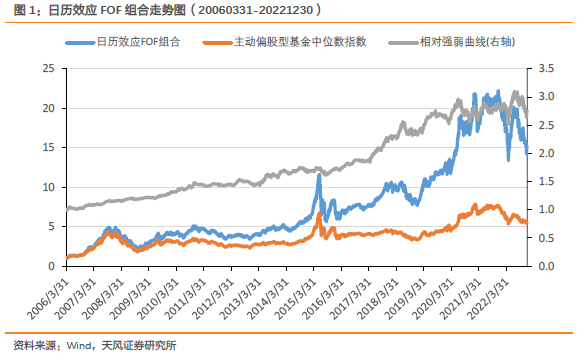
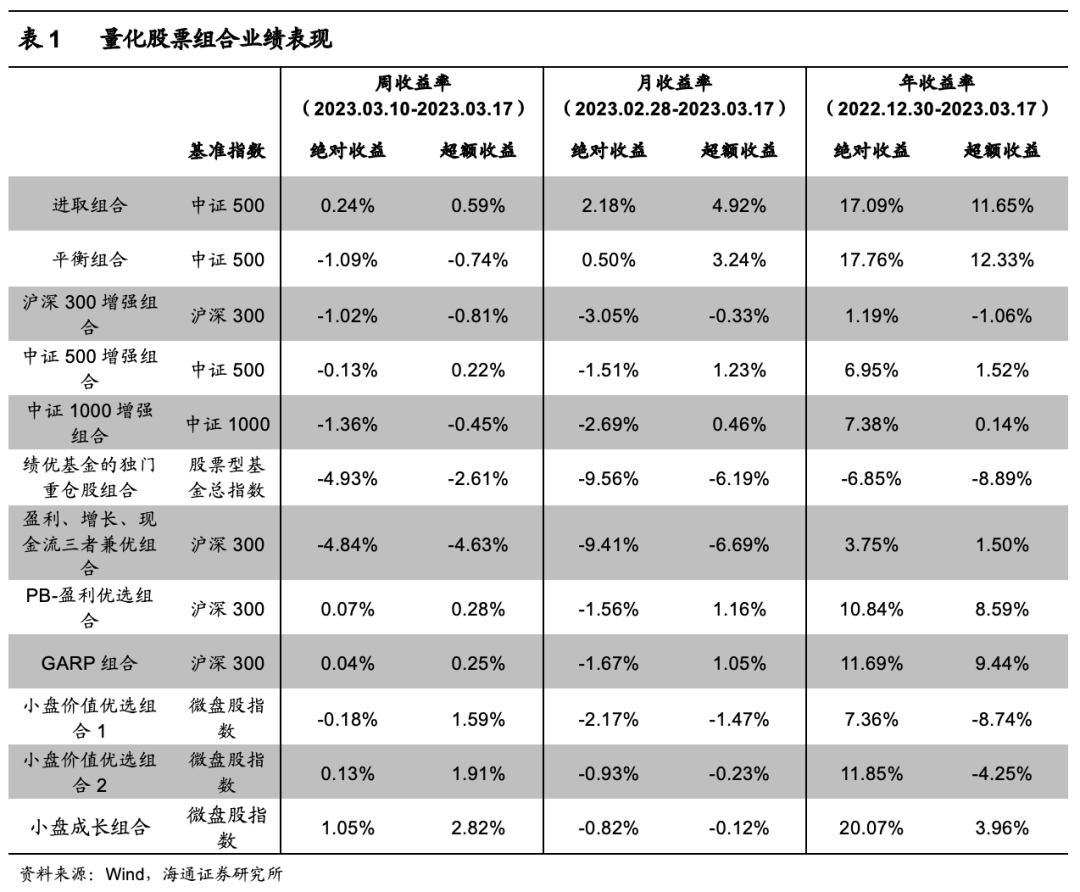
【华安金工】机器学习与基金特征如何选择正 Alpha 基金?——“学海拾珠”系列之一百六十八
►主要观点
01
近期,被动型基金在美国的规模已经超过了主动型基金,许多专家认为,被动型基金的兴起是因为大多数主动管理者长期无法超越费率更低的被动替代品(参见Gittelsohn, 2019)。为了探究是否存在业绩突出的主动管理者,研究人员已经对过去的基金回报是否能预测未来业绩进行了研究。从这些研究中得出的共识是,净Alpha值的持续正增长是不可能的,尤其是在考虑到共同基金回报对市场动量因子的敏感性之后(参见Carhart, 1997)。
Berk和Green(2004)的模型与基金净Alpha缺乏持续性的观点一致。在这个模型中,投资者会根据过去的回报,无限制地向他们认为业绩优异的基金注入资金。如果投资组合管理存在规模报酬递减,在平衡状态下,历史拥有正Alpha的基金会吸引更多资产,从而获得与其他主动基金相同的预期净Alpha:即等于被动基准(零)。然而,信息摩擦可能会阻碍投资者资金的流动,使得基金业绩不会完全趋向于零(参见Dumitrescu和Gil-Bazo, 2018; Roussanov等人, 2021)。因此,共同基金业绩是否可预测,实际上是一个需要经验数据支撑的问题,这一问题在文献中受到广泛关注。有几项研究显示,共同基金的特征可以用来预测基金的业绩;详见Jones和Mo(2020)的综述。通常,这些研究会根据共同基金的特征,每月或每季度对基金进行排名,然后,将资金分配到五组或十组,并评估这些基金组合的多空业绩。然而,过往文献的基金特征中,只有少部分指标在扣除交易成本、费用和其他支出之后仍能选择出正Alpha的多头基金组合,因为基金不能轻易做空,投资者只能通过选择正净Alpha的多头组合来从主动管理中获益。
文献研究方法如下:首先,用到了17个不同的基金特征来预测业绩,更全面地考虑问题的复杂性。基金业绩受到多种因子影响,包括管理者的多方面能力、投资组合约束、管理者激励和代理问题,以及基金的交易成本、费用和其他支出。其次,采用三种机器学习方法来预测基金业绩:弹性网络(elastic net,)、梯度提升(gradient boosting)和随机森林(random forests)。这些方法能够处理不相关或高度相关的预测因子,因此,在考虑多个特征的同时降低过度拟合的风险,这种风险通常低于普通最小二乘法(OLS)。此外,两种基于决策树的方法(梯度提升和随机森林)能够识别非线性和交互作用,可能会发现弹性网络或OLS等线性方法可能错过的可预测性。第三,策略需要可以交易,因此只考虑基金多头组合且仅使用过去的数据来构建,并根据净Alpha评估其未来(样本外)业绩,同时扣除费用、交易成本和其他支出。最后,文献根据基金特征采用动态方法进行组合再平衡,允许特征与业绩之间的关系随时间变化,以适应由投资者学习或市场条件变化而引起的基金业绩决定因子的变化。
文献比较三种机器学习方法、OLS以及两种简单策略(所有基金的等权重和资产加权组合)构建的基金组合的样本外费后业绩。使用1980至2020年期间美国主动管理共同基金的回报和17个特征的月度数据,只考虑无附加费用基金,以确保Alpha是扣除所有成本之后的。使用前10年的数据来训练这三种机器学习方法和OLS,预测未来一年的净Alpha,使用Fama和French(2015)以及动量因子的五因子模型来进行估计。17个基金特征的滞后值为预测因子,多头组合包含预测净Alpha排名前十分之一的基金,并计算该组合在接下来12个月的净回报,对于每一个接下来的年份,将训练样本向前推进一年,构建一个新的前十分之一的基金组合,并跟踪其接下来12个月的净回报。通过这种方式,构建了一个从1990年到2020年的月度样本外净回报时间序列。最后使用了四种不同的模型评估整个样本外时期的组合净Alpha:Carhart(1997)的四因子模型;Fama和French(2015)的五因子模型(FF5)(增加了动量因子的FF5);以及增加了动量和Pástor与Stambaugh(2003)的流动性因子的FF5。
