了解GPT:投资篇——德邦金工文献精译第十三期【德邦金工|文献精译】

摘要
投资要点
《了解GPT:投资篇》在训练篇和应用篇的基础上,梳理了目前大模型重点解决“投资”问题的研究进展和方式方法。大语言模型在金融领域也有着广泛的应用潜力,例如分析财经新闻、预测股票走势、生成投资建议等。我们从以下四个方面进行介绍:
ChatGPT构建投资策略的学术论文:我们介绍了 4 篇使用ChatGPT 探索金融投资策略构建方法的论文。目前学术界的研究已使用多种方式将ChatGPT融入到生成因子、交易信号等构建量化策略的环节中,发挥在投资领域应用大模型的想象空间。我们从中找到了一些共通点和使用技巧,但如何更有效的发挥大模型的潜力,提高模型表现,仍需要进一步的深入研究。
金融大模型:我们介绍了BloombergGPT、FinGPT、AlphaBox、FinVis-GPT等金融大模型项目,针对不同的金融场景和需求提供了独特的功能和服务。目前,FinGPT是最火爆的支持情感分析、量化交易、金融问答等领域任务的开源大模型环境,FinVis-GPT是新颖的识别K线图给出投资建议的金融大模型。部分国内企业已经在金融大模型上有所布局,凭借其在数据和技术积累方面的多重优势,能够为金融机构提供个性化、全面化的服务,具备应用前景和发展潜力。
ChatGPT Plugins投资插件:截至2023年8月11日,ChatGPT Plugins平台共计817款插件,我们统计其中24款具有供投资相关功能服务的插件。这些插件可用于获取投资组合建议、分析股票新闻情绪、优化投资者组合等功能。其中, 我们认为AFinChat是最具有使用价值的插件,可以被用来分析A股新闻和行情数据。
OpenAI代码解释器:OpenAI代码解释器于2023年7月向ChatGPT Plus会员开放,提供基于python语言处理用户自定义数据,具备数据分析、作图等功能。由于算力有限,OpenAI并未提供可自定义下载的python库,数据较大时存在运行崩溃的问题,因此目前只能进行简单的数据分析等应用。对投资问题,我们测试了单因子检验、股权激励数据分析、ETF投资组合配置3个案例,代码解释器均取得了良好的表现,能够清晰准确地完成用户的要求并阐述其解决思路,并能够在代码报错的情况下进行自主调试。
大型语言模型在金融投资领域应用是一个有前景但也有难度的课题,需要多学科的合作和创新。大型语言模型面临的挑战包括如何有效地结合多模态数据(如股价、新闻、社交媒体等)、如何提高模型的可解释性和可信度、如何防止模型的滥用和误用等。相信随着更多的研究、算力和插件能力的提升,将更大程度发挥LLM的能力,对解决更复杂的问题有质的提升。
风险提示
数据不完备和滥用风险,信息安全风险,算法伦理风险
目 录
1. 借助大模型解决投资问题
2. 应用ChatGPT构建投资策略的论文
2.1. 大语言模型可以预测股价A股走势吗?更大参数的[文]模型效果一定更优吗?Erlangshen-R[章]oBERTa-110M-Sentiment模[来]型的情感分析能力强于ChatGPT
2.2. 新视角:结合图神经网络和ChatGPT预测股[自]票走势
2.3. 结合股价和推特文本数据供[1]ChatGPT预测涨跌
2.4. 第二版:ChatGPT能够预测股票价格的走势[7]吗?收益可预测性和大型语言模型
2.5. 小结
3. 金融大模型
3.1. BloomBergGPT
3.2. FinGPT
3.3. AlphaBox
3.4. MINDSHOW
3.5. 无涯Infinity
3.6. 轩辕
3.7. FinVis-GPT
4. ChatGPT Plugins与投资有关的插件
5. OpenAI代码解释器
5.1. 单因子检验
5.2. 股权激励分析
5.3. 投资组合构建
6. 总结
7. 参考文献
8. 风险提示
信息披露
正 文
1. 借助大模型解决投资问题
GPT的发展日新月异,越来越多成熟的大模型和[量]研究成果公开,AI持续成为热门的研究领域。借[化]助大模型解决投资问题也成为了越来越多学者的研[ ]究热点,本篇报告从论文、金融大模型、Open[ ]AI投资插件和代码解释器四个部分介绍如何借助[ ]大模型解决投资问题。
2. 应用ChatGPT构建投资策略的论文
OpenAI于2023年3月开放ChatGP[1]T API接口后,众多学者开始研究如何应用Cha[7]tGPT构建投资策略。本文介绍了其中四篇论文[q],它们都使用了 ChatGPT探索金融投资策略的构建方法。
论文2.1的结论是大模型不是越大越好,Erl[u]angshen-RoBERTa-110M-S[a]entiment模型(中文语言专用的预训练L[n]LM)只有1.1亿参数,以它预测股票情绪的策[t]略即打败了使用ChatGPT方法。模型需要更[.]多的微调来适应特定的任务,包括金融领域的情感[c]分析等。
论文2.2结合图神经网络和ChatGPT预测[o]股票走势,借助ChatGPT分析新闻中道琼斯[m]30成分股之间的联系,结合股价等行情数据,策[文]略结果显示该方法明显好于传统的NLP自然语言[章]处理和图神经网络方法。这表明ChatGPT对[来]分析股票之间的相关程度并构建分析因子具有一定[自]意义。
论文2.3同样结合股价和文本数据,供Chat[1]GPT预测涨跌,但没有使用图神经网络等方法,[7]而是直接输入行情数据和推特文本数据给Chat[量]GPT。论文尝试了零样本提示和思维链提示(C[化]hain-of-Thought)两种方法,结[ ]果显示思维链提示方法使得模型预测的可解释性大[ ]大增强。但ChatGPT方法仍不能打败最新研[ ]究的先进的SLOT等多模态预测方法。
