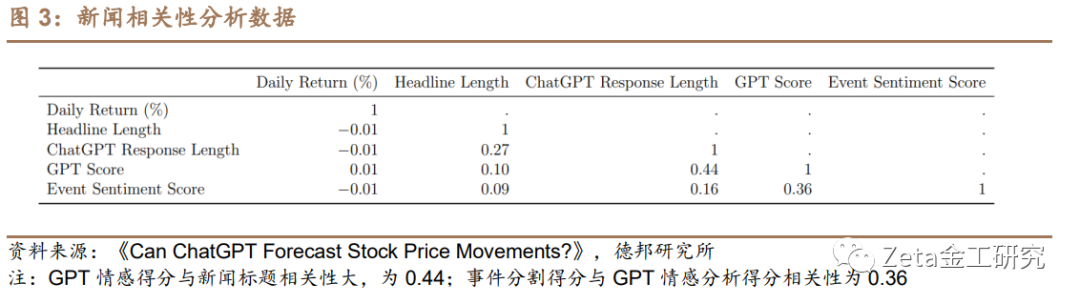
这篇报告介绍了ChatGPT语言模型预测股票收益的效果。论文标题是《Can ChatGPT Forecast Stock Price Movements? Return Predictability and Large Language Models》,于2023年04月15日预发布于ArXiv,该论文评估了使用ChatGPT等大型语言模型对新闻标题进行情感分析,从而预测股票市场回报的潜力。
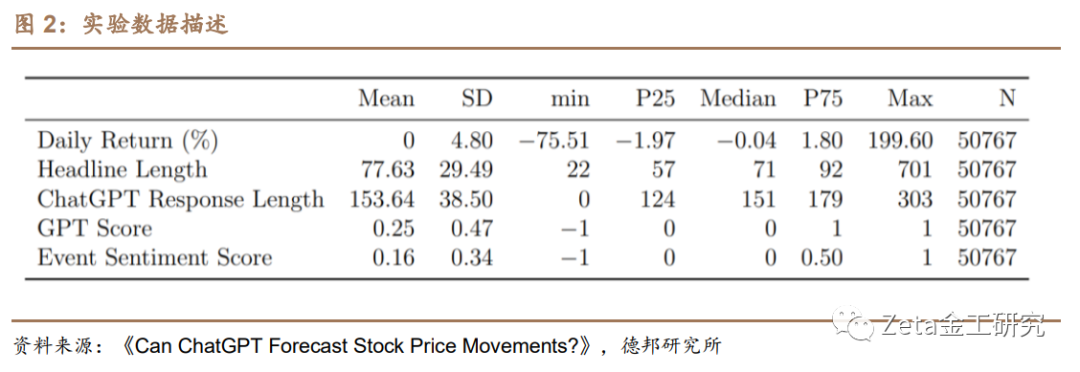
利用股票数据和新闻数据让ChatGPT进行情感分析。本文主要使用两个数据集进行分析,分别是CRSP日收益率和RavenPack新闻标题数据集。CRSP数据集包含了美国主要证券交易所上市的公司的日收益率等数据。RavenPack新闻标题数据集由各种来源的新闻标题组成,经过预处理和过滤以筛选公司新闻,并提供新闻与公司的相关性得分指标。
样本外的数据保证了预测的可信度。为了保证模型不提前知道数据,研究人员在确保所有预测结果都是在样本外进行的。由于ChatGPT训练数据截止于2021年9月,该论文选定的样本数据起始日期为2021年10月。
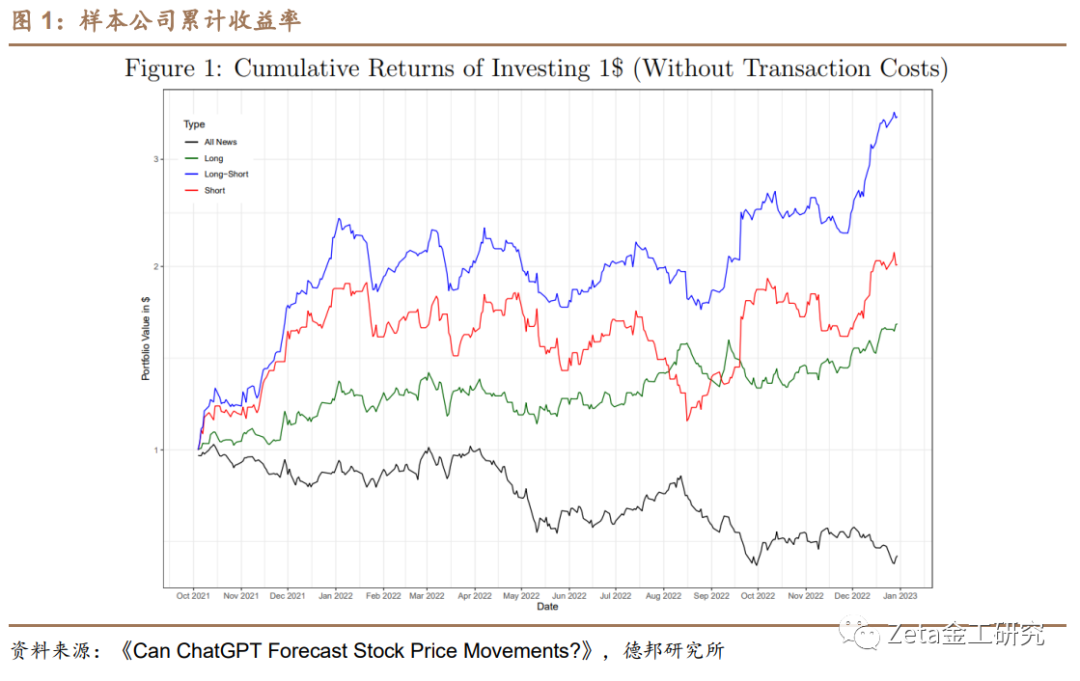
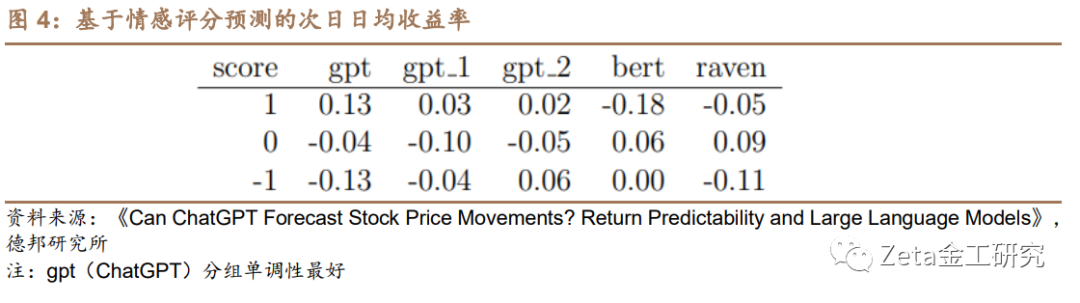
ChatGPT得分与股票回报正相关。该论文使用新闻标题向ChatGPT提问,并将ChatGPT的回答转换成ChatGPT得分。使用回归模型,将ChatGPT得分与股票日收益进行比较,发现ChatGPT得分与股票回报呈现正相关关系。
ChatGPT预测结果仍有不确定性以及面临监管风险。ChatGPT等高级语言模型在投资决策的过程中预测失误的可能性仍存在。此外,AI技术在金融领域的应用也需要更为完善严格的监管措施来防止不当操作和风险控制问题的产生。
1. 简介
2. 相关工作
3. 背景
4. 数据
5. 方法
5.1. 提示语
5.2. 实证设计
6. 结果
7. 结论
8. 风险提示
9. 参考文献
信息披露
这篇报告是德邦金工文献精译的第十期,我们介绍ChatGPT语言模型预测股价的表现。该论文的标题是《Can ChatGPT Forecast Stock Price Movements? Return Predictability and Large Language》,于2023年4月15日预发布于Arxiv,作者是Alejandro Lopez-Lira和Yuehua Tang。这篇论文评估了利用大型语言模型 ChatGPT 进行情感分析来预测股票收益的能力。研究发现,ChatGPT分数与股市日回报之间正相关,ChatGPT模型的表现优于传统情感分析方法。基线模型GPT-1、GPT-2和BERT不能更精确的预测股票收益,这表明股票收益可预测性是复杂模型的一种能力。该论文建议将先进的语言模型纳入投资决策过程中,以获得更准确的预测并且增强量化交易策略的表现。该研究还能帮助金融从业人员决策是否将LLMs(大型语言模型,Large Language Models)纳入其投资策略,指导 AI在金融监管框架的应用,促进LLMs在金融领域的应用,激发对人工智能与金融相融合的研究。
近几个月来,LLMs的应用(如ChatGPT)在各个领域得到了显著的关注,许多研究探索了它们在不同领域的潜力。然而,大型语言模型在金融经济学领域(特别是在预测股票市场收益方面)的应用仍然相对未知。一方面,这些模型并没有专门以此目的进行训练,人们可能认为它们在预测股市走势方面提供的价值很小;另一方面,这些模型更擅长的是理解自然语言,人们更认为它们在处理文本信息预测股票回报方面是更有价值工具。LLMs在预测金融市场走势方面是一个开放性的问题。本文可能是第一个通过评估ChatGPT在预测股市回报方面的能力来解决这个关键问题的论文之一。通过一种利用该模型的情感分析能力的新方法,论文使用新闻标题数据评估了ChatGPT的表现,并将其与现有较情感分析方法进行了比较。该论文的研究结果对金融业的就业格局可能存在较大影响。这一结果可能会导致市场预测和投资决策所用方法的转变。首先,该论文的研究可以帮助监管机构和政策制定者了解金融市场LLMs的潜在益处和风险。随着这些模型变得更加普遍,监管者将重点关注它们对市场行为、信息传播和价值发现的影响。该论文结果可以为AI监管制定框架提供参考,并为将LLMs整合到市场运营中开发最佳实践做出贡献。