研究有五个主要发现:
1、利用非线性和相互作用能力的两种机器学习方法(梯度提升和随机森林)做出的多头基金组合在扣除所有成本后分别实现了每年2.36%和2.69%的显著净Alpha(基于增加了动量因子的FF5模型评估),这些Alpha值在经济上也具有意义,是样本中平均费率(1.11%)的两倍以上。相比之下,基于线性方法(弹性网络和OLS)的组合只能提供每年1.09%和1.21%的净Alpha,统计意义上与零无显著差异。等权重和资产加权的组合分别实现了−0.22%和−0.44%的每年净Alpha,与现有证据一致。即平均而言,主动管理基金在扣除成本后业绩不及被动基金。换用其他因子模型来评估样本外Alpha时,结果类似。总体来看,尽管例如数据中的预测性指标可以帮助投资者避免业绩不佳的基金,但只有通过非线性和相互作用的机器学习方法(梯度提升和随机森林),投资者才能通过投资于主动管理基金获得显著的正净Alpha。
2、发现机器学习揭示了基金特征与未来业绩之间的非线性关系和相互作用。在非线性机器学习方法中,最重要的特征包括各种过去业绩指标和基金主动程度(fund activeness)的指标。基金主动程度与未来业绩之间存在高度的非线性关系,对于最主动的基金,这种关系显著正向,但对于其他基金则相对平坦,对于主动程度更高的基金来说,过去业绩是一个特别强大的未来业绩预测因子。
3、鉴于非线性机器学习方法中发现了过去业绩与基金主动程度之间相互作用,文献进一步探索双重筛选基金的可能性,即同时考虑业绩指标和基金主动程度,以实现正净Alpha。尽管通过双重筛选能够获得正净Alpha,但这种组合的业绩对过去业绩和基金主动程度的指标极为敏感。且过去业绩和基金主动程度的相对预测能力会随时间发生显著变化,因此,为了实现样本外的超额业绩,投资者应当动态地运用机器学习来识别每个时间点上重要的特征和相互作用。
4、Roussanov等人(2021)曾经使用贝叶斯方法估计基金skill,发现skill分布前10%的基金“太小”,无法抵消其规模报酬递减。文献计算了四种预测方法产生的10%投资组合的平均净skill和基金规模,发现排名前10%的基金“太小”,两种非线性机器学习方法下排名前10%的基金尤其小。这些发现为结果提供了经济学解释:机器学习有助于选择基金不仅因为它可以识别有技能的管理者,且它可以识别技能不完全被规模报酬递减抵消的管理者。
5、第五, Jones and Mo(2020)发现,由于套利活动和基金竞争的增加,基金特征预测业绩的能力随着时间的推移而下降。因此观察1991年至2020年不同投资组合的alpha值变化。发现从1991年到2011年,三个组合(梯度增强、随机森林和OLS)的业绩优于两个朴素投资组合(等权重和资产加权)。然而三个组合的业绩在2012年至2018年与朴素投资组合相似,最后两年(2019、2020年),三个组合都优于两个朴素组合。还发现,非线性机器学习投资组合在不同商业周期和情绪下的表现差异在统计上并不显著。
02
2.2 共同基金特征
关于基金特征,构建一个包含17个特征的数据集,这些特征基于基金的历史回报和其他信息,不依赖于组合持仓信息。
对于第𝑚个月的第𝑖个基金,获取其扣除费用和交易成本后超过无风险利率的回报(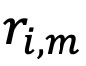 ),总净资产(
),总净资产(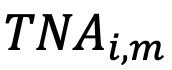 ),费用比率(
),费用比率(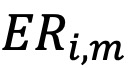 )以及组合换手率等数据。此外,计算基金年龄(即自成立以来的月数)、月度资金流入(即调整费后回报后的TNA相对增长)、资金流入的波动性(即年内流动性的标准差)以及基金经理的任期(以年为单位)。