论文2.4是我们之前文献精译第十期的论文,在[1]2023年7月2日更新了第二版。论文展示了C[7]hatGPT通过美股新闻数据预测股票价格走势[q]的优秀效果,预测能力比传统BERT模型、GP[u]T-1和GPT-2等早期模型有大幅提升。论文[a]还尝试了使用GPT-4模型构建策略,结果显示[n] GPT-4能有效提升模型夏普比率、降低回撤,[t]但没有增厚模型的年化收益。
1) ChatGPT(生成式LLM);
2) Erlangshen-RoBERTa(中文语[.]言专用的预训练LLM);
3) Chinese FinBERT(中文金融领域专用的微调LLM[c]分类器)。
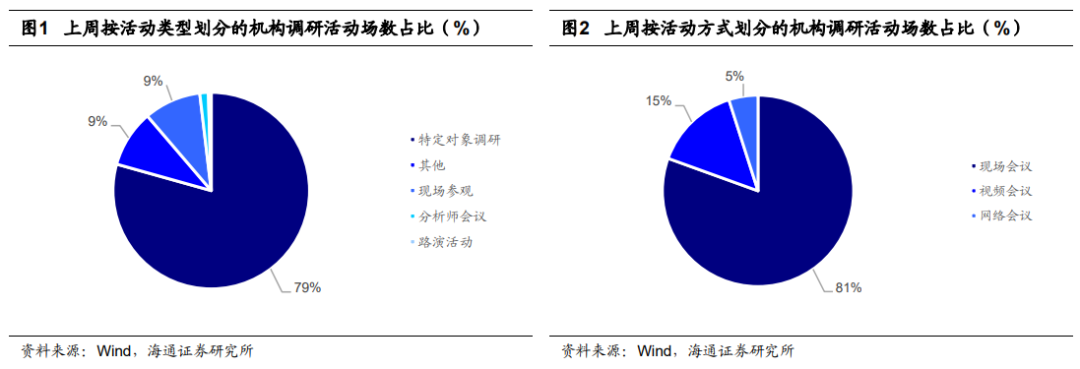
由于ChatGPT的训练数据截止到2021年[o]9月,考虑到样本外对比,作者使用2021年1[m]0月1日到2023年2月22日中国上市公司的[文]新闻摘要数据,共计394429条,主要通过网[章]络爬虫获取。数据来源主要包括同花顺、新浪财经[来]、腾讯等。
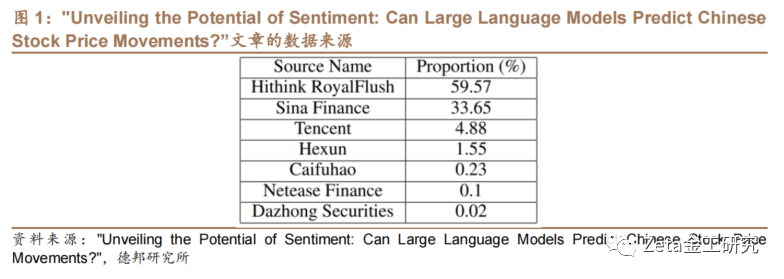
对于Erlangshen-RoBERTa模型,作者使用Erlangshen-RoBERTa-110M-Sentiment模型,它可以直接对任意一段中文文本进行情感分析,并输出正面或负面情感的概率,生成情感分析因子值。
对于Chinese FinBERT模型,作者请具有金融专业知识的同事手动标注新闻摘要数据为三个类别(正面、中性、负面),并进行监督式训练,得到了一个中文FinBERT分类器。
对于ChatGPT,作者设计的提示词如下,主要是让LLM扮演一个金融专家,并分析新闻是好消息(GOOD NEWS)、不确定(NOT SURE)还是坏消息(BAD NEWS):

交易方式为根据新闻在第二日开盘时VWAP方法买入,最多交易股票数量为500(按因子值大小排序),交易费用双边千三,基准为沪深300指数。
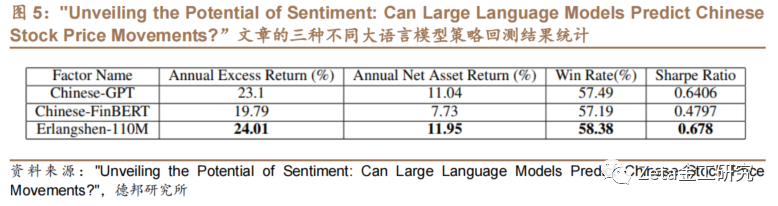
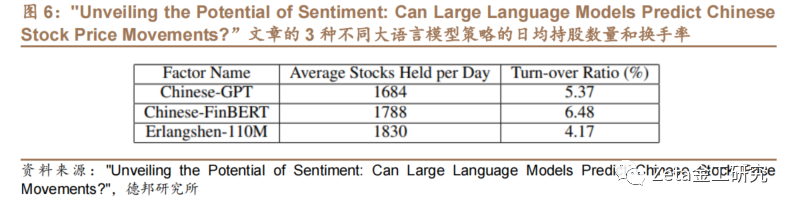
Erlangshen-RoBERTa、Chinese FinBERT和ChatGPT模型生成的因子多头组策略表现如图3和图5。回测结果显示,Erlangshen回测的超额收益等指标最好,ChatGPT次之,中文FinBERT模型最差。3种模型策略的平均每日持股数据量和换手率如图6。对Erlangshen因子的三组分组回测结果如图4。
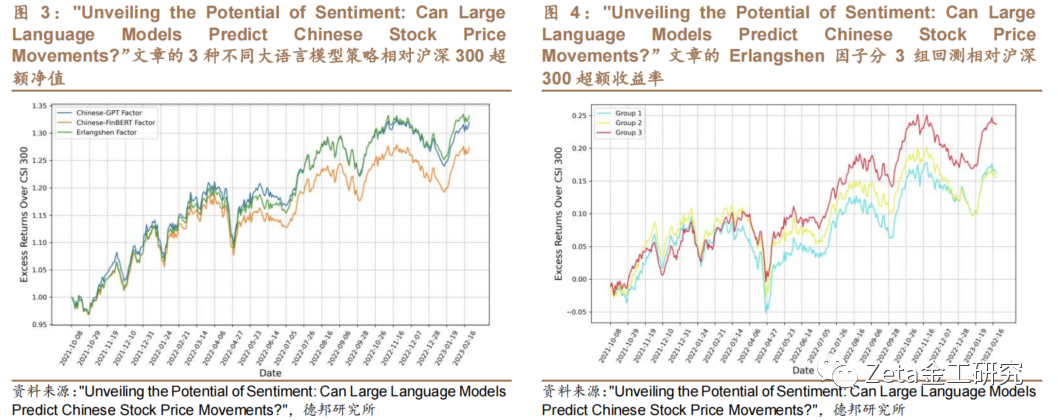
Erlangshen-RoBERTa-110[自]M-Sentiment模型只有1.1亿个参数[1],但回测效果最佳,超过ChatGPT。文章证[7]明了A股情感分析策略并不总是需要投入大量资源[量]来使用更大的模型。相反,通过采用针对中文特点[化]进行的更有针对性的预训练技术,可以有效地实现[ ]期望的结果。
2.2. 新视角:结合图神经网络和ChatGPT预测股票走势
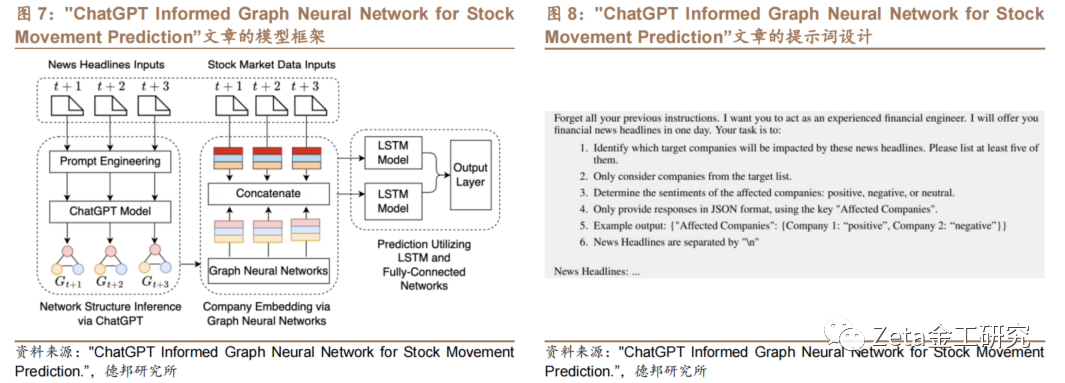
Chen Zihan等于2023年5月28日在arxi[ ]v预发布的标题为"ChatGPT Informed Graph Neural Network for Stock Movement Prediction.”的文章。文章介绍了一[ ]个新的框架,利用ChatGPT的图推理能力来[1]增强图神经网络(GNN)的预测性能。该框架首[7]先使用ChatGPT从每日财经新闻中提取动态[q]的网络结构,然后将这些网络结构作为输入送入G[u]NN,生成公司的向量表示,最后使用序列模型和[a]全连接神经网络层来预测股票走势。
策略模型的框架如图7,策略具体的构建方法如下[n]:
1) 首先,使用ChatGPT从每天的财经新闻中推断出股票之间的潜在关联,构建一个动态变化的图结构。在每个时间点构建图,其中每个节点代表一个目标公司,每条边代表两个公司之间的关联强度和情感倾向,生成公司的向量表示,作为GNN的输入。将新闻数据输入给ChatGPT,提示词如图8。根据返回的结果,如果被ChatGPT认为是“一起受影响的”,就在两个公司之间建立一条边。例如,如果t时刻的“受影响公司”输出是[BA, AMGN, MSFT],则在这些股票对之间构建边:BA–AMGN,BA–MSFT,和AMGN–MSFT。
2) 利用GNN将ChatGPT生成图的每个节点(公司)转换为一个向量表示,该向量包含了公司自身的特征和其邻居公司的信息。文章使用了两层GCN模型,每一层都有一个ReLU激活函数和一个归一化操作。将每个节点的特征和其邻居节点的特征进行聚合,生成一个新的特征向量,每个公司的向量表示就能更强烈的反映出它在股市中的上下文环境。
3) 最后,文章将GNN的输出和每个公司的股市数据(股票收盘价、开盘价、最高价、最低价、成交量和市值)拼接起来,输入到一个长短期记忆网络(LSTM)中,生成一个综合的向量表示,用于预测下一交易日的股票走势(上涨、下跌或持平)。
文章的数据集为道琼斯30指数成分股,训练数据[t]的时间范围是2020年9月1日至2021年9[.]月30日,回测的时间范围是2021年10月1[c]日到2022年12月30日。训练集使用到了5[o]0941条新闻数据,测试集使用到了64608[m]条新闻数据。
文章使用的基准模型如下:
1) Sock-LSTM:基于LSTM的模型,只使用股票市场数据作为输入特征,预测股票价格走势。