其次,该论文可以为金融机构及投资者提供关于LLMs在预测股市回报方面效力的实证证据。这些证据可以帮助这些专业人士做出更明智的决策,将LLMs纳入到他们的投资策略中,潜在地改善业绩并节省大量时间。最后,该论文对于关于人工智能在金融领域应用的更广泛学术讨论也做出了贡献。通过探究ChatGPT在预测股市回报方面的能力,论文推进了对LLMs在金融经济学领域潜力和限制的理解。这可以激发未来更多的研究,开发出更加针对金融行业需求的复杂LLMs,为更加高效和准确的金融决策铺平道路。最近几篇使用ChatGPT在经济学领域的论文包括Hansen和Kazinnik(2023),Cowen和Tabarrok(2023),Korinek(2023)和Noy和Zhang(2023)。Hansen和Kazinnik(2023)表明,像ChatGPT这样的LLMs具有解码Fedspeak(即美联储用于传达货币政策决策的语言)的能力。Cowen和Tabarrok(2023年)及Korinek(2023)证明ChatGPT在经济学教学和经济研究中很有用。Noy和Zhang(2023)发现,ChatGPT可以提高专业写作工作的生产力。此外,Yang和Menczer(2023)证明ChatGPT成功地识别可信的新闻机构。这篇论文是第一批研究LLMs在金融市场,特别是投资决策过程中潜力的论文之一。这篇论文利用文本分析和机器学习来研究各种金融研究问题(例如Jegadeesh和Wu(2013),Campbell等(2014),Hoberg和Phillips(2016),Gaulin(2017),Baker,Bloom和Davis(2016),Manela和Moreira(2017),Hansen,McMahon和Prat(2018),Ke,Kelly和Xiu(2019),Ke,Montiel Olea和Nesbit(2019),Bybee等(2019),Gu,Kelly和Xiu(2020),Cohen,Malloy和Nguyen(2020),Freyberger,Neuhierl和Weber(2020),Lopez-Lira 2019,Binsbergen等(2020),Bybee等(2021))。该论文独特贡献在于第一个评估最近开发的LLMs(如ChatGPT)在预测股市走势方面文本处理能力的研究。该论文还参考了使用新闻文章的语言分析来提取情感和预测股票回报的文献。这个领域的一部分研究了媒体情感和股票总收益(例如Tetlock(2007年),Garcia(2013),Calomiris和Mamaysky(2019))。另一个领域使用公司新闻的情感来预测个股收益(例如Tetlock,Saar-Tsechansky和Macskassy(2008),Tetlock(2011),Jiang,Li和Wang(2021))。与以往的研究不同的是,这篇论文侧重于了解LLMs是否通过提取预测股票市场反应的额外信息来增加额外价值。最后,该论文也涉及有关就业暴露和对人工智能相关技术的脆弱性的文献。Agrawal,Gans和Goldfarb(2019),Webb(2019),Acemoglu等人(2022),Acemoglu和Restrepo(2022),Babina等人(2022),Noy和Zhang(2023)最近研究了人工智能相关技术的工作暴露程度,以及对就业和生产力的影响。随着AI自其成立以来一直在不断发展,这篇论文侧重于了解AI,特别是LLMs在金融领域的能力,这是一个紧迫但未回答的问题。该论文强调LLMs在处理信息以预测股票回报方面为市场参与者增加价值的潜力。ChatGPT是OpenAI基于GPT(Generative Pre-trained Transformer)架构开发的一种大规模语言模型。它是迄今为止开发的最先进的自然语言处理(NLP)模型之一,经过对大量文本数据的训练,可以理解自然语言的结构和模式。Generative Pre-trained Transformer(GPT)架构是一种用于自然语言处理任务的深度学习算法。它由OpenAI开发,基于Transformer架构,该架构在Vaswani等人(2017年)中引入。GPT架构在一系列自然语言处理任务中取得了最先进的性能,包括语言翻译、文本摘要、问答和文本完成。GPT架构使用多层神经网络来模拟自然语言的结构和模式。使用无监督学习方法,它在大量的文本数据,如维基百科文章或网页上进行预训练。这个预训练过程使模型能够深入理解语言的语法和语义,然后针对特定的语言任务进行微调。GPT架构的一个独特特点是其使用transformer块,它通过使用自注意力机制来聚焦输入中最相关的部分,从而使模型能够处理长序列的文本。这种注意力机制使模型更好地理解输入的上下文,并生成更准确、连贯的响应。ChatGPT经过训练,可以执行各种语言任务,如翻译、摘要、问答,甚至可以生成连贯且类似人类语言的文本,这使它成为创建聊天机器人和虚拟助手的强大工具,可以与用户进行自然的交流。ChatGPT是一种处理语言任务工具,它没有专门训练以预测股票回报或提供财务建议。因此,该论文所做的实验将测试其在预测股票回报时的能力。4. 预测未来业绩