)以及组合换手率等数据。此外,计算基金年龄(即自成立以来的月数)、月度资金流入(即调整费后回报后的TNA相对增长)、资金流入的波动性(即年内流动性的标准差)以及基金经理的任期(以年为单位)。
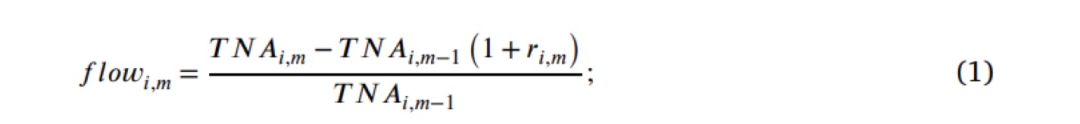 此外,获取回报与Fama和French(2015年)以及动量因子(简称为FF5+MOM)的时间序列回归相关的几个特征。具体而言,对于每个基金份额和每个月,运行一个“滚动窗口”回归,将回报与过去36个月的FF5+MOM因子回报进行回归,计算alpha的t-统计值和beta的t-统计值。选择使用t-统计值而非原始的alphas和betas作为预测因子,是为了考虑到估计误差(参见Hunter等人,2014)。此外,还使用FF5+MOM滚动窗口回归的R²作为基金业绩的一个预测因子。如Amihud和Goyenko(2013)所建议,R²被解释为基金主动程度的衡量指标,因为低R²的基金与基准的跟踪程度较低。文献还计算了第 𝑖 个基金在第 𝑚 个月的月度实现 alpha(
此外,获取回报与Fama和French(2015年)以及动量因子(简称为FF5+MOM)的时间序列回归相关的几个特征。具体而言,对于每个基金份额和每个月,运行一个“滚动窗口”回归,将回报与过去36个月的FF5+MOM因子回报进行回归,计算alpha的t-统计值和beta的t-统计值。选择使用t-统计值而非原始的alphas和betas作为预测因子,是为了考虑到估计误差(参见Hunter等人,2014)。此外,还使用FF5+MOM滚动窗口回归的R²作为基金业绩的一个预测因子。如Amihud和Goyenko(2013)所建议,R²被解释为基金主动程度的衡量指标,因为低R²的基金与基准的跟踪程度较低。文献还计算了第 𝑖 个基金在第 𝑚 个月的月度实现 alpha(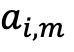 )为:
)为:
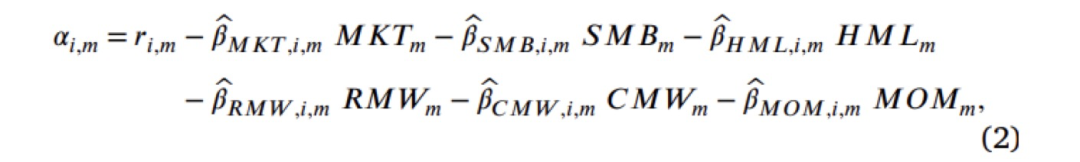
β是第 i 个基金的超额回报相对于 FF5+MOM 因子的因子载荷,使用截至第 m−1 个月的 36 个月估计窗口计算得出。
最后,根据Berk和Van Binsbergen(2015)的定义,使用方程(2)中定义的实现alpha来计算增值(value added)。这个变量旨在捕捉基金经理从市场创造的价值。
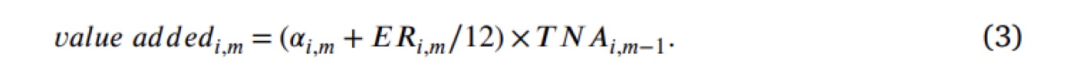
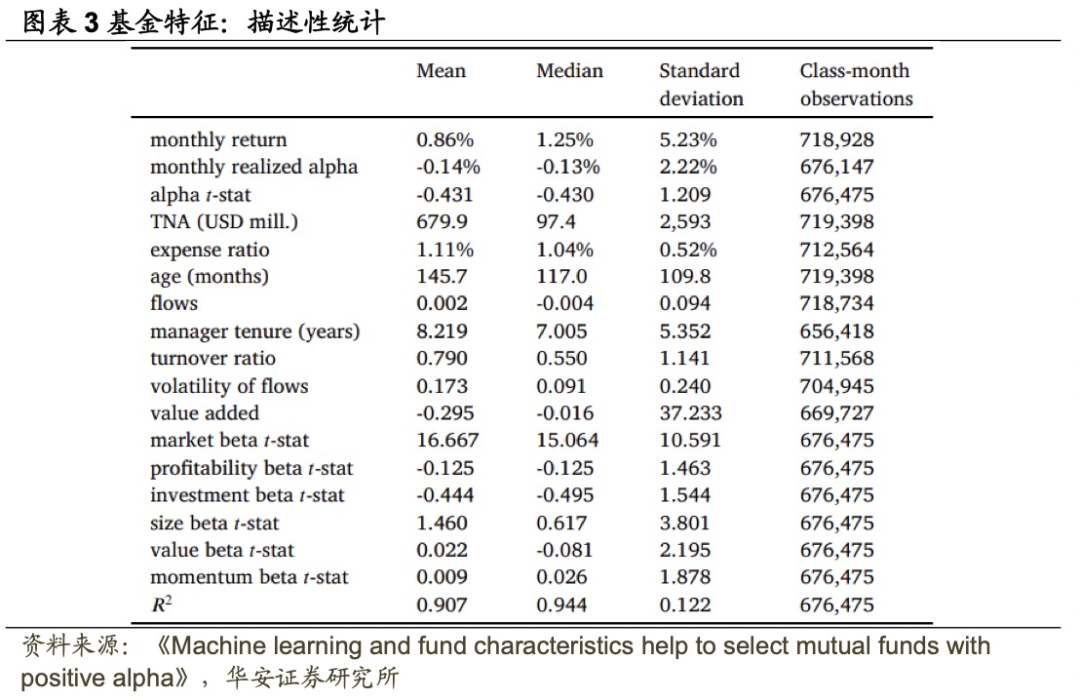
图表2列出了17个特征及其定义。图表3为特征的平均值、中位数、标准差以及观察数。与过往文献一致,样本平均呈现负alpha,平均R²高达90.7%,表明FF5+MOM因子很大程度上解释了股票基金回报的时间序列变化。

2.3 目标与预测变量
本节将17个共同基金特征转换为适用于机器学习的目标和预测变量。首先,将数据从月度频率转换为年度频率,因为一些特征只在季度或年度频率下可用,即使在月度频率下可用的一些特征也非常持久。对于每个日历年,将年度实现alpha、增值和资金流动的月度值平均后乘以12,资金流动波动性将其乘以12的平方根来年化。对于其他所有特征,使用每年12月的值。
其次,对每个特征进行标准化,使其在横截面上具有零均值和单位标准差。这确保了机器学习方法在估计过程中的尺度不变性。将每个标准化特征的缺失观测值设置为其横截面均值(零)。
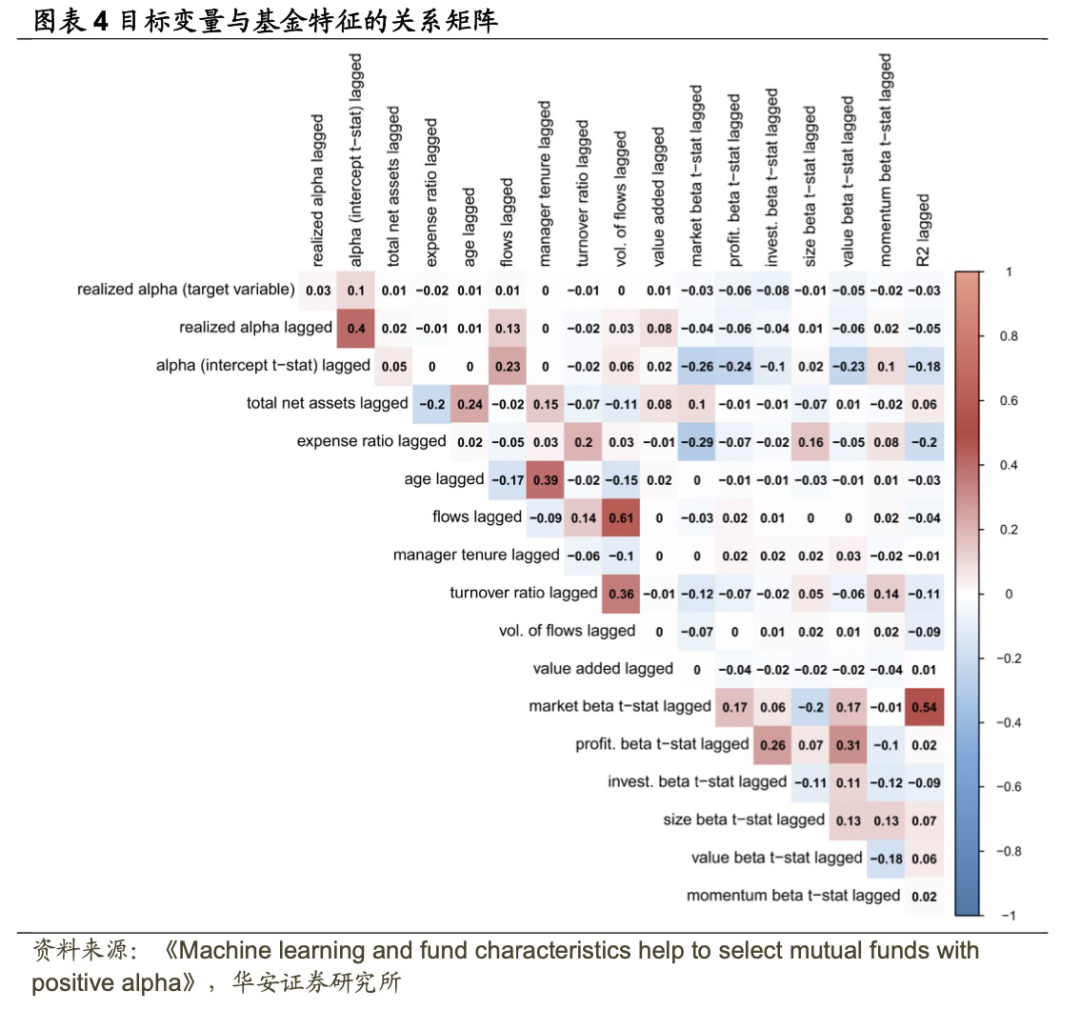
