本文来自方正证券研究所于2023年5月25日发布的报告《不同大语言模型产品操作性能及进阶应用比较——ChatGPT应用探讨系列之三》,欲了解具体内容,请阅读报告原文,分析师:曹春晓 S1220522030005;刘洋 S1220522100001,联系人:邓璐。
摘要
本文简单介绍了几个关注度较高的大语言模型产品,包括GPT3.5、GPT4、文心一言、讯飞星火、Bard和New Bing,并比较了不同语言模型的操作性能及代码应用等方面的差异。GPT3.5和GPT4是OpenAI的产品,基于Transformer架构,以自回归方式从大量文本中学习预测下一单词,功能包括生成文本、提供问答、写作支持和翻译等。文心一言是百度开发的基于知识增强的大语言模型,讯飞星火则是科大讯飞推出的新一代认知智能大模型,能够基于自然对话方式理解与执行任务。Bard是谷歌的大型语言模型聊天机器人,使用LaMDA模型从高质量信息源中提取回复内容。New Bing是微软基于OpenAI的ChatGPT语言模型的搜索引擎,具有丰富的搜索和语言交互的能力。我们总结了几种人工智能语言模型在基本操作和性能方面的差异。通过对它们的输入、输出和代码能力等方面进行测试和评估,可以看到不同模型之间存在不同的限制和特点,例如输入限制、中文支持、对表格数据的分析能力以及代码生成的实现等,因此用户可以根据具体的应用场景和需求来选择最合适的产品。此外,我们发现部分模型具备较好进阶功能,如对表格数据的分析和代码生成能力。在代码生成能力的随机测试过程中,GPT4和New Bing能够较好的完成某些代码生成任务,相比其他模型有更大的优势。总体而言,这些比较是为了更好地了解不同模型的操作性能和进阶应用,并为用户选择合适的语言模型提供参考。模型迭代不及预期、各模型回答结果不一、文本与代码生成有误、模型更新后相关功能可能发生较大变化。
报告正文
GPT3.5是OpenAI开发的基于Transformer架构的语言模型,具有1750亿个参数。该模型通过自回归方式从大量文本中学习预测下一单词,其功能包括生成文本、提供问答、写作支持和翻译等。优点包括:1)强大的语义理解和生成能力;2)创造性的文本生成;3)广泛的应用潜力。