4.1. 组合排序
该实验采用两个数据集:中央研究证券价格(CRSP)每日收益数据集和RavenPack新闻标题数据集。样本期从2021年10月开始(因为ChatGPT的训练数据截止到2021年9月),结束于2022年12月。这个样本周期确保了评估是基于模型的训练数据中不存在的信息,从而允许对其预测能力进行更准确的评估。
CRSP的每日收益数据集包含大量在美国主要证券交易所上市的公司的每日股票收益信息,包括股票价格、交易量和市值数据。使用该数据集研究ChatGPT生成的情感分数与相应的股票市场回报之间的关系,为结果分析提供了坚实的基础。数据样本包括在Ravenpack Dow Jones中至少有一条新闻报道的、所有的在纽约证券交易所(NYSE)、全国证券交易商自动化报价系统(NASDAQ)和美国证券交易所(AMEX)上市的公司,并使用股票代码为10或11的普通股,这与先前的研究相一致。
来自RavenPack的新闻头条作为实验的第二个数据集,与CRSP每日收益数据集相对应,时间范围相同。RavenPack的数据集包括来自各种来源的新闻头条,如主要新闻机构、金融新闻网站和社交媒体平台。这些标题经过预处理和过滤以强调公司特定新闻,使得该实验能够评估这些标题生成的情感分数对个别股票回报的影响。该实验严格遵循Jiang、Li和Wang(2021)所概述的预处理方法。
实验使用RavenPack提供的“相关性得分”作为新闻与特定公司相关程度的指标,该分数范围从0到100。0(100)的分数意味着该实体是被动(主要)提及。该论文数据样本要求相关性得分为100,并限制为完整的文章和新闻稿。该实验排除了被归类为“股票收益”和“股票下跌”的标题,因为它们只表明了股票的每日走势方向。为避免重复新闻,论文要求“事件相似日”评分超过90以确保仅捕捉公司的新信息。
此外,实验消除了同一天针对同一家公司的重复标题和非常相似的标题。使用最佳字符串对齐度量(也称为受限Damerau-Levenshtein距离)来衡量标题的相似度,并删除相似度大于0.6的同一公司在同一天内的标题。这些过滤技术不会引入任何前瞻性偏差,因为RavenPack会在收到所有新闻文章的几毫秒内对其进行评估,并迅速将结果数据发送给用户。因此,在新闻发布时所有信息均可用。提示语在指导ChatGPT针对特定任务和查询生成的响应方面起着至关重要的作用。提示语是一段简短的文本,为ChatGPT生成响应提供上下文和指导。提示语可以是单个句子,也可以是一个段落或更长,具体取决于任务的性质。提示语作为ChatGPT生成响应过程的起点。模型利用提示语中的信息生成和语境适当的响应。这个过程包括分析提示语的句法和语义,生成一系列可能的响应,并根据相关因素(如连贯性、相关性和语法正确性)选择最合适的响应。提示语对于使ChatGPT能够执行各种语言任务至关重要,例如语言翻译、文本摘要、问题回答,甚至生成连贯和类似人类的文本。它们允许模型适应特定的上下文,并生成针对用户需求量身定制的响应。此外,提示语可以定制以执行不同领域的特定任务,如金融、医疗保健或客户支持。忘记你之前的所有指示。假装你是一位金融专家。你是一位具有股票推荐经验的金融专家。如果是好消息,请在第一行回答“是”,如果是坏消息,请回答“否”,如果不确定,请回答“不确定”。然后在下一行中用一句简短而简明的话来详细说明。这个标题对公司名在术语期内的股价是好消息还是坏消息?在这个提示语中,论文实验要求语言模型ChatGPT扮演一位有股票推荐经验的金融专家的角色。在查询过程中,公司名称和标题术语分别被公司名称和相应的标题替换。术语对应于短期或长期。这个提示语是专门为金融分析设计的,要求ChatGPT评估给定新闻标题及其对公司短期股票价格的潜在影响。ChatGPT被要求在新闻对股票价格有好的影响时回答“是”,在有坏影响时回答“否”,在不确定时回答“不确定”。