第三,构建了包含目标变量和预测因子的最终数据集。目标变量是每个日历年的已实现alpha。使用的17个预测因子是滞后一年的标准化变量,包括已实现alpha、alpha的t-统计值、TNA、费率、年龄、资金流动、资金流动波动性、管理者任期、增值、R²以及市场、盈利能力、投资、规模、价值和动量beta的t-统计值。图表4为目标变量与滞后预测因子之间的相关性矩阵。目标变量与滞后的预测因子相关性较低。然而,一些预测因子之间存在相当的相关性,其中滞后流动性和流动性波动性之间的绝对相关性最高,为61%。
03
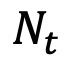 。将普通最小二乘法(OLS)作为基准方法:
。将普通最小二乘法(OLS)作为基准方法: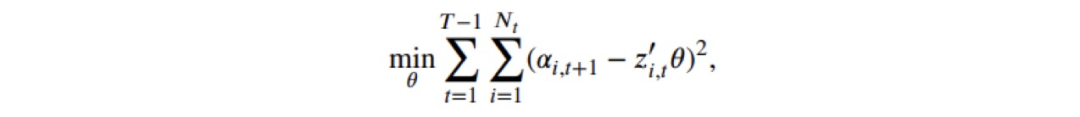
其中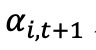 是第 𝑖 个基金在第 𝑡+1 年的实现 alpha,
是第 𝑖 个基金在第 𝑡+1 年的实现 alpha,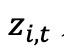 是第 𝑖 个基金在第 𝑡 年的 𝐾 维标准化特征向量,𝜃 是 𝐾 维参数向量。OLS 估计的实现 alpha,
是第 𝑖 个基金在第 𝑡 年的 𝐾 维标准化特征向量,𝜃 是 𝐾 维参数向量。OLS 估计的实现 alpha,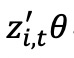 ,是基金特征的线性函数。尽管 OLS 提供了无偏和可解释的预测,但对于展现高方差、非线性和相互作用的数据,机器学习方法通常优于 OLS。
,是基金特征的线性函数。尽管 OLS 提供了无偏和可解释的预测,但对于展现高方差、非线性和相互作用的数据,机器学习方法通常优于 OLS。
文献考虑三种机器学习方法:弹性网络、随机森林和梯度提升。弹性网络是一种类似于OLS的线性方法,但通过正则化来减轻过拟合的风险。而为了捕捉数据的非线性和特征间的相互作用,考虑两种基于决策树的集成方法,即随机森林和梯度提升,这些方法通常在处理结构化(表格)数据时比线性方法更为有效,参见Medeiros等人(2021)的研究。
另外,神经网络作为一种流行的机器学习方法,在处理非结构化数据或高度非线性的结构化数据时表现出色。神经网络通过大量参数来捕捉复杂的非线性关系,但也因此需要大量的数据来获得准确的估计。因此,在本文研究中神经网络可能不如基于树的方法合适。
在具有大量预测变量的数据集中,正则化通常被用来减轻过拟合。Zou 和 Hastie(2005)的弹性网络使用了 1-范数和 2-范数两种正则化项来缩小估计参数的大小。弹性网络的目标函数,带有两个正则化项,为:
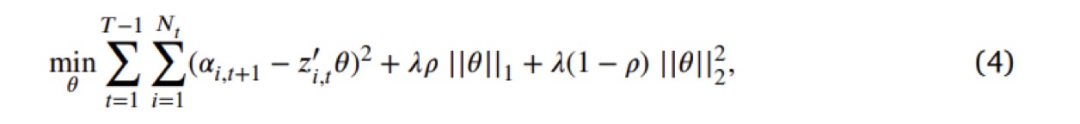
其中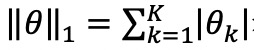 和
和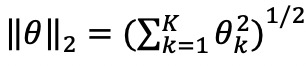 是参数向量 𝜃 的 1-norm和 2-norm,𝜆 和 𝜌 是超参数。1-norm(
是参数向量 𝜃 的 1-norm和 2-norm,𝜆 和 𝜌 是超参数。1-norm(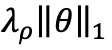 ) 可用于控制估计参数向量 𝜃 的稀疏性,2-norm(
) 可用于控制估计参数向量 𝜃 的稀疏性,2-norm(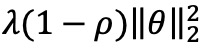 )用于增加其稳定性。当 ρ=0 时,目标函数(4)仅包含2-norm ,此时弹性网络等同于岭回归,它提供了参数向量 θ 的密集估计。另一方面,若 ρ=1,目标函数则只包含1-norm ,相当于执行最小绝对值收缩和选择算子(LASSO)回归,这种情况下提供了一个稀疏估计。第3.4节解释如何校准这两个超参数ρ和 λ。
)用于增加其稳定性。当 ρ=0 时,目标函数(4)仅包含2-norm ,此时弹性网络等同于岭回归,它提供了参数向量 θ 的密集估计。另一方面,若 ρ=1,目标函数则只包含1-norm ,相当于执行最小绝对值收缩和选择算子(LASSO)回归,这种情况下提供了一个稀疏估计。第3.4节解释如何校准这两个超参数ρ和 λ。