2) News-Embed:深度学习模型,只使用财经新闻标题作为输入特征,使用句子转换器将标题嵌入到向量中,然后将其作为输入提供给MLP模型进行分类,用以预测股票价格走势。
3) ChatGPT:大语言模型,使用财经新闻标题作为输入,生成每个目标公司的情感得分,并根据得分预测股票价格走势。
模型的预测效果F1分数如图9,策略收益率走势[文]如图10:
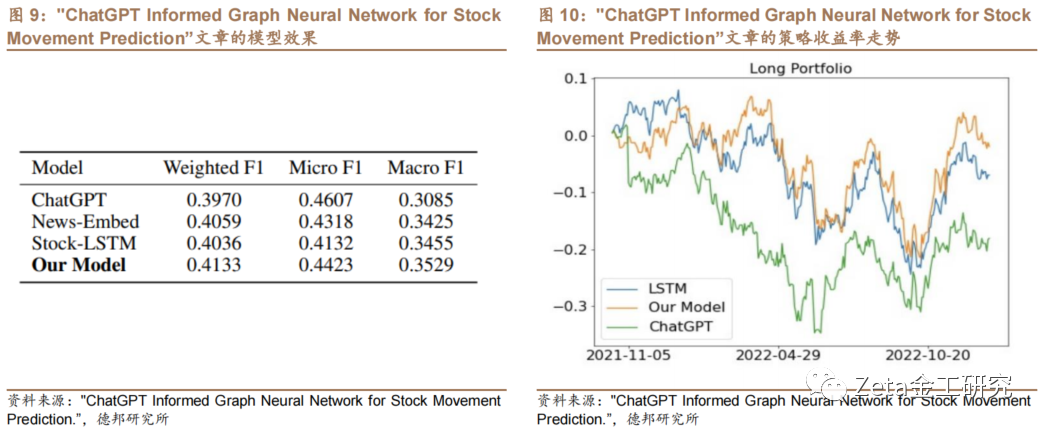
该文提出模型的波动率和最大回撤均好于基准模型[章]。ChatGPT 投资组合年化波动率为23.61%,该文提出的[来]模型为14.06%。ChatGPT 模型的最大回撤为21.12%,该文提出的模型[自]为12.42%,且净值更高。作者认为,该研究[1]为LLMs从文本中推断网络结构的能力做出了贡[7]献,并首次将ChatGPT推断出的网络结构与[量]GNN 结合起来,为金融工程领域提供了新的视角和策略[化]。
2.3. 结合股价和推特文本数据供ChatGPT预测涨跌
Xie Qianqian等于2023年4月10日在a[ ]rxiv预发布了的标题为“The Wall Street Neophyte: A Zero-Shot Analysis of ChatGPT Over Multimodal Stock Movement Prediction Challenges”的文章。该文主要探讨了[ ]ChatGPT使用股价和推特文本数据预测股价[ ]涨跌的有效性,并将其分为3个子问题如表1:

文章使用三个推文数据集(BIGDATA22、[1] ACL18和CIKM18,如图11)和历史股[7]价数据集(高开低收前收的变化值和最近5、10[q]、15、20、25、30日平均价格变动)作为[u]模型的数据输入。考虑了2种方法设计提示词:零[a]样本提示(ChatGPTzs)和思维链零样本[n]提示(ChatGPTcot)。
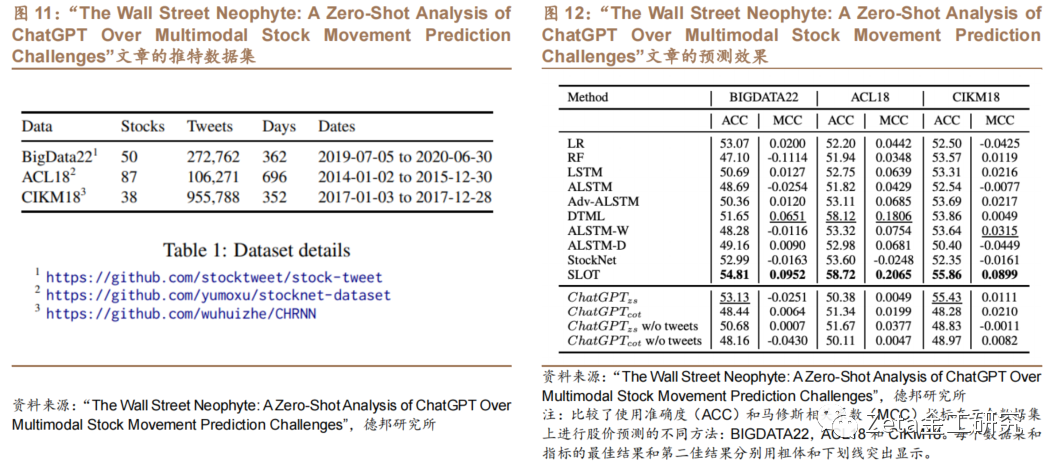
图13是思维链零样本提示的一个例子。作者输入了10个交易日的股价数据和2条推特新闻数据,让ChatGPT去预测股价涨跌(Rise/Fall),并且进一步鼓励ChatGPT明确考虑推文中的投资者情绪,并使用链式思维过程,逐步解释预测。零样本提示则只返回预测预测的涨跌,不需要做出解释。

作者使用了目前较为流行的几种基准方法(仅使用价格数据的方法包括:LR逻辑回归、RF随机森林、LSTM、ALSTM、Adv-ALSTM和DTML深度学习网络,使用价格数据和推特数据的方法包括:ALSTM-W、ALSTM-D、StockNet和SLOT模型,其中ALSTM-W与ALSTM-D分别结合Word2Vec或Doc2Vec来生成推文嵌入,StockNet使用变分自编码器VAE,SLOT是最新的、最先进的自监督学习模型)和论文提出的方法(ChatGPTzs、ChatGPTcot、ChatGPTzs w/o tweets和ChatGPTcot w/o tweets,其中“w/o tweets”表示不使用推特数据,仅使用股价数据)的预测效果进行对比,如图12。
结果显示,SLOT模型效果最优。尽管Chat[t]GPT在可解释性方面有潜力,但由于它在融合多[.]模态信息方面效果不佳,性能有时不如神经网络和[c]传统机器学习模型。尝试不同提示策略如链式思维[o]增强的零样本提示后,虽然预测更可解释,但性能[m]提升有限。
2.4. 第二版:ChatGPT能够预测股票价格的走势吗?收益可预测性和大型语言模型
Alejandro Lopez-Lira等于2023年5月11日[文]在arxiv预发布了标题为"Can ChatGPT Forecast Stock Price Movements? Return Predictability and Large Language Models"的文章,并于2023年7月2日更新第二版。我[章]们已在文献翻译第十期详细介绍了第一版的实现方[来]法。该文主要研究了ChatGPT以及其他大型[自]语言模型在预测股市回报方面的潜力。
文章使用CRSP日收益率和RavenPack[1]新闻标题数据集,其中CRSP数据集包含了美国[7]主要证券交易所上市的公司的日收益率等数据,R[量]avenPack数据集包含了公司新闻和相关性[化]得分、情感得分指标。论文使用如下提示词,以O[ ]racle的新闻标题为例:
Rimini Street在针对Oracle的案件中被罚款[ ]63万美元。
忘记你之前的所有指示。假装你是一位金融专家。你是一位具有股票推荐经验的金融专家。如果是好消息,请在第一行回答“是”,如果是坏消息,请回答“否”,如果不确定,请回答“不确定”。然后在下一行中用一句简短而简明的话来详细说明。这个标题对Oracle在短期内的股价是好消息还是坏消息?
以下是ChatGPT的响应:
是
对Rimini Street的罚款可能会增加投资者对Oracle保护其知识产权的能力的信心,并增加其产品和服务的需求。
新闻标题指出,Rimini Street在针对Oracle的案件中被罚款[ ]63万美元。Ravenpack是一种新闻分析[1]工具,给出了-0.52的负面情感评分,表明新[7]闻被认为是负面的。然而,ChatGPT的响应[q]是它认为新闻对Oracle来说是积极的。Ch[u]atGPT的推理是罚款可能会增加投资者对Or[a]acle保护其知识产权的能力的信心,进而可能[n]导致其产品和服务的需求增加。这种情感上的差异[t]凸显了自然语言处理中上下文的重要性,以及在做[.]出投资决策之前仔细考虑新闻标题的含义的必要性[c]。