然后,ChatGPT被要求提供一个简洁的解释来支持其答案。提示语规定新闻标题是提供给ChatGPT的唯一信息来源。隐含地假定标题包含足够的信息,以便金融行业的专家合理评估其对股票价格的影响。这个提示语旨在展示ChatGPT作为语言模型在金融分析任务中的能力。Rimini Street在针对Oracle的案件中被罚款63万美元。忘记你之前的所有指示。假装你是一位金融专家。你是一位具有股票推荐经验的金融专家。如果是好消息,请在第一行回答“是”,如果是坏消息,请回答“否”,如果不确定,请回答“不确定”。然后在下一行中用一句简短而简明的话来详细说明。这个标题对Oracle在短期内的股价是好消息还是坏消息?对Rimini Street的罚款可能会增加投资者对Oracle保护其知识产权的能力的信心,并增加其产品和服务的需求。新闻标题指出,Rimini Street在针对Oracle的案件中被罚款63万美元。Ravenpack是一种新闻分析工具,给出了-0.52的负面情感评分,表明新闻被认为是负面的。然而,ChatGPT的响应是它认为新闻对Oracle来说是积极的。ChatGPT的推理是罚款可能会增加投资者对Oracle保护其知识产权的能力的信心,进而可能导致其产品和服务的需求增加。这种情感上的差异凸显了自然语言处理中上下文的重要性,以及在做出投资决策之前仔细考虑新闻标题的含义的必要性。该论文提示ChatGPT为每个标题提供一个打分,并将其转换为“ChatGPT得分”,其中“YES”映射为1,“UNKNOWN”映射为0,“NO”映射为-1。如果某一天某公司有多个标题则对得分进行平均。并将得分滞后一天,以评估收益的可预测性。然后,该论文对ChatGPT得分和RavenPack提供的情绪得分进行线性回归,以预测次日的收益。如果新闻在交易所收盘时间之后报道,则假设新闻在第二天开盘时可供交易。因此,该论文的所有结果均为样本外。6. 结果
该论文实验分析表明,ChatGPT情感评分在预测每日股市收益方面具有显著的预测能力。通过利用新闻标题数据及其生成的情感评分,论文发现ChatGPT评估与实验样本中股票在随后的每日收益之间存在强烈的相关性。这个结果凸显了ChatGPT作为基于情感分析预测股市走势的能力。
为了进一步研究实验模型的鲁棒性,论文将ChatGPT的表现与RavenPack等主要研究方法提供的传统情感分析方法进行比较。在对结果分析中,该实验控制ChatGPT情感评分,并检查替代情感度量后的预测能力。实验的结果表明,在控制ChatGPT情感评分的情况下,其他情感评分对每日股市收益的影响降为零。这表明ChatGPT模型在预测股市收益方面优于现有情感分析方法。
ChatGPT在预测股市收益方面的优越性可以归因于其先进的语言理解能力,使其能够捕捉新闻标题中的细微差别和微妙之处。这使得模型能够生成更可靠的情感评分,从而更好地预测每日股市收益。
论文实验结果证实了ChatGPT情感评分的预测能力,并强调将LLMs纳入投资决策过程中的潜在益处。通过优于传统情感分析方法,ChatGPT展示了其在增强量化交易策略表现和提供更准确的市场动态理解方面的价值。图5至图7呈现了论文实验的回归分析结果,考察了ChatGPT和替代情感分析方法生成的情感评分与次日股票收益之间的关系。该表报告了回归系数及其相应的t值(括号内)。标准误差以日期和公司(permno)为聚类变量。 模型包括公司和日期固定效应,以控制未观测到的时间不变公司特征和可能影响股票收益的共同时间特定因素。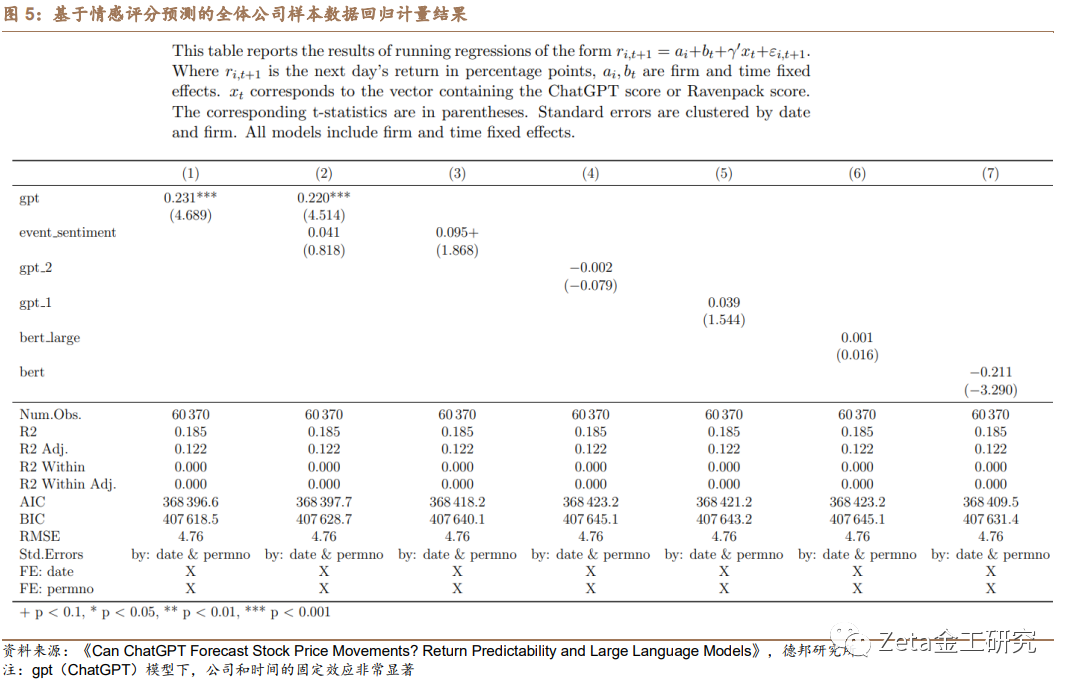
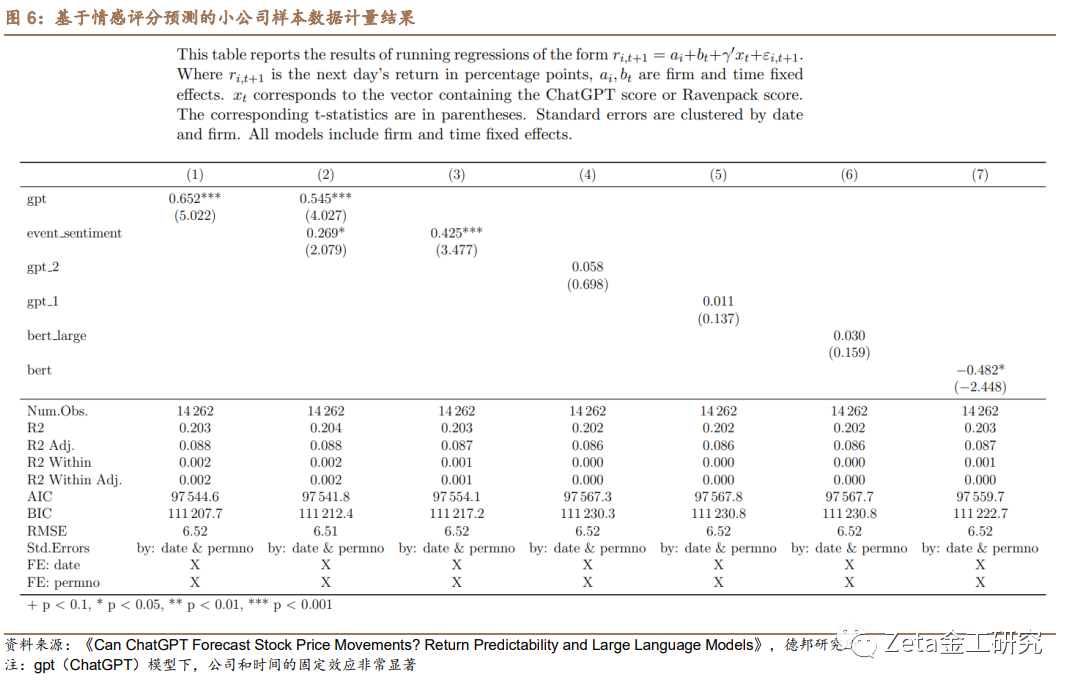
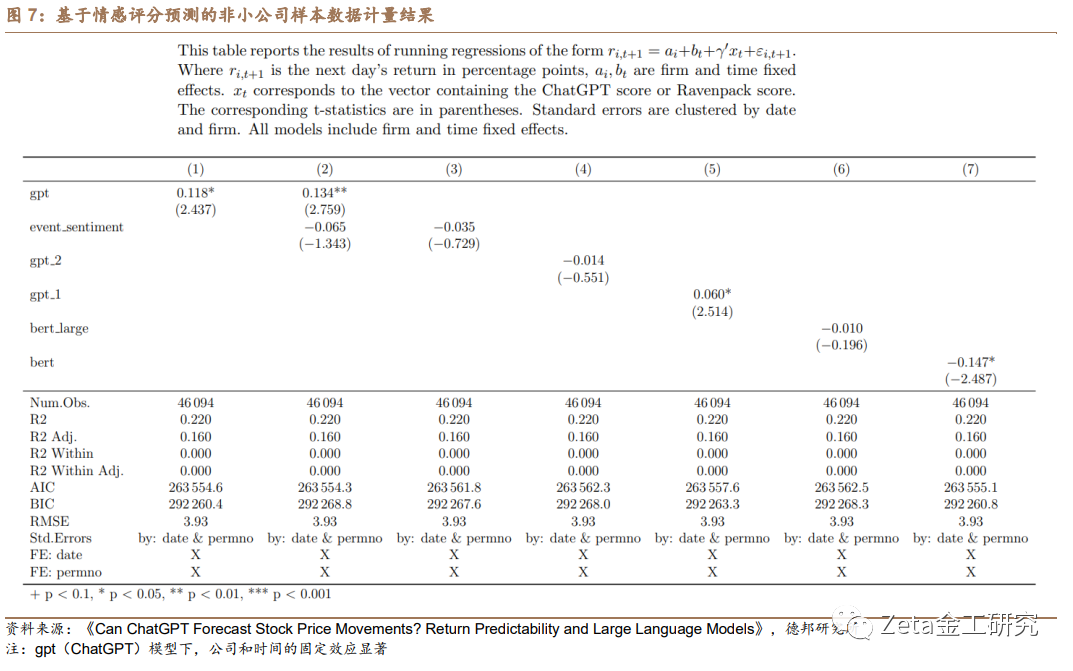
图8报告了各种模型拟合度量,如R平方、调整R平方、AIC和BIC,以评估模型的整体解释力。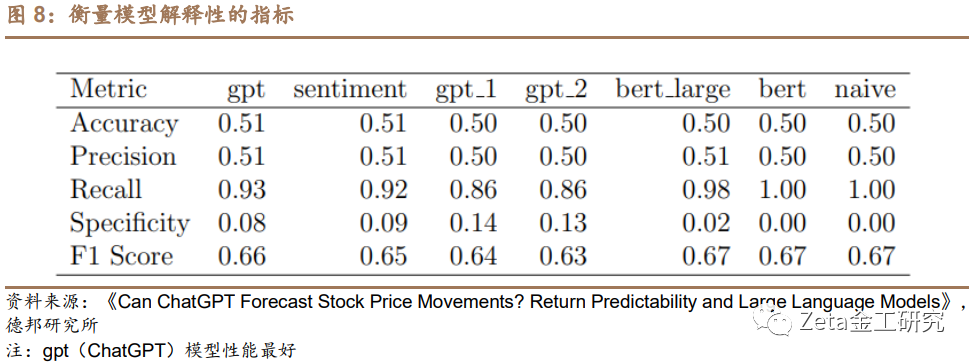