随机森林由Breiman(2001)提出,是基于引导聚合算法(bootstrap aggregation)构建的决策树集合。决策树通过递归地将样本分割成同质且不重叠的区域(形似高维盒子)来工作,其生成过程通常以树的形式表示,在每个节点根据该节点最相关的特征来分割样本。树从根节点生长至叶节点,预测值是每个叶节点中目标变量的平均值。
尽管决策树具有很高的可解释性,但由于其预测的高方差,其表现可能不佳。随机森林通过计算森林中众多决策树的预测平均值来降低预测方差。预测方差的减少与树之间的不相关性成反比。为了实现这一点,随机森林采用了引导抽样法(bootstrap sampling)从原始数据中生成多个样本,并在每个树的节点上考虑特征的随机子集。
在本研究中,随机森林方法从原始数据中生成了𝐵 = 1,000个样本。对于每个样本,在每个节点选择𝑚 < 𝐾个特征的随机子集,并从这些𝑚个特征中选择最佳特征来分割样本,从而生成一棵决策树。第3.4节介绍如何调整超参数𝑚。随机森林在存在大量预测变量且这些变量与目标变量之间的关系是非线性的并包含相互作用时,具有优秀的预测表现(参见Medeiros等人,2021;Coulombe等人,2020)。
梯度提升同样基于决策树集合,但与随机森林不同,它不是独立地聚合决策树,而是顺序地聚合它们,以赋予那些之前预测结果较差的数更多权重。梯度提升从弱决策树(预测能力仅略优于随机猜测)开始,逐渐收敛至强树(预测能力更好)。梯度提升通过同时减少预测方差和偏差来改进预测效果(参见Schapire和Freund,2012)。
在梯度提升的每次迭代中,都使用一棵新的决策树来拟合当前集合的残差。这意味着,新的决策树给予那些当前集合预测较差的结果更多权重,然后使用这棵新的决策树来更新集合。梯度提升中的一个关键超参数是学习率,它决定了集合对最新决策树的依赖程度。
不同于随机森林,梯度提升更容易过拟合数据。为了避免这一问题,梯度提升采用了多种正则化技术,并需要调整额外的超参数,例如限制聚合的决策树数量、每棵树的深度、节点数量,以及叶节点中的最小观察数等。
对于每次估计,采用了五折交叉验证(five-fold cross-validation)来调整弹性网络、随机森林和梯度提升的超参数,参考Hastie等人(2009, 第7章)的方法。具体而言,文献为超参数设定了一个可能值的范围网格。将样本分为五个相等的部分(“folds”)。对于每个fold(j从1到5),移除第j个fold,用剩下的4个fold来获取与不同超参数值相对应的预测。然后,在第j个fold上评估与每个超参数值相关的预测误差(即交叉验证误差)。在完成交叉验证的过程后,选择那些最小化平均交叉验证误差的超参数值。
另一种考虑数据时间序列特征的交叉验证方法是时间序列交叉验证,它保留训练样本末尾的一部分用于评估。文献在互联网附录中报告结果,发现五折交叉验证的表现略优于时间序列交叉验证。
04
使用1981年至1990年的前10年数据来训练每种机器学习方法和OLS,然后利用1990年12月的基金特征值(未用于训练)来预测1991年的基金业绩,组建一个由预测业绩排在前10%的基金组成的等权重组合,并追踪其在1991年的12个月内的回报(扣费后的净值)。如果在该期间,组合中的基金从样本中消失,其投资金额会平均分配给剩余基金。对于每个后续年份,将训练样本向前扩展一年,再次训练算法,为下一年做出新的预测,并构建一个新的前10%的基金组合,追踪其在接下来12个月的净回报。通过这种方式,文献构建了一个从1991年1月至2020年12月(共360个月)的前10%的基金组合的样本外月度净回报时间序列。被选入前10%组合的基金平均数量为159,最少为11,最多为326。