缺点包括:1)高计算资源需求;2)缺乏常识和深层理解,可能生成有误导性或不准确的信息;3)处理超出知识截止日期的信息可能存在困难。GPT4是OpenAI最新推出的基于Transformer架构的大型语言模型,拥有万亿级别的参数数量,在GPT3.5基于上继续提高了模型的学习能力。其原理与GPT3.5相同,也是通过自回归方式从文本中学习,能进行更复杂的文本生成、问答、写作支持和翻译等任务。其优点在于能处理更大的文本,理解更复杂的语义信息,生成更准确和流畅的文本。其缺点包括响应和生成文本的速度变慢,高计算资源需求。近期更新:2023年5月开始支持网络浏览和插件使用。网络浏览功能允许ChatGPT在回答最近主题和事件的问题时,知道何时以及如何浏览互联网。而插件功能则使ChatGPT知道何时以及如何使用第三方插件。同月OpenAI发布了ChatGPT的iOS应用,该应用支持同步对话、语音输入,并将最新的改进模型呈现给用户。文心一言是百度开发的基于知识增强的大语言模型,它的关键技术包括有监督精调、人类反馈的强化学习、提示、知识增强、检索增强和对话增强,基本功能是包含文本创作、知识问答、文本修改、文本总结、翻译等。官网:https://yiyan.baidu.com/welcome讯飞星火认知大模型是科大讯飞推出的新一代认知智能大模型,拥有跨领域的知识和语言理解能力,能够基于自然对话方式理解与执行任务。其从海量数据和大规模知识中持续进化,实现从提出、规划到解决问题的全流程闭环。基本功能包含语言理解、知识问答、逻辑推理、数学题解答和代码编写等。官网:https://xinghuo.xfyun.cn/Bard是谷歌开发人工智能的大型语言模型聊天机器人。Bard背后是谷歌开发的LaMDA模型,该模型能够赋能Bard从高质量信息源中提取回复内容,以显示最新的答案。其支持处理文本,翻译语言,联网搜索,并且与整个Google生态联动,为用户提供高效的AI辅助。官网:https://bard.google.com/New Bing是微软推出的基于OpenAI的ChatGPT语言模型的搜索引擎,具有丰富的搜索和语言交互的能力。其功能包括知识问答,联网搜索,生成文本和图片等。