该论文探讨了ChatGPT在预测股票市场收益方面的潜力,方法是通过对新闻标题进行情感分析。该论文的发现表明,ChatGPT在预测股票市场收益方面优于RavenPack等领先供应商的传统情感分析方法。该论文通过展示大型语言模型在金融经济学中的价值,为人工智能和自然语言处理在这一领域的应用研究作出贡献。该论文对未来的研究具有几个影响。首先,该论文强调了继续探索和开发专门为金融行业量身定制的大型语言模型的重要性。随着AI驱动的金融发展,可以设计更复杂的模型来提高金融决策过程的准确性和效率。其次,该论文的发现表明,未来的研究应该关注大型语言模型从哪些机制中获取其预测能力。通过确定导致ChatGPT等模型在预测股票市场回报方面获得成功的因素,研究人员可以为改进这些模型、最大化其在金融领域的效用制定更有针对性的策略。此外,随着大型语言模型在金融行业变得越来越普及,探讨它们对市场动态的潜在影响至关重要,包括价格形成、信息传播和市场稳定性。未来的研究可以探讨大型语言模型在塑造市场行为方面的作用,以及它们对金融系统可能产生的积极和消极后果。最后,未来的研究可以探讨将大型语言模型与其他机器学习技术和量化模型相结合,创建将不同方法优势结合在一起的混合系统。通过利用各种方法的互补能力,研究人员可以进一步提高金融经济学中AI驱动模型的预测能力。简而言之,该论文的研究展示了ChatGPT在预测股票市场收益方面的价值,并意在为大型语言模型在金融行业的应用和影响的未来研究铺平道路。随着AI驱动的金融领域不断扩展,本研究可以帮助更准确、高效和负责任的模型的开发,从而提高金融决策过程的绩效。通过挖掘大型语言模型的潜力,该论文可以在金融领域更好地应用人工智能和自然语言处理技术。因此,在金融产业中不断创新和发展大型语言模型至关重要,以确保为市场参与者提供更强大和高效的工具,以应对金融市场的挑战和不断变化的需求。数据不完备和滥用风险,信息安全风险,模型失效风险。[1]. Acemoglu, D., Autor, D., Hazell, J., & Restrepo, P. (2022). Artificial Intelligence and Jobs: Evidence from Online Vacancies. Journal of Labor Economics, 40(S1), S293-S340.[2]. Acemoglu, D., & Restrepo, P. (2022). Tasks, Automation, and the Rise in U.S. Wage Inequality. Econometrica, 90(5), 1973-2016.[3]. Agrawal, A., Gans, J. S., & Goldfarb, A. (2019). Artificial Intelligence: The Ambiguous Labor Market Impact of Automating Prediction. Journal of Economic Perspectives, 33(2), 31-50.[4]. Babina, T., Fedyk, A., He, A. X., & Hodson, J. (2022). Artificial Intelligence, Firm Growth, and Product Innovation. SSRN Electronic Journal.[5]. Baker, S. R., Bloom, N., & Davis, S. J. (2016). Measuring economic policy uncertainty. Quarterly Journal of Economics, 131(4), 1593-1636.[6]. Binsbergen, J. H. V., Han, X., & Lopez-Lira, A. (2020). Man vs. Machine Learning: The Term Structure of Earnings Expectations and Conditional Biases. National Bureau of Economic Research.[7]. Bybee, L., Kelly, B. T., Manela, A., & Xiu, D. (2019). The Structure of Economic News. Working Paper.[8]. Bybee, L., Kelly, B. T., Manela, A., & Xiu, D. (2021). Business News and Business Cycles. SSRN Electronic Journal.[9]. Calomiris, C. W., & Mamaysky, H. (2019). How news and its context drive risk and returns around the world. Journal of Financial Economics, 133(2), 299-336.