为评估前10%基金组合的样本外业绩,对360个样本外月度组合超额回报与同时期的风险因子回报进行时间序列回归。基金组合的alpha为时间序列回归的截距。考虑四因子模型来评估:Carhart(1997)提出的增加动量的Fama和French(1993)三因子模型(FF3+MOM);Fama和French(2015)五因子模型(FF5);增加动量的FF5模型(FF5+MOM);以及增加动量和Pástor和Stambaugh(2003)的总体流动性因子的FF5模型(FF5+MOM+LIQ)。然而,需要注意的是,无论使用哪种情况,基金选择都是基于根据FF5+MOM模型预测的业绩。
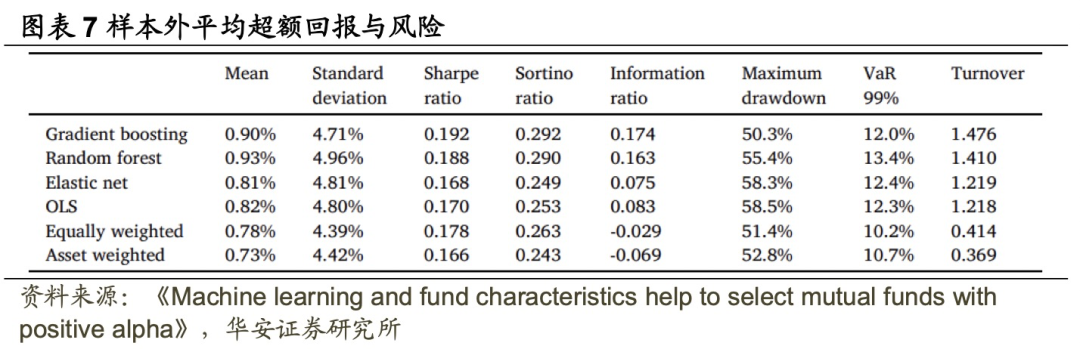
图表5列出了三种机器学习方法(梯度提升、随机森林和弹性网络)以及OLS的前10%基金组合的样本外费后alpha。为了达到比较目的,还展示了两种朴素基金组合的alpha:所有基金的等权组合和资产加权组合,均年度再平衡。
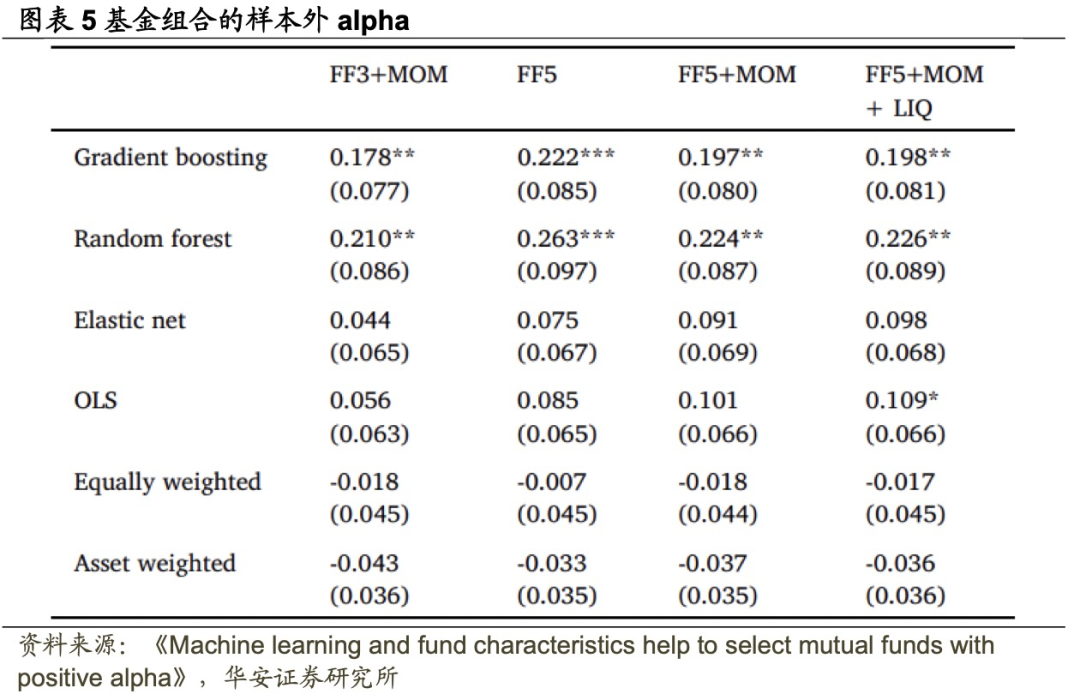
两种机器学习方法(梯度提升和随机森林)选出的多头基金组合在FF5+MOM模型的基准下分别实现了每月19.7个基点(即每年2.36%)和22.4个基点(即每年2.69%)的统计显著净Alpha。相比之下,基于线性方法(弹性网络和OLS)的组合分别实现了每月9.1个基点(即每年1.09%)和10.1个基点(即每年1.21%)的净Alpha,与0的差异在统计意义上不显著。等权重和资产加权组合分别实现了每月-1.8个基点(即每年-0.22%)和-3.7个基点(即每年-0.44%)的负净Alpha。
总体来说,虽然利用数据中的预测性指标确实帮助投资者避免了业绩不佳的基金,但只有通过应用非线性和相互作用的机器学习方法(梯度提升和随机森林),投资者才能显著受益于投资主动管理的基金。当使用其他三个因子模型评估样本外Alpha时,这些结论非常稳定,唯一的例外是在FF5+MOM+LIQ模型下,OLS在10%的统计水平下显著。
梯度提升和随机森林的多头基金组合实现正净Alpha不仅在统计意义上显著,而且在经济上也具有意义。例如,Jones和Mo(2020年)在他们考虑的预测因子排序的基金组合中,前五分之一和后五分之一组合之间的样本内Alpha差值的中位数为每月21.91个基点(每年2.62%),梯度提升和随机森林组合实现的净Alpha与此类似,并且是样本外的,此外,这个值是文献样本中主动基金平均费用率(1.11%)的两倍多。
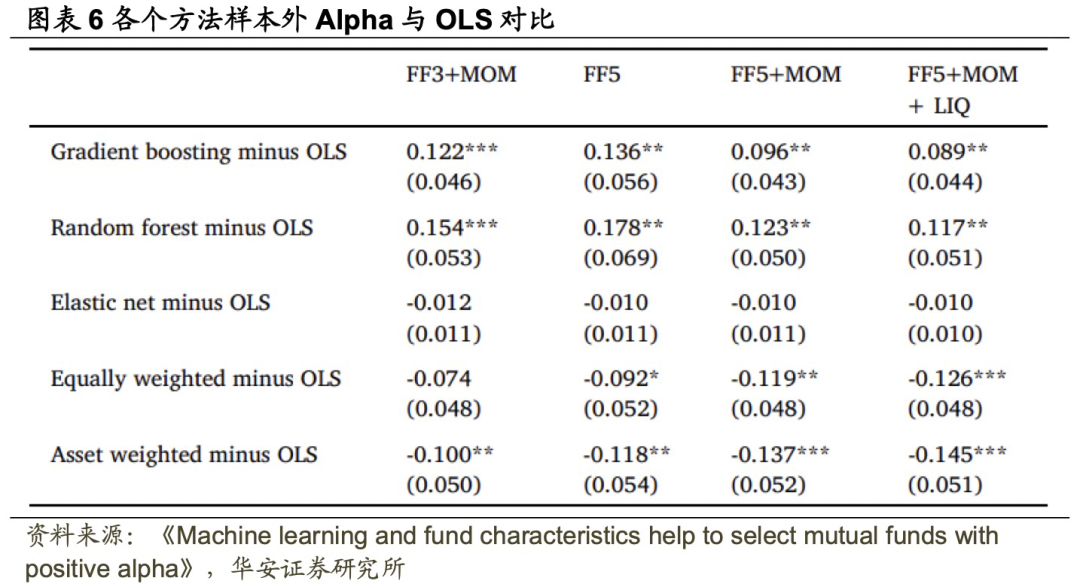
尽管梯度提升和随机森林选出的非线性机器学习组合的Alpha显著不等于零,但是否也显著优于OLS方法仍需评估。在此分析一个组合,该组合做多机器学习方法选出的基金,做空OLS方法选出的基金。图表6显示,梯度提升与OLS组合之间的业绩差异在统计上显著,在四个因子模型下每月差异从8.9个基点到13.6个基点不等(每年1.1%到1.6%)。随机森林组合相对于OLS组合的超额业绩每月在11.7个基点到17.8个基点之间不等(每年1.4%到2.1%)。相反,弹性网络组合在统计上与OLS组合无显著差异。等权和资产加权组合业绩均低于OLS,且差异通常在统计上显著。
图表7报告了每个基金组合的净超额平均回报、净回报的标准差、夏普比率、Sortino比率、信息比率、最大回撤以及基于99%置信度的历史模拟法的在险价值(VaR)。两个最佳方法(梯度提升和随机森林)也提供了夏普比率最高的组合。考虑到下行风险,文献的结论不变:梯度提升和随机森林选择了具有最高Sortino比率的基金组合。在最大回撤方面,弹性网络和OLS选择的组合似乎是具有最高风险的,而在VaR方面,等权和资产加权组合是最安全的。不同组合在信息比率方面的相对业绩与基于净Alpha的业绩密切相关。
