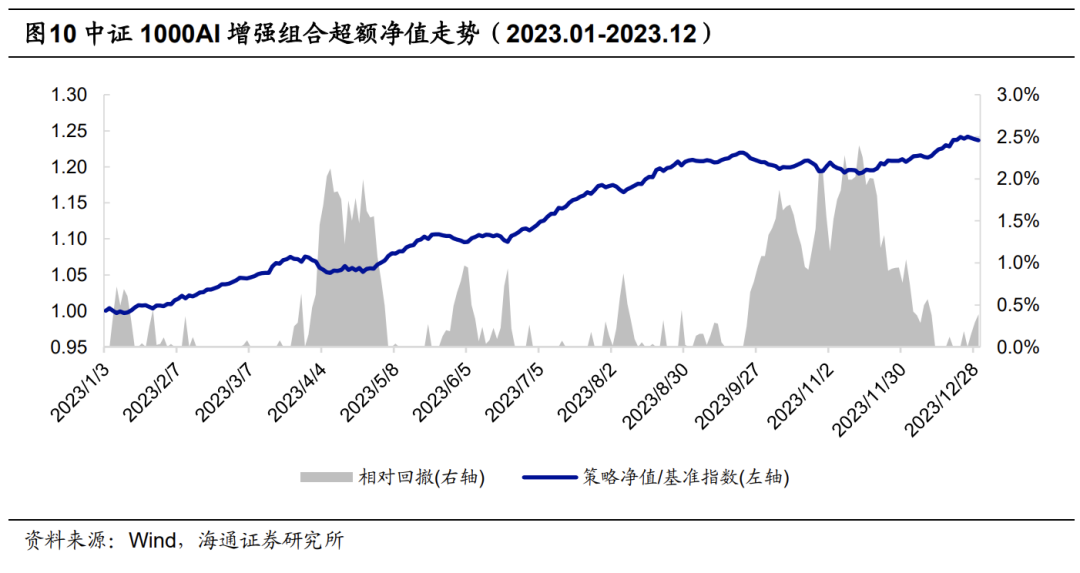
下图展示了该组合2023年以来的超额收益净值走势。区间超额回撤较大的时间段有两个,分别为2023年3月底至4月中旬和2023年11月,幅度都接近2.5%。
04
总结
本文在系列前期报告的基础之上,对比和讨论了基于不同类别的深度学习模型训练得到的因子的周度选股能力。根据我们的测试结果,卷积类模型、Transformer类模型和线性类模型皆有十分出色的表现。相对而言,BiATCN模型、TCN模型、Transformer模型和DBiAGRU模型的周度选股能力更强。
不同模型训练得到的因子之间虽然存在较高的截面相关性,但极值组合的历年多头超额收益依旧有一定的差异,尤其是对比BiAGRU和其余模型。通过简单的分析可知,不同模型对量价信息的学习和调整速度并不一致,使得它们在特定时段的表现出现分化。
由于模型的网络结构、超参数选择等因素皆会影响模型对量价信息的学习和调整,我们尝试将不同网络训练得到的因子等权集成,希望获得更稳健的因子表现。从我们的回测结果来看,BiAGRU模型在叠加BiATCN或Transformer后,因子周均Rank IC和极值组合的超额收益得到进一步提升。应用于增强组合的构建时,亦可观测到类似特征。相对而言,基于BiAGRU+BiATCN和+BiATCN+Transformer模型构建的中证500 AI增强组合的超额收益表现更优。
05
风险提示
市场系统性风险、资产流动性风险、政策变动风险、因子失效风险。

联系人


本篇文章来源于微信公众号: 海通量化团队