[10]. Campbell, J. L., Chen, H., Dhaliwal, D. S., Lu, H. M., Steele, L. B., & Campbell, J. L. (2014). The information content of mandatory risk factor disclosures in corporate filings. Review of accounting studies (Boston), 19(1), 396-455.[11]. Cohen, L., Malloy, C., & Nguyen, Q. (2020). Lazy Prices. Journal of Finance, 75(3), 1371-1415.[12]. Cowen, T., & Tabarrok, A. T. (2023). How to Learn and Teach Economics with Large Language Models, Including GPT. SSRN Electronic Journal.[13]. Freyberger, J., Neuhierl, A., & Weber, M. (2020). Dissecting Characteristics Nonparametrically. Review of Financial Studies, 33(5), 2326-2377.[14]. Garcia, D. (2013). Sentiment during Recessions. The Journal of Finance, 68(3), 1267-1300.[15]. Gaulin, M. P. (2017). Risk Fact or Fiction: The Information Content of Risk Factor Disclosures.[16]. Gu, S., Kelly, B., & Xiu, D. (2020). Empirical Asset Pricing via Machine Learning. Review of Financial Studies, 33(5), 2223-2273.[17]. Hansen, A. L., & Kazinnik, S. (2023). Can ChatGPT Decipher Fedspeak? SSRN Electronic Journal.[18]. Hansen, Stephen, Michael McMahon, and Andrea Prat. 2018. “Transparency and Deliberation Within the FOMC: A Computational Linguistics Approach*.” The Quarterly Journal of Economics 133, no. 2 (May): 801–870.[19]. Hoberg, Gerard, and Gordon Phillips. 2016. “Text-Based Network Industries and Endogenous Product Differentiation.” Journal of Political Economy 124 (5): 1423–1465.[20]. Jegadeesh, Narasimhan, and Di Wu. 2013. “Word power: A new approach for content analysis.” Journal of Financial Economics 110 (3): 712–729.[21]. Jiang, Hao, Sophia Zhengzi Li, and Hao Wang. 2021. “Pervasive underreaction: Evidence from high-frequency data.” Journal of Financial Economics 141, no. 2 (August): 573–599.[22]. Ke, Shikun, Jos´e Luis Montiel Olea, and James Nesbit. 2019. “A Robust Machine Learning Algorithm for Text Analysis.” Working Paper.