了解排名前10%的组合需要进行多少交易是有必要的。图表7的最后一列报告了前10%组合的平均年度换手率(双边)。朴素组合的换手只有20%,主要由于可用基金池的变化和(对于等权重组合)基金价值的变化。相比之下,基于弹性网络和OLS的业绩预测的组合每年交易约60%的组合价值,而基于梯度提升和随机森林则需要交易70%的组合价值。这表明,为了在主动管理的基金中实现优越的业绩,投资组合经理需要在这些基金中进行积极交易,因此,在评估组合业绩时考虑基金佣金是重要的。
综合来看,可以利用现有的基金特征来选择共同基金组合,这些组合在净Alpha方面显著优于等权重或资产加权的组合,即使采用弹性网络和OLS也能达到这一点。但弹性网络和OLS虽然帮助投资者避免了业绩不佳的基金,但并不足以让投资者事前识别出具有显著正净Alpha的基金。只有当允许基金特征与后续业绩之间存在非线性和相互作用时,如梯度提升和随机森林所做的,才能发现具有大量且显著Alpha的基金。
05
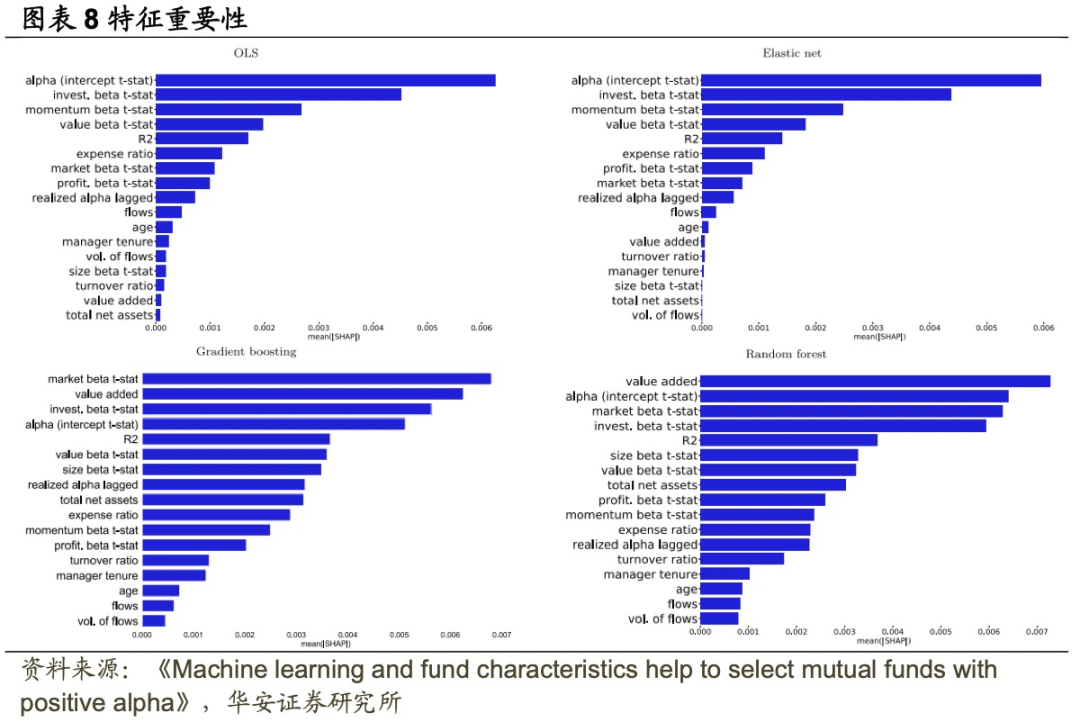
图表8有两个主要发现:首先,value added、Alpha的t-统计值、市场Beta t-统计值和R²是梯度提升和随机森林这两种非线性方法中属于排名前五的最重要的特征。这表明非线性机器学习方法能够利用至少两种不同的过去业绩指标(Alpha截距t-统计值和增值)来预测未来的Alpha。非线性方法还利用基金主动程度来预测未来业绩。例如,市场Beta t-统计值可以被视为基金主动程度的度量,因为不太主动的基金通常具有高度统计显著的Beta。实际上,图表4显示市场Beta t-统计值与R²有54%的高相关性,而Amihud和Goyenko(2013)将R²视为基金主动程度的指标。
其次,非线性和线性方法在特征重要性方面存在显著差异。例如,对于线性方法(如弹性网络和OLS),特征重要性在最重要的两个特征之后迅速下降,而在非线性方法(如梯度提升和随机森林)中,特征重要性的下降则更为平缓,约有七个特征几乎同等重要。一个显著的区别是,在非线性方法中,value added被视为两个最重要的特征之一,而在线性方法中却不那么重要。此外,基金费率是线性方法中的第六大重要特征,但在非线性方法中其重要性较小。
投资者可以利用特征与业绩之间的非线性和相互作用来选择主动管理的股票基金。为了探究这些非线性关系的本质,图表9、图表10展示了梯度提升和随机森林最重要的四个特征的SHAP图:Alpha的t-统计值、value added、市场Beta t-统计值和R²。每个SHAP图中,水平轴表示标准化特征值,垂直轴显示每个观察的特征SHAP值(绿点)和条件均值SHAP值(实心深绿线)。
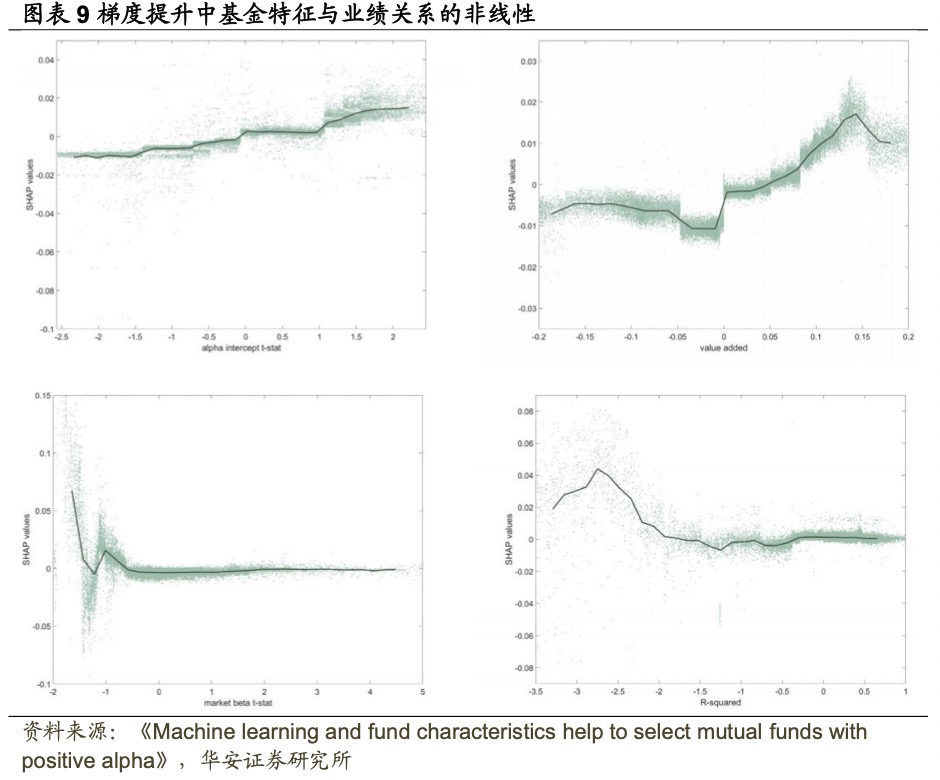
比较图表9、图表10,发现两种机器学习方法识别的非线性模式非常相似。Alpha的t-统计值与其条件均值SHAP值之间存在大致线性的关系,这可能解释了为什么它是两种线性方法中最重要的特征。然而,其他三个特征与未来业绩之间存在显著的非线性关系。例如,基金主动程度与未来业绩之间的关系高度非线性,对于最活跃的基金而言,这种关系强烈正向,但对于其他基金则较为平坦。低市场Beta t-统计值能预测优异的业绩,而高市场Beta t下,Beta t-统计值与未来业绩的关系则是平坦的。同样,R²与业绩之间在-2.75到-2之间的R²值业绩为负相关,但对于标准化R²值高于-2的情况,这种关系基本上是平坦的。最后,value added与其条件均值SHAP值之间的关系在低于-0.06的情况下是平坦的,在中等时呈现U型,在0到0.15之间是单调增加的,而在超过0.15时则是下降的。
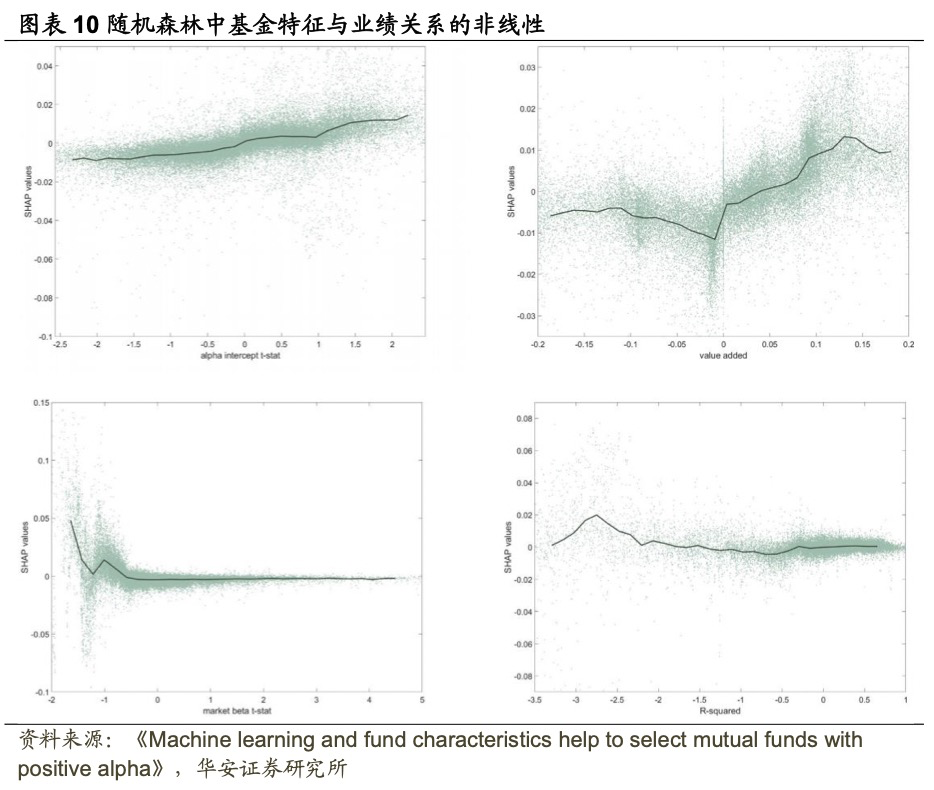
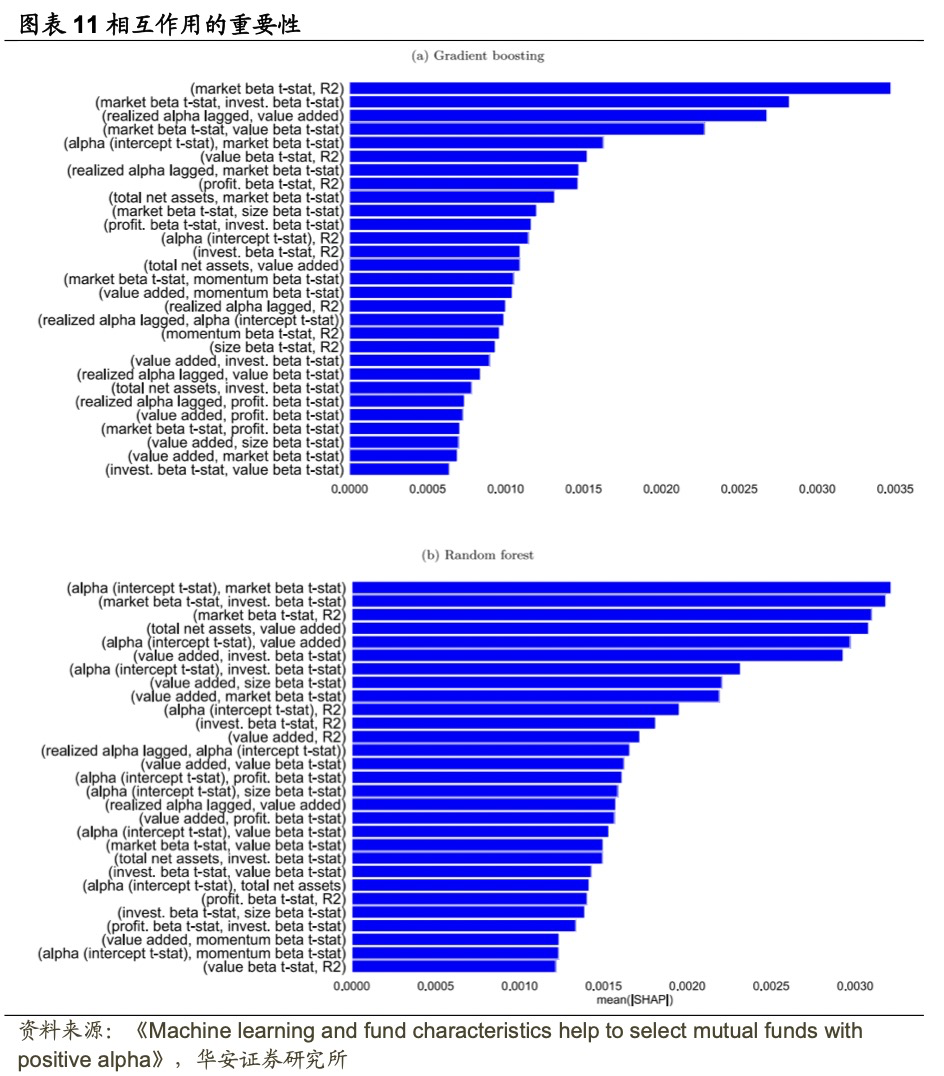
本节还研究了相互作用的重要性。图表11展示了梯度提升和随机森林中30个最重要特征相互作用的强度。Alpha截距t-统计值和value added不仅是独立的预测因子,而且它们与市场Beta t-统计值和R²这类基金主动程度的相互作用至关重要。例如,随机森林中最重要的相互作用是Alpha截距t-统计值与市场Beta t-统计值之间的关系。