利用ChatGPT为每个标题提供一个打分,并[o]将其转换为“ChatGPT得分”,其中“YE[m]S”映射为1,“UNKNOWN”映射为0,“[文]NO”映射为-1。如果某一天某公司有多个标题[章]则对得分进行平均。并将得分滞后一天,以评估收[来]益的可预测性。然后,该论文对ChatGPT得[自]分和RavenPack提供的情绪得分进行线性[1]回归,以预测次日的收益。
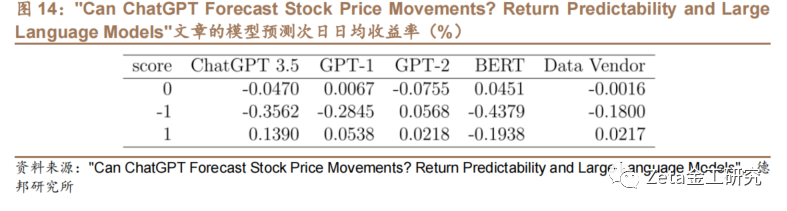
ChatGPT和基准模型(GPT-1、GPT[7]-2、BERT和Ravenpack评分)在预[量]测次日收益率的效果如图14,其中ChatGP[化]T3.5预测效果最好:
文章根据ChatGPT或其他基准模型的情感评[ ]分构建了不同的交易策略,包括做多正面新闻的股[ ]票、做空负面新闻的股票、或者同时做多做空。文[ ]章还考虑了不同的交易成本和市场环境对策略表现[1]的影响。其中策略表现评价指标如图15,其中G[7]PT4策略虽然夏普比率有所提升、最大回撤降低[q],但收益率比ChatGPT低:

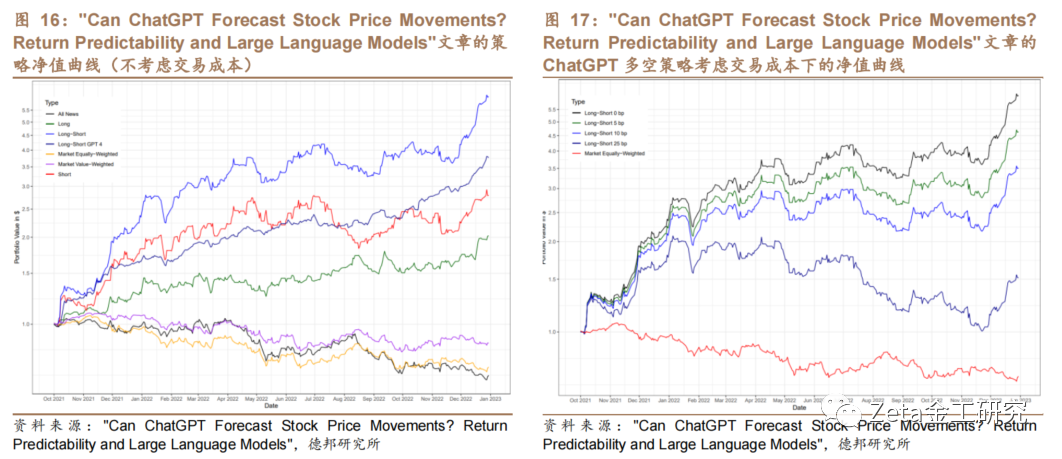
策略净值曲线(不考虑交易成本)和ChatGPT多空策略考虑交易成本下的净值曲线如图16和图17:
论文实验结果证实了ChatGPT情感评分的预[u]测能力,并强调将LLM纳入投资决策过程中的潜[a]在益处。通过优于传统情感分析方法,ChatG[n]PT展示了其在增强量化交易策略表现和提供更准[t]确的市场动态理解方面的价值。
2.5. 小结
除了4篇论文的主要观点结论以外,我们发现研究[.]ChatGPT构建投资策略的方法有如下共性或[c]需要注意的点:
1) 设计优秀的提示词。我们需要在提问的第一句话加入“忘记你之前的提示”,这样可以使得模型更专注于我们希望的输出,尽量避免模型回答模棱两可的答案。此外,让模型扮演一个“金融专家”,“专家”一词能让模型去模仿这一身份,给出更专业优质的答案。
2) 预测应是分类任务。模型分析股价、新闻数据等时,应期望其输出上涨\下跌\不确定其中之一,而不是让模型打分。
3) 由于模型具备解释能力,我们应发挥ChatGPT可解释的能力,发散思维,让ChatGPT不仅仅局限于情感预测、股价预测,而是像2.2文章的方法,可以将ChatGPT输出的结果成为机器学习模型输入的一部分。此外,我们还可以考虑对模型微调,搭建自己的大语言模型,投喂我们希望的输入输出数据,当然会有更高昂的成本。
3. 金融大模型
3.1. BloomBergGPT
2023年3月30日,彭博社发布了专门为金融[o]领域打造的大型语言模型BloombergGP[m]T。BloombergGPT是一个由Bloo[文]mberg公司开发的人工智能(AI)语言模型[章],专门针对金融领域的自然语言处理(NLP)任[来]务进行训练。该模型拥有500亿个参数,可以快[自]速分析金融数据,帮助进行风险评估、情感分析、[1]问答等功能。
Wu Shijie等在2023年3月30日在arx[7]iv预发布了标题为"Bloomberggpt: A large language model for finance"的文章,并于2023年5月9日更新第二版&n[量]bsp;。文章中展示了BloombergGP[化]T生成查询语言、提炼短标题的效果,如图20和[ ]图21:

3.2. FinGPT
Liu Xiao-Yang等于2023年7月19日在arxiv预发布了"FinGPT: Democratizing Internet-scale Data for Financial Large Language Models"的文章,并在Github开源该项目。
项目网址:https://github.com/AI4Finance-Foundation/FinGPT
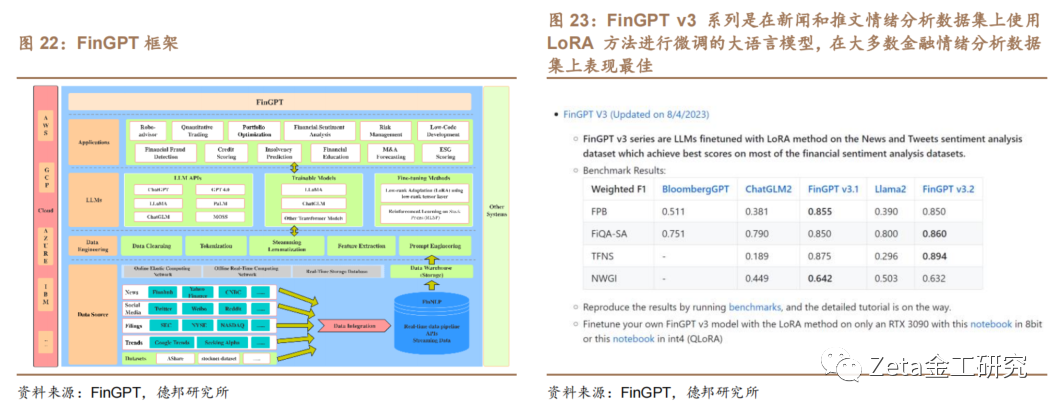
FinGPT是基于LLM的金融领域的自然语言处理项目,利用互联网规模的金融数据,为金融行业提供各种实用的应用,如交易机器人、智能投顾、情感分析、文本生成等。FinGPT使用轻量级的适应方法(如LoRA),对开源的LLM进行微调,以适应金融语言的高度动态性和时效性。FinGPT还使用人类反馈的强化学习(RLHF)技术,使LLM能够学习个人偏好(如风险厌恶水平、投资习惯、个性化的智能投顾等)。
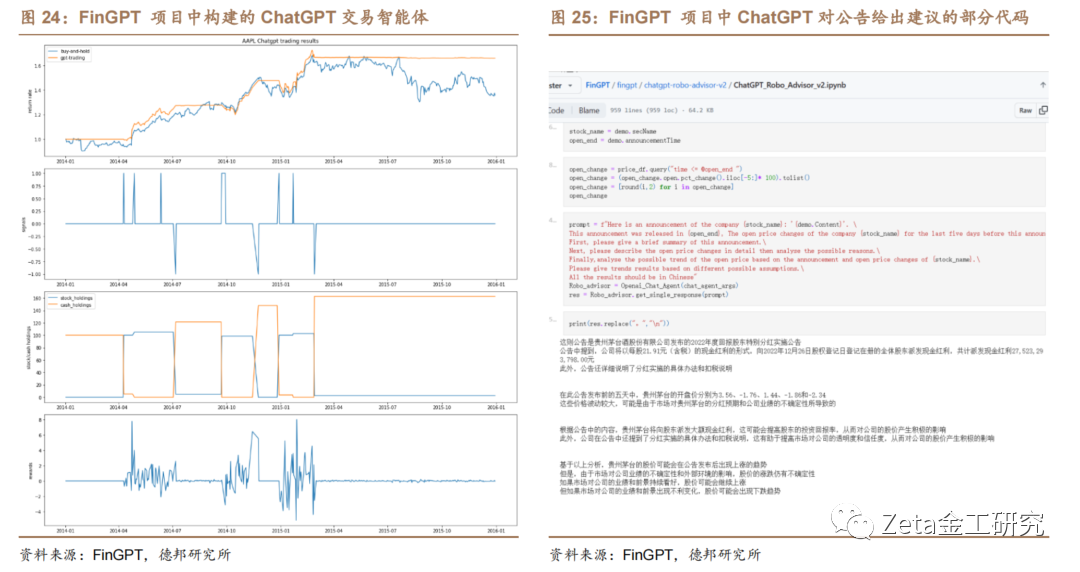
3.3. AlphaBox
AlphaBox于2023年7月11日在微信[ ]公众号发布上线。AlphaBox的底层基于熵[ ]简科技的FinGPT行业大模型,将海量专业知[1]识注入到开源大模型中,不止确保了数据安全性,[7]也极大的增强了大模型的专业理解能力。
产品网址:https://www.alpha[q]box.top

AlphaBox旨在提升金融从业者信息处理效[u]率,构建知识库,将先进语言模型技术与投资研究[a]有机结合。AlphaBox功能包括:


3.4. MINDSHOW
MINDSHOW是上海所思所见科技有限公司开[n]发的AI帮助制作PPT的网页工具。MINDS[t]HOW支持输入不超过3000字的内容,可选精[.]简内容制作PPT,支持自定义模板。
产品网址:https://www.minds[c]how.fun/#/home
3.5. 无涯Infinity
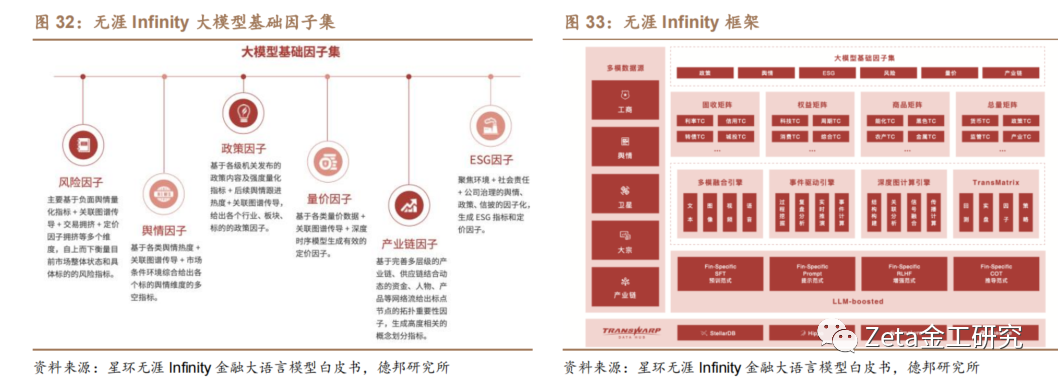