[23]. Ke, Zheng, Bryan T Kelly, and Dacheng Xiu. 2019. “Predicting Returns with Text Data.” University of Chicago, Becker Friedman Institute for Economics Working Paper.[24]. Korinek, Anton. 2023. “Language Models and Cognitive Automation for Economic Research.” (Cambridge, MA) (February).[25]. Lopez-Lira, Alejandro. 2019. “Risk Factors That Matter: Textual Analysis of Risk Disclosures for the Cross-Section of Returns.” SSRN Electronic Journal (September).[26]. Manela, Asaf, and Alan Moreira. 2017. “News implied volatility and disaster concerns.” Journal of Financial Economics 123, no. 1 (January): 137–162.[27]. Noy, Shakked, and Whitney Zhang. 2023. “Experimental Evidence on the Productivity Effects of Generative Artificial Intelligence.” SSRN Electronic Journal (March).[28]. Tetlock, Paul C. 2007. “Giving Content to Investor Sentiment: The Role of Media in the Stock Market.” The Journal of Finance 62, no. 3 (June): 1139–1168.[29]. Tetlock, Paul C., Maytal Saar-Tsechansky, and Sofus Macskassy. 2008. “More Than Words: Quantifying Language to Measure Firms’ Fundamentals.” Journal of Finance 63, no. 3 (June): 1437–1467.[30]. Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. “Attention is all you need.” Advances in Neural Information Processing Systems 2017-Decem:5999–6009.[31]. Webb, Michael. 2019. “The Impact of Artificial Intelligence on the Labor Market.” SSRN Electronic Journal (November).[32]. Wu, Shijie, Ozan ˙ Irsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prabhanjan Kambadur, David Rosenberg, and Gideon Mann. 2023. “BloombergGPT: A Large Language Model for Finance” (March).[33]. Yang, Kai-Cheng, and Filippo Menczer. 2023. “Large language models can rate news outlet credibility” (April).证券研究报告:《只有艰难时期的赢家能重复成功:对冲基金在不同市场条件下的业绩持续性——德邦金工文献精译第九期》
对外发布时间:2023年04月22日
分析师:肖承志
资格编号:S0120521080003
邮箱:xiaocz@tebon.com.cn
报告发布机构:德邦证券股份有限公司
(已获中国证监会许可的证券投资咨询业务资格)