综合来看,Alpha截距t-统计值对于更主动的共同基金是未来业绩的特别强大的预测因子,类似地,Alpha截距t-统计值特别有助于预测低R²的基金的未来业绩,即那些回报无法由常见风险因子解释的基金。
鉴于以上结论,探讨是否可以通过基于过去业绩和基金主动程度的双重筛选策略来获得正净Alpha。在样本外期间的每年初,首先根据前一年的业绩指标对所有基金进行排序,并选择排名在前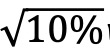 的基金。然后根据前一年末的主动程度对选定的基金进行排序,并选择排名在后
的基金。然后根据前一年末的主动程度对选定的基金进行排序,并选择排名在后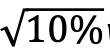 的基金,构建了一个包含10%基金的组合。图表12为该组合Alpha的月度值。
的基金,构建了一个包含10%基金的组合。图表12为该组合Alpha的月度值。
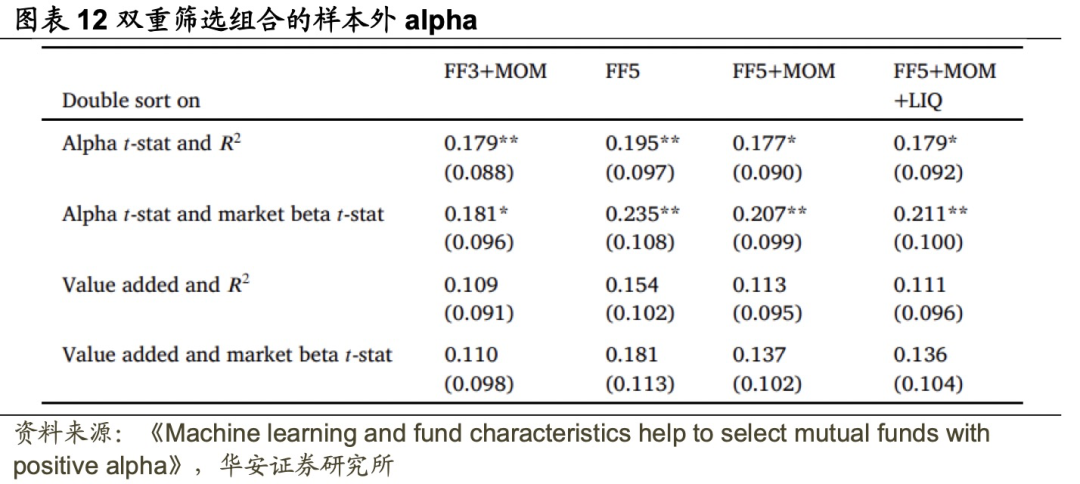
基于过去业绩和基金主动程度的双重筛选策略,确实可以实现正净Alpha。例如,结合Alpha t-统计值和R²形成的基金多头组合的Alpha,在10%的水平显著,尽管这一水平略低于非线性机器学习方法在图表5达到的水平。更引人注目的是,基于Alpha t-统计值和市场Beta t-统计值的双重筛选策略形成的基金组合所实现的Alpha在5%的统计水平上显著,与非线性机器学习方法实现的Alpha相当。这一结果验证了Amihud和Goyenko(2013)记录的R²与过去业绩的相互作用的重要性,并揭示了市场Beta t-统计值作为另一种基金主动程度指标的重要性,以及其与过去业绩的相互作用对于识别业绩优异的基金的重要作用。
然而,基于value added和市场Beta t-统计值或R²的双重筛选组合的样本外净Alpha与0无显著差异,且远小于非线性机器学习组合。此外,需要注意的是,图表12中的结果可能存在前视偏差,因为用于双重筛选的特征组合是基于整个样本期间计算的特征和相互作用的重要性选择的。尽管基于简单的双重筛选策略可以实现良好的样本外业绩,但投资者应动态地使用非线性机器学习方法,以在每个时间点(仅基于过去的数据)识别相关的特征和相互作用,从而实现更优的业绩。
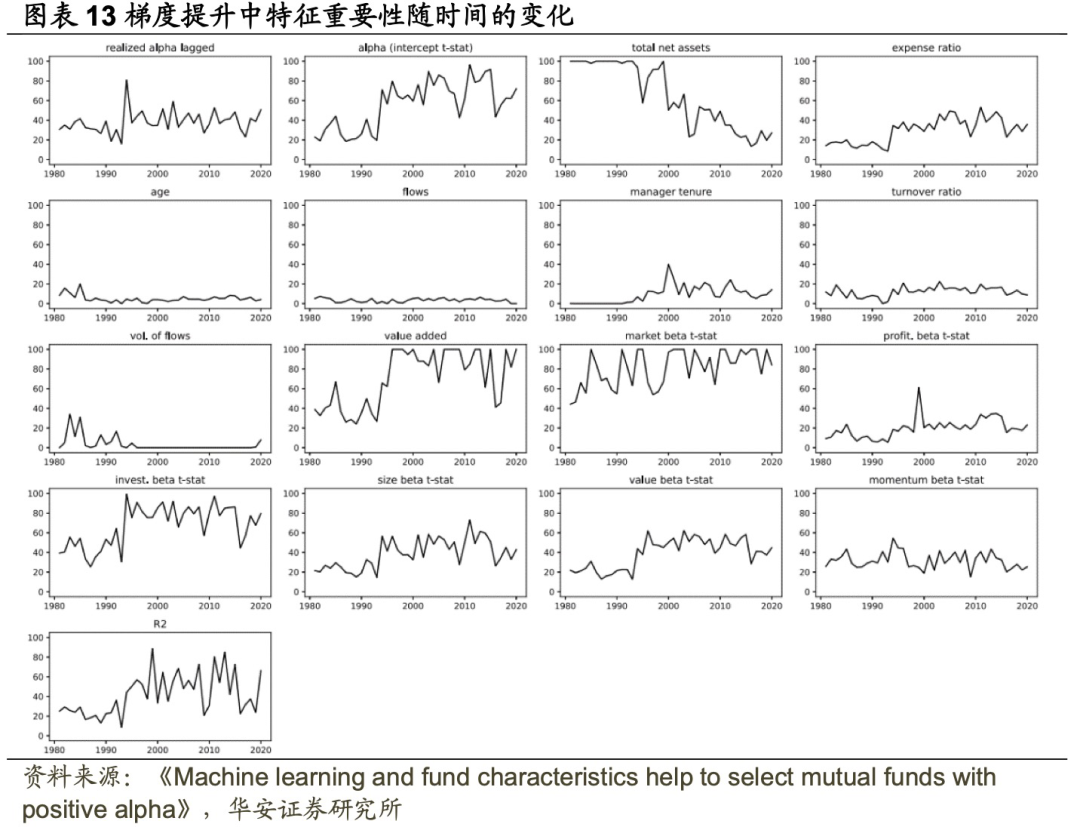
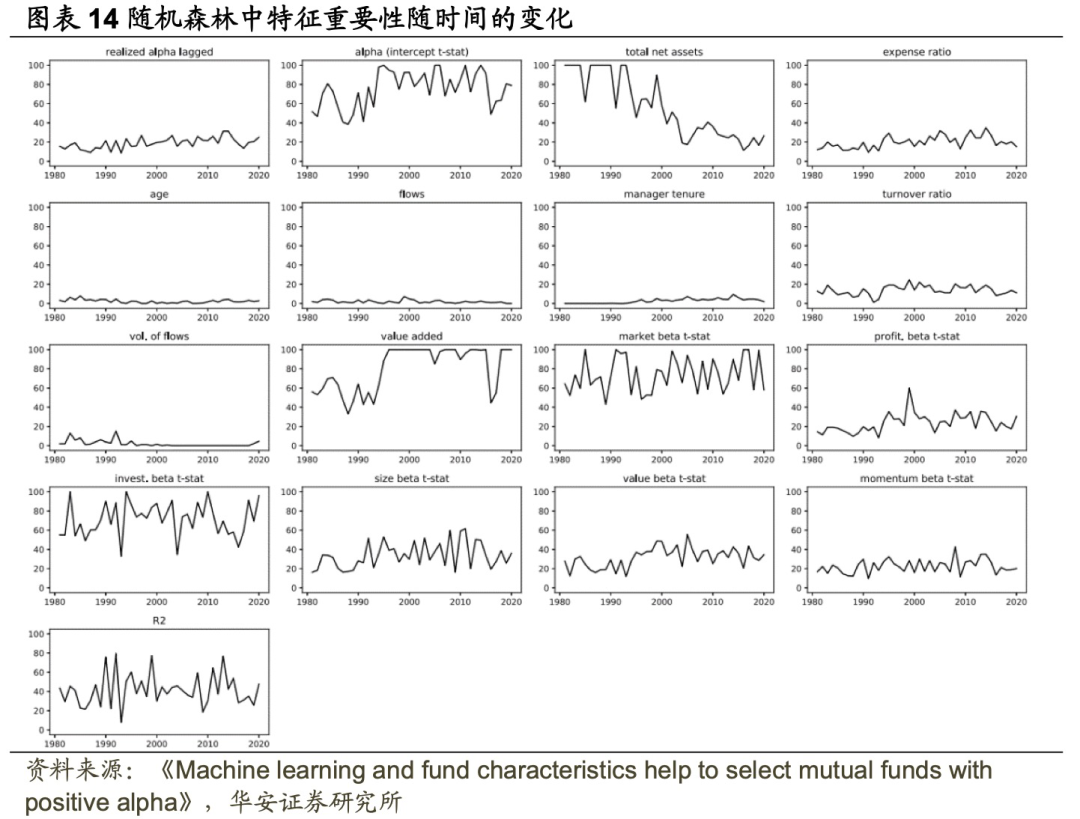
图表13、图表14分别展示了梯度提升和随机森林在样本外期间每年中每个预测因子的重要性,诸如Alpha t-统计值、value added和R²等特征的重要性随时间发生了显著变化。
06
基金投资者是否能通过投资主动型基金获得正净Alpha的问题一直受到学者、业界从业者和监管机构的广泛关注。本研究指出,文献中普遍存在的悲观观点可能源于对基金业绩可预测性方法的限制。本文展示了机器学习方法如何动态地识别和利用基金特征与业绩之间的非线性和相互作用,进而帮助投资者选择能够在扣除佣金和交易成本后仍保持正Alpha的基金。过去业绩指标和基金主动程度之间的相互作用对于预测未来基金业绩至关重要:投资者确实可以从主动管理型的共同基金中受益,前提是他们有能力借助捕捉基金特征与业绩之间复杂关系的高级预测方法。
文献来源:
风险提示
文献结论基于历史数据与海外文献进行总结;不构成任何投资建议。
往期报告
50.《投资者评价基金时会考虑哪些因素?》
142.《多只新股上市首日涨幅超100%,情绪维持”高温“》
138.《新股市场受资金追捧,打新收益陡升》
122.《科创板新股首日涨幅回暖,首批注册制主板新股迎来上市》
49.《多只新股破发,打新收益曲线调整》
43.《打新账户数量企稳,预计全年2亿A类收益率11.86%》


有态度的金融工程&FOF研究

本篇文章来源于微信公众号: 金工严选