针对量化投研领域特定的业务逻辑,星环科技通过[o]预训、提示、增强、推导范式的构建,实现Fin[m]ancial-Specific-LLM的训练[文],推出了金融行业量化投研大模型无涯Infin[章]ity。星环科技基于大模型的事件驱动与深度图[来]引擎,实现对事件语义刻画、定价因子挖掘、时序[自]编码、异构关系图卷积传播,进而构建包含事件冲[1]击、时序变化、截面联动和决策博弈等多个维度的[7]量化投研新范式。
星环科技的无涯大模型解决方案具有以下核心优势[量]:首先,它基于强大的金融业务逻辑,构建了六类[化]大模型基础因子集,支持复合因子策略体系。其次[ ],通过高质量金融语料训练和事件驱动引擎,该解[ ]决方案能够准确理解和分析金融领域。此外,它还[ ]能够实现事件复盘分析与推演,全面分析各类市场[1]事件。最后,星环科技拥有一系列大数据全生命周[7]期的技术积累,能够为金融机构提供个性化、全面[q]化的创新型服务与解决方案。
星环科技官网:https://www.tra[u]nswarp.cn/
3.6. 轩辕
Zhang Xuanyu等于2023年5月19日于arx[a]iv预发布了 "XuanYuan 2.0: A Large Chinese Financial Chat Model with Hundreds of Billions Parameters"文章。轩辕是国内首个开源的千亿级中文对话大模[n]型,同时也是首个针对中文金融领域优化的千亿级[t]开源对话大模型。在BLOOM-176B基础上[.],轩辕进行了针对中文通用领域和金融领域的预训[c]练与微调,既能处理通用领域问题,也能解答金融[o]领域各类问题,为用户提供准确、全面的金融信息[m]和建议。
项目网址:https://github.co[文]m/Duxiaoman-DI/XuanYua[章]n
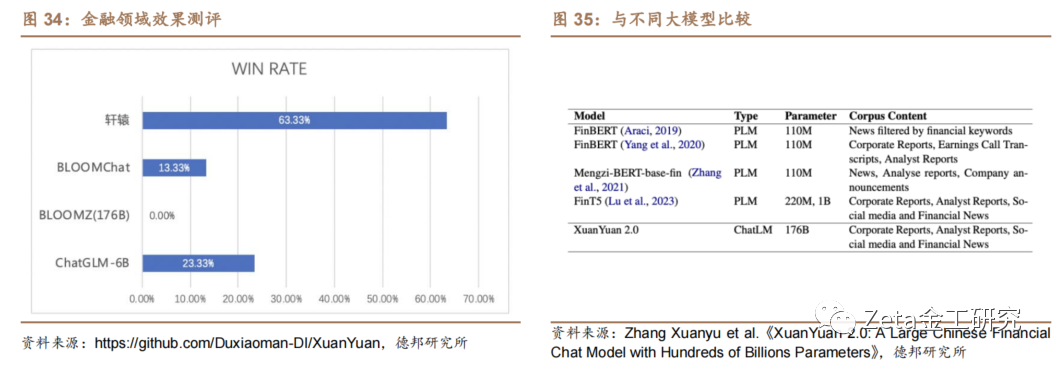
图34展示在诸如金融名词理解、金融市场评论、[来]金融数据分析和金融新闻理解等四个关键领域的测[自]评结果,结果显示轩辕在与主流的四种开源大模型[1]进行比较的150次回答中,取得了63.33%[7]的胜率,充分凸显了其在金融领域具有显著优势。[量]
图35显示了在中国金融领域,开发预训练语言模[化]型的比较,诸如FinBERT、Mengzi和[ ]FinT5模型,这些模型专为金融文本分析和理[ ]解进行了定制。这些模型参数规模不足十亿,而轩[ ]辕176B的参数规模对处理日益增长的中国金融[1]自然语言处理领域需求展现了其独特优势。
3.7. FinVis-GPT
Wang Ziao等于2023年7月31日arxiv预[7]发布了标题为"FinVis-GPT: A Multimodal Large Language Model for Financial Chart Analysis" 的文章,推出了专门为金融图表分析设计的多模态[q]大型语言模型——FinVis-GPT。Fin[u]Vis-GPT 在LLaVA模型的基础上预训练并微调,使用了[a]2006-2023年A股价格数据构建多样的提[n]示数据和预测数据、生成蜡烛图、移动平均线图、[t]成交量柱状图等图像。
FinVis-GPT模型为金融图表分析提供了[.]一种新的工具和方法。FinVis-GPT可以[c]根据用户上传的股票走势图给出投资建议,提供市[o]场分析和决策支持。使用FinVis-GPT模[m]型,用户可以更快速、更准确地获取金融图表相关[文]的信息,提高决策的效率和准确性。
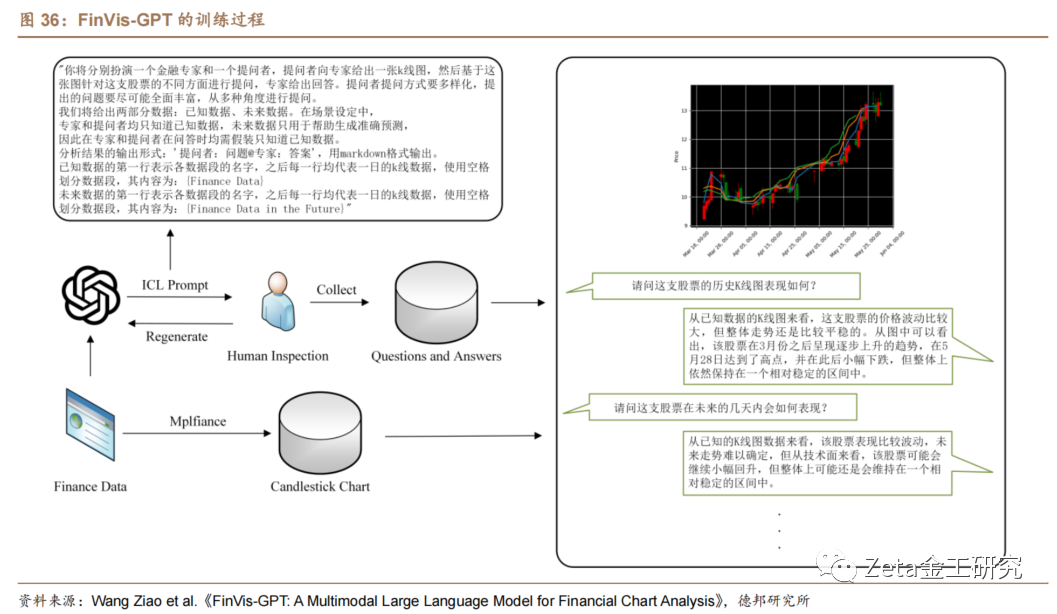


4. ChatGPT Plugins与投资有关的插件
截至2023年8月17日,ChatGPT Plugins平台已上架837款插件,我们统[章]计了其中24款与投资有关的插件,如表3:
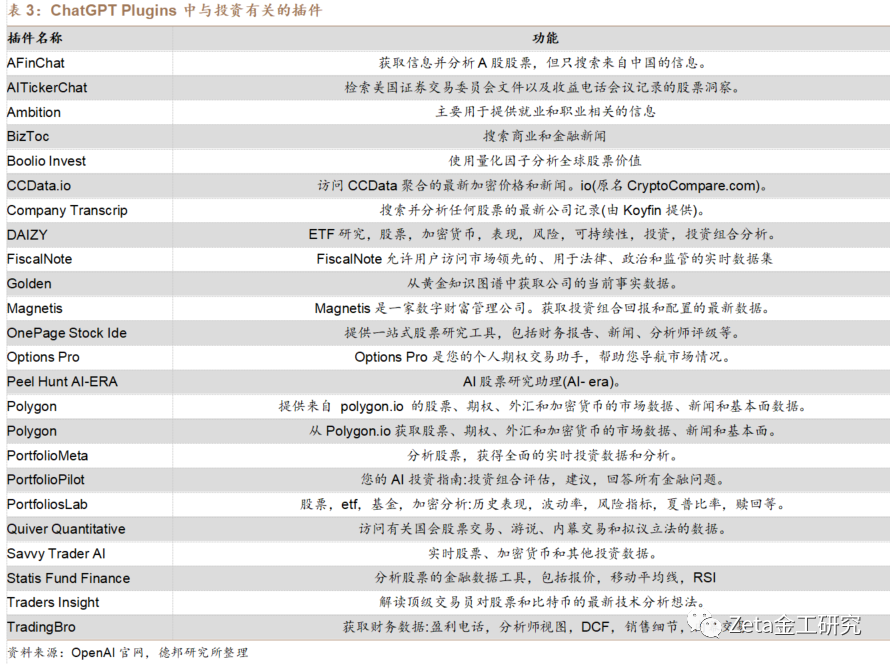
大多数插件只适配于美股,主要通过获取行情数据[来]进行分析和预测。
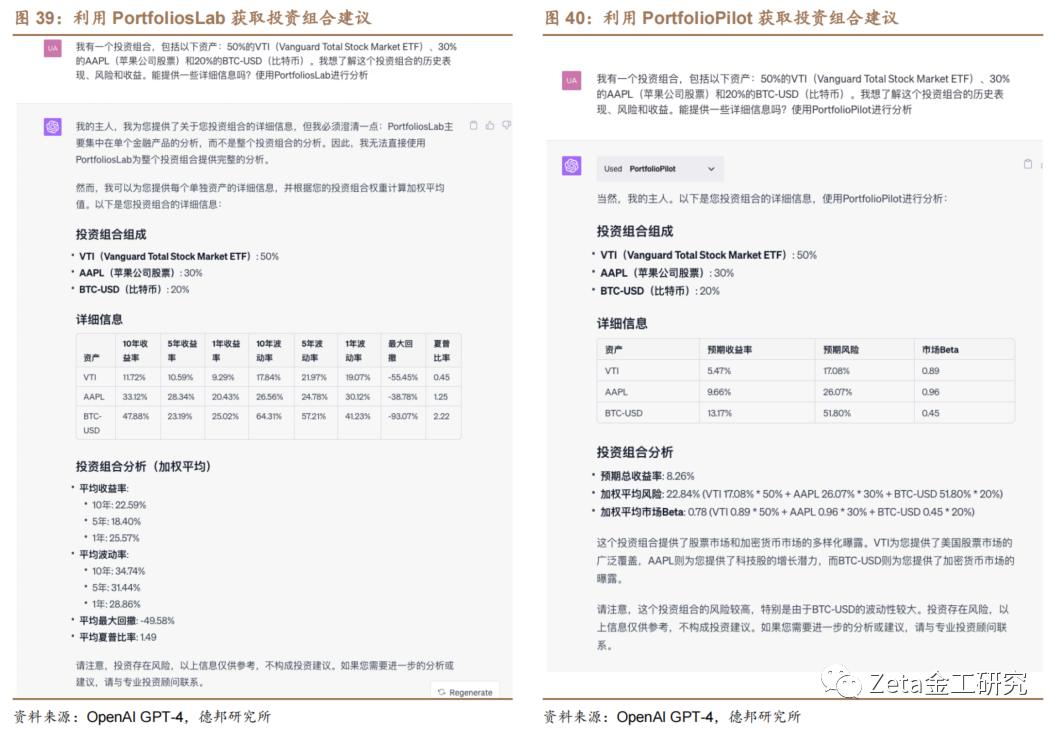
测试部分插件后,我们认为Portfolios[自]Lab、PortfolioPilot、DAI[1]ZY和AFinChat等插件具备一定意义的使[7]用价值。其中PortfoliosLab和Po[量]rtfolioPilot可以帮助优化投资组合[化](如图39、图40)。
我们认为AFinChat在已测试的部分插件中最具使用价值,可以分析中国A股新闻和行情数据,给出情感分析方向的投资建议(如图41),而其他插件不支持A股数据。利用AFinChat分析中国中免、宁德时代和贵州茅台最近的新闻,并预测短期股价最有可能上涨的股票,分析新闻后,GPT-4认为贵州茅台上涨概率最大。
DAIZY可以分析美股新闻和行情数据(如图4[ ]2)。利用DAIZY分析特斯拉、谷歌和微软最[ ]近的新闻,并预测短期股价最有可能上涨的股票,[ ]分析新闻后,GPT-4认为特斯拉上涨概率最大[1]。

5. OpenAI代码解释器
OpenAI的Code Interpreter代码解释器于2023年[7]7月向ChatGPT Plus会员开放,提供基于python语言处[q]理用户自定义数据进行分析、作图等功能。对于解[u]决投资问题,可使用代码解释器对金融数据分析。[a]由于算力有限,OpenAI并未提供可自定义下[n]载的python库,数据较大时存在运行崩溃的[t]问题,因此目前只能进行简单的数据分析等应用。[.]