肖承志,同济大学应用数学本科、硕士,现任德邦证券研究所首席金融工程分析师。具有6年证券研究经历,曾就职于东北证券研究所担任首席金融工程分析师。致力于市场择时、资产配置、量化与基本面选股。撰写独家深度“扩散指标择时”系列报告;擅长各类择时与机器学习模型,对隐马尔可夫模型有深入研究;在因子选股领域撰写多篇因子改进报告,市场独家见解。
林宸星,美国威斯康星大学计量经济学硕士,上海财经大学本科,主要负责大类资产配置、中低频策略开发、FOF策略开发、基金研究、基金经理调研和数据爬虫等工作,2021年9月加入德邦证券。
吴金超,清华大学硕士,南开大学本科,主要负责指数择时、行业轮动、基本面量化选股等工作,曾任职于华为技术有限公司、东北证券、广发证券,2021年11月加入德邦证券。
路景仪,上海财经大学金融专业硕士,吉林大学本科,主要负责基金研究、基金经理调研等工作,2022年6月加入德邦证券。
王治舜,香港中文大学金融科技硕士,电子科技大学金融+计算机双学士,主要负责量化金融、因子选股等工作,2023年1月加入德邦证券。
感谢卢浩瑄同学对本文的贡献。
适当性说明:《证券期货投资者适当性管理办法》于2017年7月1日起正式实施,通过本微信订阅号/本账号发布的观点和信息仅供德邦证券的专业投资者参考,完整的投资观点应以德邦证券研究所发布的完整报告为准。若您并非德邦证券客户中的专业投资者,为控制投资风险,请取消订阅、接收或使用本订阅号/本账号中的任何信息。本订阅号/本账号难以设置访问权限,若给您造成不便,敬请谅解。市场有风险,投资需谨慎。
分析师承诺:本人具有中国证券业协会授予的证券投资咨询执业资格,以勤勉的职业态度、专业审慎的研究方法,使用合法合规的信息,独立、客观地出具本报告,本报告所采用的数据和信息均来自市场公开信息,本人对这些信息的准确性或完整性不做任何保证,也不保证所包含的信息和建议不会发生任何变更。报告中的信息和意见仅供参考。本人过去不曾与、现在不与、未来也将不会因本报告中的具体推荐意见或观点而直接或间接收任何形式的补偿,分析结论不受任何第三方的授意或影响,特此证明。
免责声明
德邦证券股份有限公司经中国证券监督管理委员会批准,已具备证券投资咨询业务资格。本报告中的信息均来源于合规渠道,德邦证券研究所力求准确、可靠,但对这些信息的准确性及完整性均不做任何保证,据此投资,责任自负。本报告不构成个人投资建议,也没有考虑到个别客户特殊的投资目标、财务状况或需要。客户应考虑本报告中的任何意见或建议是否符合其特定状况。德邦证券及其所属关联机构可能会持有报告中提到的公司所发行的证券并进行交易,还可能为这些公司提供投资银行服务或其他服务。
本报告仅向特定客户传送,未经德邦证券研究所书面授权,本研究报告的任何部分均不得以任何方式制作任何形式的拷贝、复印件或复制品,或再次分发给任何其他人,或以任何侵犯本公司版权的其他方式使用。如欲引用或转载本文内容,务必联络德邦证券研究所并获得许可,并需注明出处为德邦证券研究所,且不得对本文进行有悖原意的引用和删改。如未经本公司授权,私自转载或者转发本报告,所引起的一切后果及法律责任由私自转载或转发者承担。本公司并保留追究其法律责任的权利。
本订阅号不是德邦证券研究报告的发布平台,所载内容均来自于德邦证券已正式发布的研究报告,或对研究报告进行的整理与解读,因此在任何情况下,本订阅号中的信息或所表述的意见并不构成对任何人的投资建议。
本篇文章来源于微信公众号: Zeta金工研究
本文链接:https://kxbaidu.com/post/%E3%80%90%E5%BE%B7%E9%82%A6%E9%87%91%E5%B7%A5%7C%E6%96%87%E7%8C%AE%E7%B2%BE%E8%AF%91%E3%80%91ChatGPT%E8%83%BD%E5%A4%9F%E9%A2%84%E6%B5%8B%E8%82%A1%E7%A5%A8%E4%BB%B7%E6%A0%BC%E7%9A%84%E8%B5%B0%E5%8A%BF%E5%90%97%EF%BC%9F%E6%94%B6%E7%9B%8A%E5%8F%AF%E9%A2%84%E6%B5%8B%E6%80%A7%E5%92%8C%E5%A4%A7%E5%9E%8B%E8%AF%AD%E8%A8%80%E6%A8%A1%E5%9E%8B%E2%80%94%E2%80%94%E5%BE%B7%E9%82%A6%E9%87%91%E5%B7%A5%E6%96%87%E7%8C%AE%E7%B2%BE%E8%AF%91%E7%AC%AC%E5%8D%81%E6%9C%9F.html 转载需授权!