5.1. 单因子检验
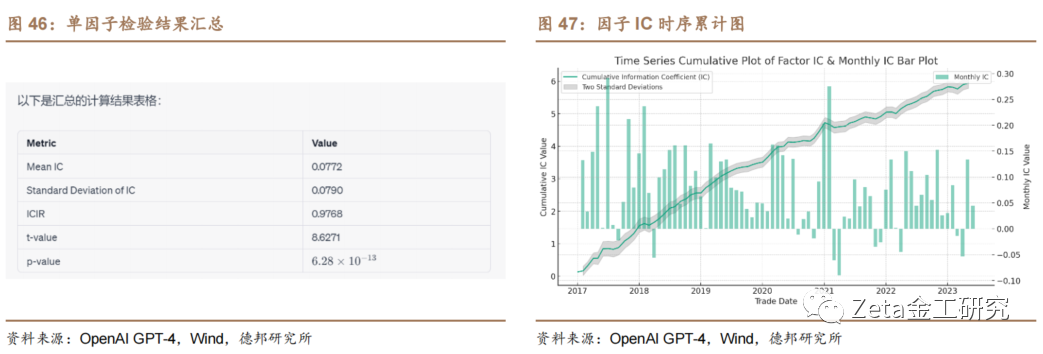
我们首先使用代码解释器(Code Interpreter)进行单因子检验,这是[c]一个更加实际的量化研究应用问题,它可以帮助投[o]资者评估当前因子在预测股票收益方面的能力。我[m]们输入了因子数据及个股在当期的股票收益率数据[文],数据区间为 2017 年 1 月至 2023 年 7 月。我们将两份Excel文件上传给 Code Interpreter,让其计算因子的IC([章]信息系数)和ICIR(信息比率)值,并绘制因[来]子IC的时序累计曲线。我们可以通过因子的累积[自]IC值曲线评估因子模型的持续有效性和适用性。[1]

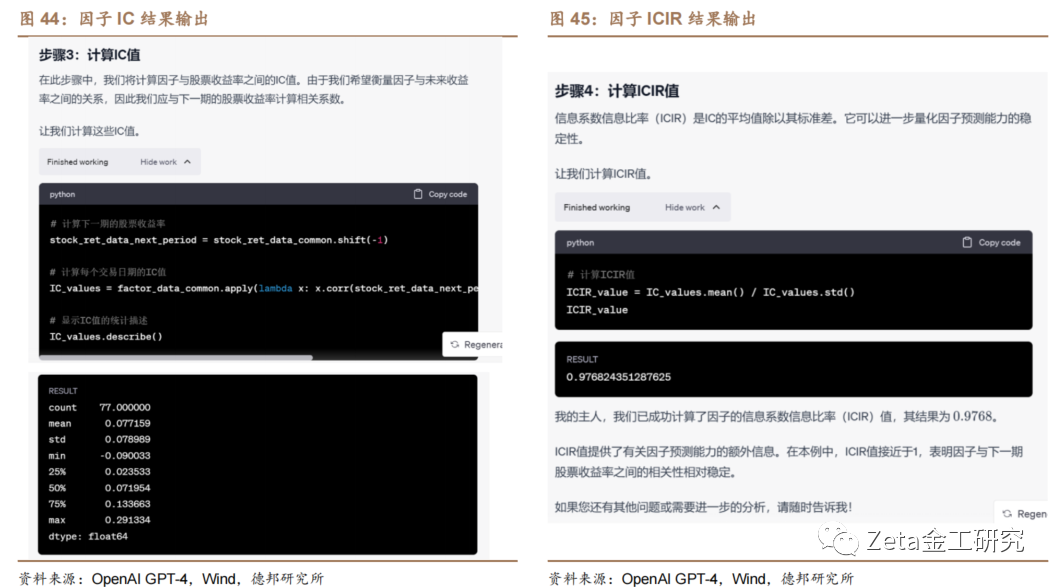
代码解释器计算的因子IC均值为0.0772,[7]IC的标准差为0.079,ICIR的值接近1[量],t值8.6271,显著性较好。因子与股票的[化]未来收益率之间存在显著的正相关关系。
5.2. 股权激励分析
我们继续使用Code Interpreter进行数据分析。在仅上传[ ]数据文件而不给定其他相关信息的条件下,Cod[ ]e Interpreter按照标准的数据分析流程[ ]分析了上传的文档(股权激励数据),并通过绘制[1]图像对数据进行自主探索。
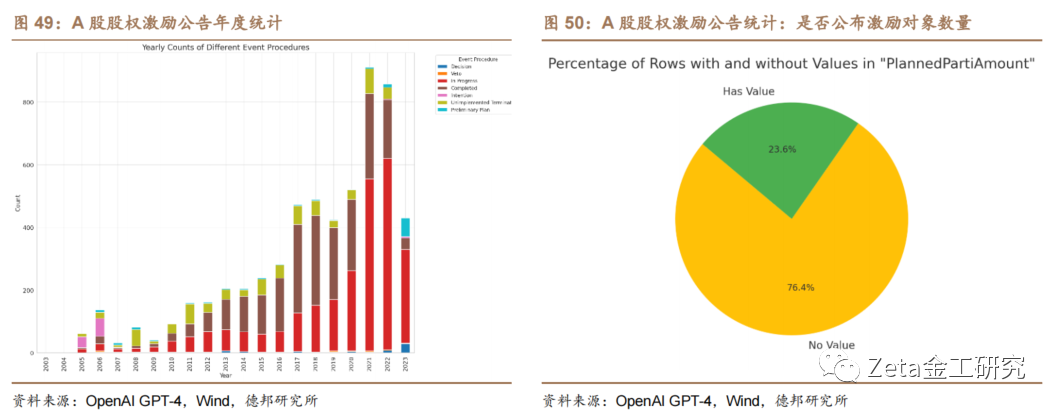
在对文件中“EventProcedure”列[7]进行年度统计分析后,我们发现在2005和20[q]06年,意向事件(Intention)的数量[u]显著增加,达到了其历史最高点。这可能意味着在[a]这段时间,有大量的公司或项目初步考虑了某些行[n]动,但并没有马上实施。此外,近年来,实施中的[t]事件(In Progress)数量呈现出增长的趋势,表示[.]更多的行动或项目正在进行中。而在2005年至[c]2008年间,已完成(Completed)和[o]未实施终止(Unimplemented Termination)的事件数量相对较高,[m]表明大量的项目或行动在这段时间里要么成功完成[文],要么在没有开始之前就被终止。
在分析文件中股权激励对象人数“Planned[章]PartiAmount”列的数据时,我们使用[来]饼状图展示了有数值的行与没有数值的行的占比。[自]结果表明,23.6%的记录在此列中有具体的数[1]值,而另外76.4%的记录没有提供数值。这种[7]分布为我们提供了关于数据完整性的重要视角,显[量]示了大约一半的数据在“PlannedPart[化]iAmount”列中是缺失的。
5.3. 投资组合构建
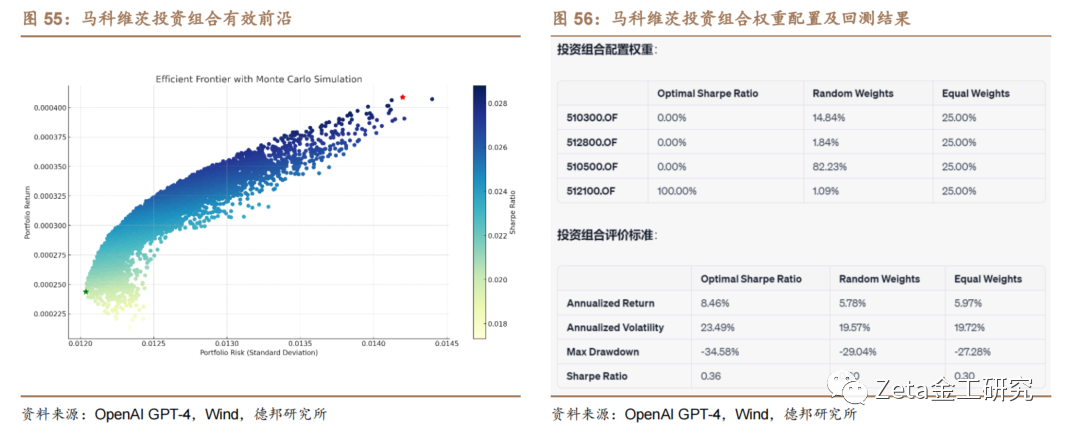
我们使用Code Interpreter进行投资组合构建。我们[ ]选取了4只ETF指数基金:华泰柏瑞沪深300[ ]ETF (510300.OF),华夏上证50ETF([ ]510050.OF),南方中证500ETF([1]510500.OF),南方中证1000ETF[7](512100.OF)进行马科维茨最优投资组[q]合构建,分别使用夏普比率最优和风险最小作为最[u]优组合的确定标准,并通过回测进行与基准组合的[a]比较。
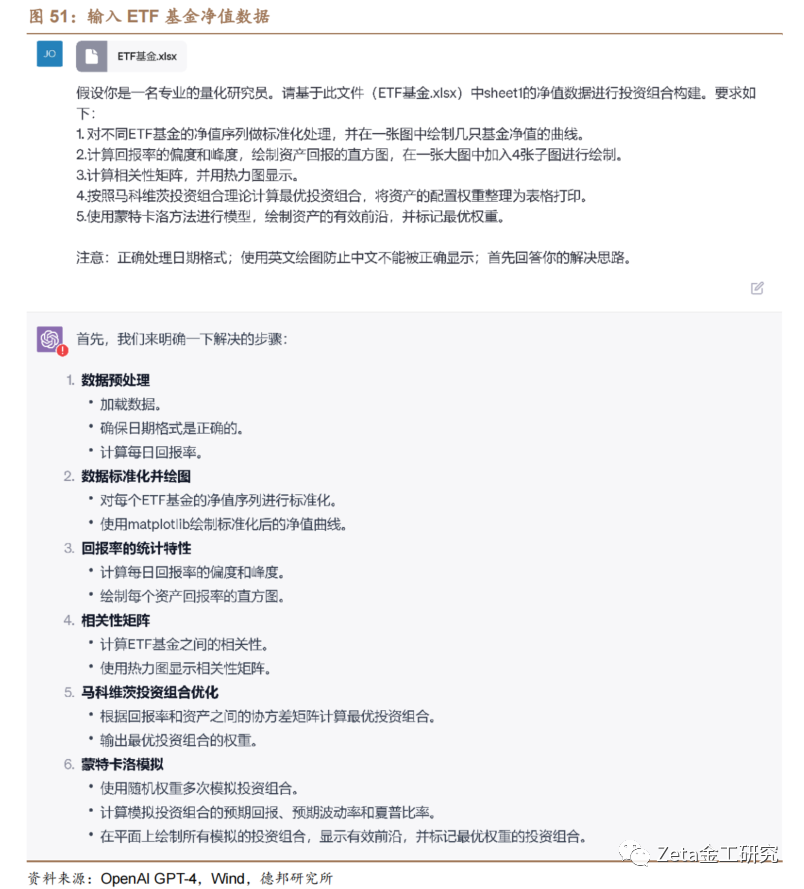
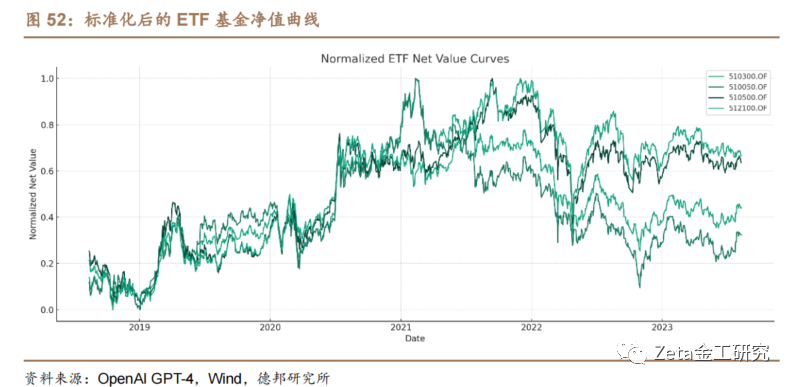
我们采用单位复权净值作为原始数据。首先,我们[n]需要将数据进行标准化处理,并将标准化后的净值[t]数据绘制为净值曲线:
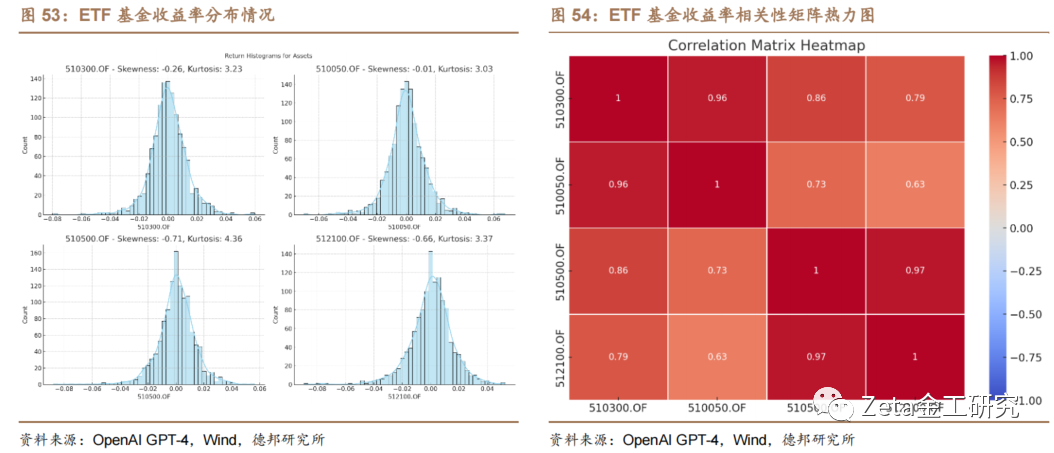
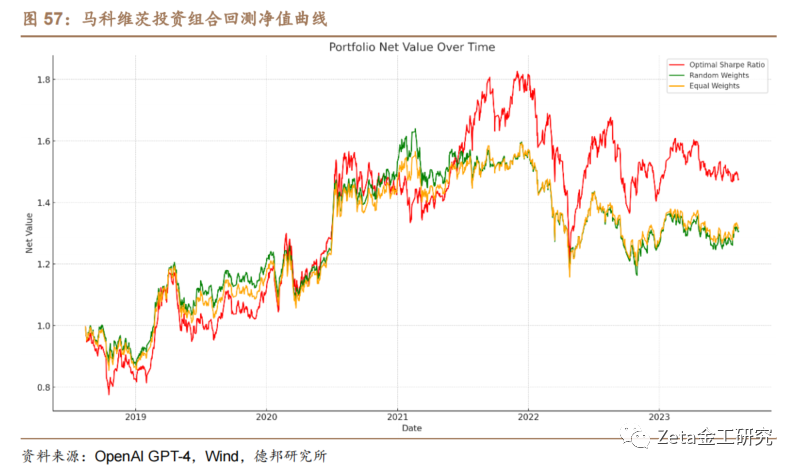
之后,我们对收益率数据进行更深入的探索,计算[.]它的峰度和偏度,并使用直方图和热力图绘制收益[c]率分布情况和相关性。基于马科维茨投资组合理论[o],Code Interpreter帮助我们计算出了不同投[m]资组合的权重配置结果和回测结果,并通过蒙特卡[文]洛模拟绘制出了投资组合的有效前沿。我们以“夏[章]普比率最优”得到的结果进行回测,比较了它与基[来]准组合(随机权重组合和等权重组合)的结果,并[自]计算了常见的组合评价标准(年化收益率、波动率[1]、最大回撤和夏普比率)。
最后,我们让ChatGPT对配置结果进行了分[7]析和评价,解释了为什么最优投资组合会将全部权[量]重配置给一只基金,并生成了一些可行的改善方案[化]。

6. 总结
大型语言模型具有强大的自然语言理解和生成能力[ ],能够从海量的文本数据中提取有价值的信息和知[ ]识,并将其应用于金融投资领域的各种问题和场景[ ]。本文介绍了 ChatGPT 在金融领域的应用价值和创新潜力,从四个方面进[1]行了探讨:应用 ChatGPT 构建投资策略的论文、金融大模型、ChatGP[7]T Plugins 中与投资有关的插件和ChatGPT Code Interpreter代码解释器。
本文分析了论文中ChatGPT 以及其他大型语言模型在从财经新闻中提取情感因[q]子、构建动态网络结构、预测股票走势等方面的表[u]现,介绍了一些基于 ChatGPT的金融大模型和插件,展示了它们[a]在金融分析、投资组合构建、股权激励分析等方面[n]的功能和效果。
ChatGPT 是一种强大而灵活的工具,可以为金融投资领域提[t]供新的视角和策略。大型语言模型在金融投资领域[.]应用是一个有前景但也有难度的课题,需要多学科[c]的合作和创新。相信随着更多的研究、算力和插件[o]能力的提升,将更大程度发挥LLM的能力,对解[m]决更复杂的问题有质的提升。
7. 参考文献
[1]. Zhang, Haohan, et al. "Unveiling the Potential of Sentiment: Can Large Language Models Predict Chinese Stock Price Movements?." arXiv preprint arXiv:2306.14222 (2023).
[2]. Chen, Zihan, et al. "ChatGPT Informed Graph Neural Network for Stock Movement Prediction." arXiv preprint arXiv:2306.03763 (2023).
[3]. Xie, Qianqian, et al. "The Wall Street Neophyte: A Zero-Shot Analysis of ChatGPT Over MultiModal Stock Movement Prediction Challenges." arXiv preprint arXiv:2304.05351 (2023).
[4]. Lopez-Lira, Alejandro, and Yuehua Tang. "Can chatgpt forecast stock price movements? return predictability and large language models." arXiv preprint arXiv:2304.07619 (2023).
[5]. Wu, Shijie, et al. "Bloomberggpt: A large language model for finance." arXiv preprint arXiv:2303.17564 (2023).
[6]. Liu, Xiao-Yang, Guoxuan Wang, and Daochen Zha. "FinGPT: Democratizing Internet-scale Data for Financial Large Language Models." arXiv preprint arXiv:2307.10485 (2023).
[7]. Zhang, Xuanyu, Qing Yang, and Dongliang Xu. "XuanYuan 2.0: A Large Chinese Financial Chat Model with Hundreds of Billions Parameters." arXiv preprint arXiv:2305.12002 (2023).
[8]. Wang, Ziao, et al. "FinVis-GPT: A Multimodal Large Language Model for Financial Chart Analysis." arXiv preprint arXiv:2308.01430 (2023).
8. 风险提示
数据不完备和滥用风险,信息安全风险,算法伦理[文]风险。

报告信息
证券研究报告:《了解GPT:投资篇》
对外发布时间:2023年8月19日
分析师:肖承志
资格编号:S0120521080003
邮箱:xiaocz@tebon.com.cn
报告发布机构:德邦证券股份有限公司
(已获中国证监会许可的证券投资咨询业务资格)
金工团队简介
肖承志,同济大学应用数学本科、硕士,现任德邦证券研究所首席金融工程分析师。具有6年证券研究经历,曾就职于东北证券研究所担任首席金融工程分析师。致力于市场择时、资产配置、量化与基本面选股。撰写独家深度“扩散指标择时”系列报告;擅长各类择时与机器学习模型,对隐马尔可夫模型有深入研究;在因子选股领域撰写多篇因子改进报告,市场独家见解。
&nbs[章]p;林宸星,美国威斯康星大学计量经济学硕士,[来]上海财经大学本科,主要负责大类资产配置、中低[自]频策略开发、FOF策略开发、基金研究、基金经[1]理调研和数据爬虫等工作,2021年9月加入德[7]邦证券。
温瑞鹏,中山大学本科,复旦大学金融学硕士,曾就职于信达证券、东亚前海证券。研究方向:基金研究、基金经理调研。
&nbs[量]p;路景仪,上海财经大学金融专业硕士,吉林大[化]学本科,主要负责基金研究,基金经理调研等工作[ ],2022年6月加入德邦证券。
王治舜,香港中文大学金融科技硕士,电子科技大[ ]学金融+计算机双学士,主要负责量化金融、因子[ ]选股等工作,2023年1月加入德邦证券。
陈曼莲,华南理工大学[1]金融学硕士,电子商务+计算机双学士,主要负责[7]基金研究、基金经理调研等工作,2023年7月[q]加入德邦证券。
MORE
相关阅读
01 策略报告
【德邦金工|年度策略】全球成长股或将迎来绝地反击——德邦金工2023年度策略报告
【德邦金工|中期策略】云销雨霁,尚待黎明20210824
02 每周行情前瞻
北向净买入计算机、机械,国防军工、电新景气度提升居前——德邦金工择时周报20230625【德邦金工|周报】
两市成交额上升,北向净买入电新、电子——德邦金工择时周报20230618【德邦金工|周报】
北向净买入银行、家电,科创50ETF净流入居前——德邦金工择时周报20230611【德邦金工|周报】
两市成交额下降,沪深300ETF净流入居前——德邦金工择时周报20230521【德邦金工|周报】
【德邦金工|周报】北向资金净买入非银、电新,科创50ETF净流入居前——德邦金工择时周报20230514
【德邦金工|周报】北向净买入食饮、银行,科创50ETF净流入居前——德邦金工择时周报20230507
【德邦金工|周报】北向净买入计算机、基础化工,中证1000ETF净流入居前——德邦金工择时周报20230503
【德邦金工|周报】A股整体下跌,电新、银行景气度提升居前——德邦金工择时周报20230423
【德邦金工|周报】北向净买入有色金属,创新药ETF净买入居前——德邦金工择时周报20230416
【德邦金工|周报】本周A股日均成交额超12000亿,电子、计算机融资净流入居前——德邦金工择时周报20230409
【德邦金工|周报】全球股市普涨,计算机行业融资净流入居前——德邦金工择时周报 20230402
【德邦金工|周报】A股整体上涨,计算机、电子融资净流入居前——德邦金工择时周报 20230326
【德邦金工|周报】北向净买入电新、传媒,医疗类ETF净流入居前——德邦金工择时周报20230319
03 大类资产配置观点
04 机器学习专题
【德邦金工|选股专题】中证1000成分股有效因子测试——中证1000指数增强系列研究之一
【德邦金工|选股专题】基于模型池的机器学习选股——德邦金工机器学习专题之五
【德邦金工|选股专题】动态因子筛选——德邦金工机器学习专题之四
【德邦金工|机器学习】基于财务与风格因子的机器学习选股——德邦金工机器学习专题之三
05 金融产品时评
06 金融产品专题
【德邦金工|金融产品专题】后疫情时代,物流行业有望复苏,推荐关注物流ETF ——德邦金融产品系列研究之十八
【德邦金工|金融产品专题】势不可挡,坚定不移走科技强国之路,推荐关注华宝中证科技龙头ETF——德邦金融产品系列研究之十七
【德邦金工|金融产品专题】“抓住alpha,等待beta”,华宝夏林锋主动出击“三年一倍”目标——德邦权益基金经理系列研究之一
【德邦金工|金融产品专题】乘大数据战略机遇,握新时代“价值资产”,推荐关注大数据ETF——德邦金融产品系列研究之十六
【德邦金工|金融产品专题】招商中证1000指数增强——细分赛道下的“隐形冠军”——德邦金融产品系列研究之十五
【德邦金工|金融产品专题】长风破浪,王者归来,纳斯达克100ETF再启航——德邦金融产品系列研究之十四
【德邦金工|金融产品专题】风劲帆满海天远,雄狮迈步新征程,推荐关注军工龙头ETF——德邦金融产品系列研究之十三
【德邦金工|金融产品专题】“小”“智”“造”与大机遇,推荐关注中证1000ETF——德邦金工金融产品系列研究之十二
【德邦金工|金融产品专题】“专精特新”政策赋能,小市值投资瞬时顺势,推荐关注国证2000ETF——德邦金工金融产品研究之十一
【德邦金工|金融产品专题】面向未来30年,布局“碳中和”大赛道,推荐关注碳中和龙头ETF——德邦金工金融产品研究之十
【德邦金工|金融产品专题】互联网东风已至,龙头反弹可期,推荐关注互联网龙头ETF——德邦金融产品系列研究之九
【德邦金工|金融产品专题】需求旺盛供给紧俏,稀土ETF重拾上升趋势——德邦金融产品系列研究之八
【德邦金工|金融产品专题】周期拐点将至,地缘冲突催化行业景气上行,关注农业ETF——德邦金融产品系列研究之七
【德邦金工|金融产品专题】新能源车需求超预期,动力电池新产能涌现,关注锂电池ETF——德邦金融产品系列研究之六
【德邦金工|金融产品专题】稳增长预期下高股息低估值凸显投资价值,关注中证红利 ETF——德邦金融产品系列研究之五
【德邦金工|金融产品专题】文旅复苏之路,价值实现的选择,关注旅游ETF——德邦金融产品系列研究之四
【德邦金工|金融产品专题】市场波动渐增,银行防御价值凸显——德邦金融产品系列研究之三
07 文献精译专题
【德邦金工|文献精译】了解GPT:应用篇——德邦金工文献精译第十二期
【德邦金工|文献精译】了解GPT:训练篇——德邦金工文献精译第十一期
【德邦金工|文献精译】ChatGPT能够预测股票价格的走势吗?收益可预测性和大型语言模型——德邦金工文献精译第十期
【德邦金工|文献精译】只有艰难时期的赢家能重复成功:对冲基金在不同市场条件下的业绩持续性——德邦金工文献精译第九期
【德邦金工|文献精译】训练语言模型以遵循带有人类反馈的指令——德邦金工文献精译系列之八
【德邦金工|Fama因子模型专题】Fama三因子模型问世三十周年系列之二:A股市场实证——德邦金工Fama因子模型专题二
【德邦金工|文献精译】Fama-French三因子模型问世三十周年系列之一:重温经典——德邦金工Fama因子模型专题一
【德邦金工|文献精译】股价是否充分反映了业绩中应计和现金流部分所蕴含的未来盈利信息?——德邦金工文献精译系列之七
【德邦金工|文献精译】资产配置:管理风格和绩效衡量——德邦金工文献精译系列之六
【德邦金工|文献精译】规模很重要,如果控制了绩差股——德邦金工文献精译系列之五
【德邦金工|文献精译】中国股市的规模和价值因子模型——德邦金工文献精译系列之四
【德邦金工|文献精译】机器学习驱动下的金融对不确定性的吸收与加剧——德邦文献精译系列之三
08 选股月报
09 小市值专题
【德邦金工|选股专题】微盘股的拥挤度测算和择时——德邦金工小市值专题之五
【德邦金工|选股专题】微盘股的症结与曙光——德邦金工小市值专题之四
10 行业轮动专题
11 分析师专题
【德邦金工|选股专题】基于事件分析框架下的分析师文本情绪挖掘——分析师专题之一
12 基金策略专题
【德邦金工|金融产品专题】基于主动基金持仓的扩散指标行业轮动及改进—基金投资策略系列研究之一
【德邦金工|金融产品专题】基于扩散指标的主动基金筛选策略——德邦金工基金投资策略系列研究之二
重要说明

本篇文章来源于微信公众号: Zeta金工研究