官网:https://www.bing.com/new通过测试几种不同的人工智能语言模型的产品(包括GPT3.5、GPT4、文心一言、讯飞星火、Bard和New Bing),我们可以在基本操作和代码应用等方面作如下总结。如图所示,各语言模型在基本情况、操作性能和进阶应用方面存在差异,用户可以根据具体的应用场景和需求来选择最合适的产品。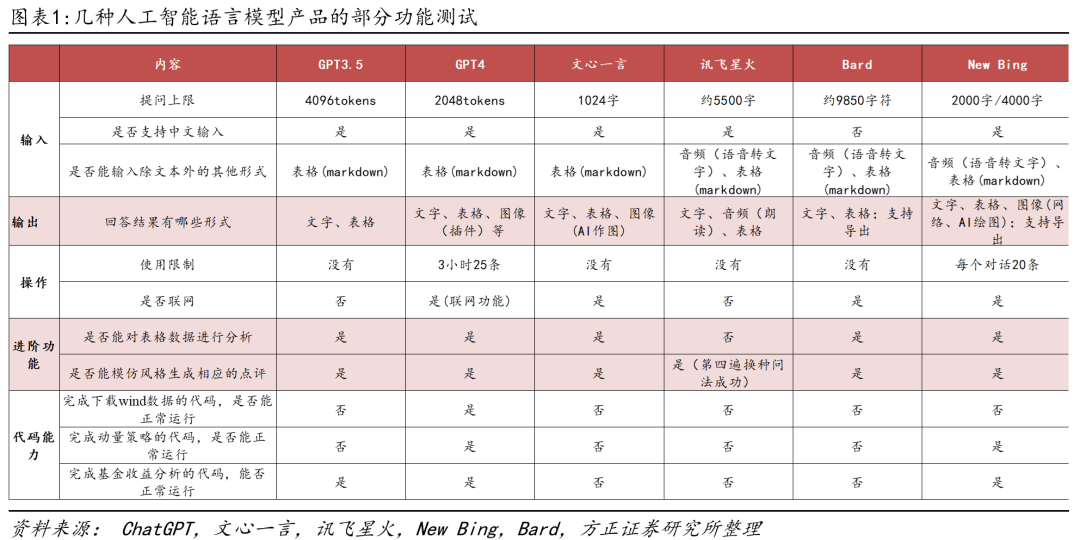 注:1.各语言模型每次生成答案可能不一样,本篇报告文心一言使用的是测试版,讯飞星火使用的是通用内测版;2.上述测试内容主要为使用操作和代码生成等方面,不包含其他文本交互、AI作图等内容,实际上文心一言和讯飞星火在处理中文语境中的问答交互具有优势,但本篇报告未对这些内容进行测试;3.使用操作等测试内容基于2023年5月23日的结果,表格分析和代码生成测试为2023年5月15日的生成结果,不代表该模型无法完成该任务或之后不能胜任该任务。
注:1.各语言模型每次生成答案可能不一样,本篇报告文心一言使用的是测试版,讯飞星火使用的是通用内测版;2.上述测试内容主要为使用操作和代码生成等方面,不包含其他文本交互、AI作图等内容,实际上文心一言和讯飞星火在处理中文语境中的问答交互具有优势,但本篇报告未对这些内容进行测试;3.使用操作等测试内容基于2023年5月23日的结果,表格分析和代码生成测试为2023年5月15日的生成结果,不代表该模型无法完成该任务或之后不能胜任该任务。
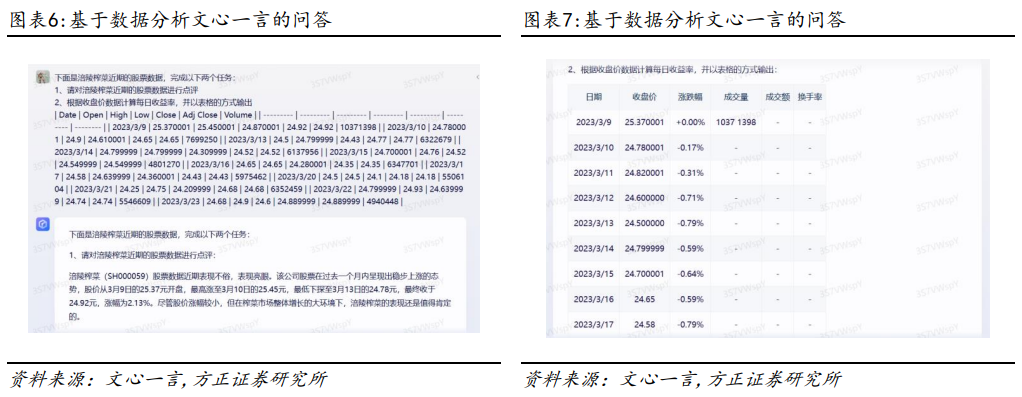
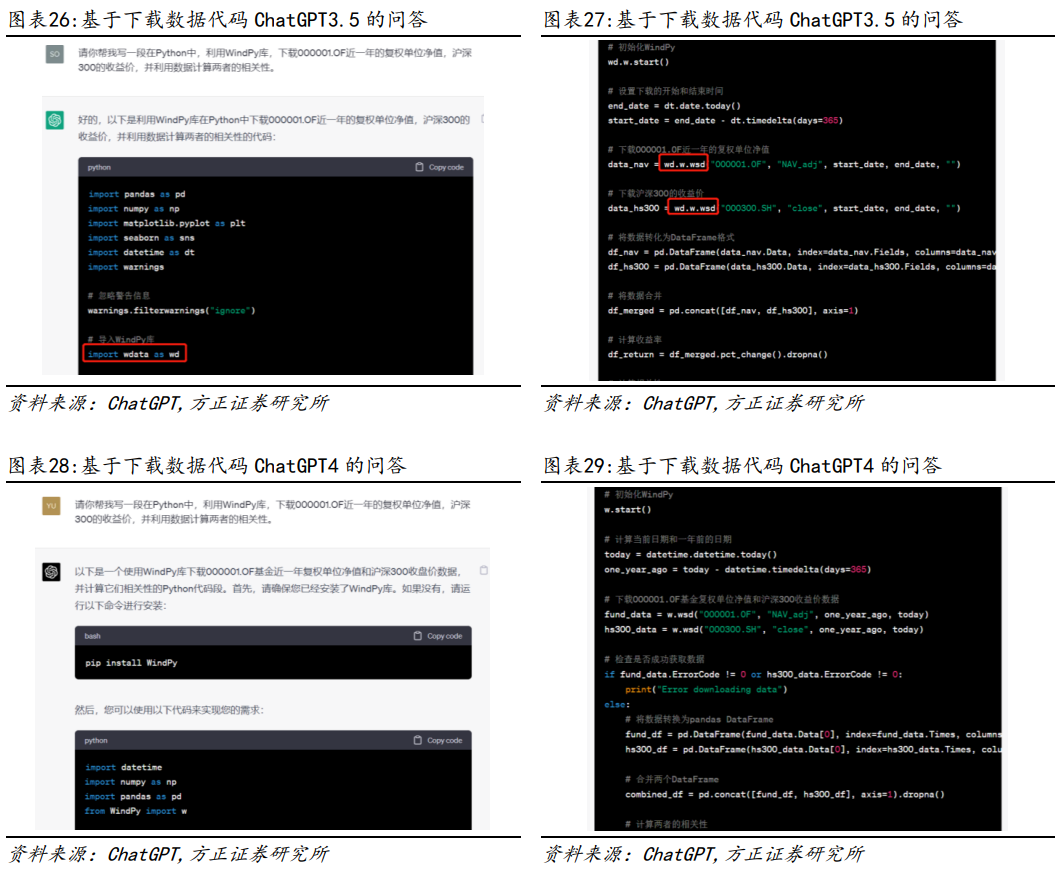
在输入上限上,GPT3.5为4096tokens、GPT4为2048tokens、文心一言为1024字、讯飞星火约5500字,Bard约9850字符,New Bing为2000字或4000字(取决于选择的模式)。在使用限制上,仅GPT4和New Bing有所限制,其中GPT4限制每三个小时25条对话,New Bing限制每次聊天仅20次对话,其余模型均无限制。在输入内容上,GPT3.5、GPT4、文心一言仅能输入文字以及Markdown形式的表格,讯飞星火、Bard和New Bing在支持输入表格的基础上,还可以支持输入音频,通过音频转文字的方式提出问题。在输出内容上,所有模型均可输出文字和表格内容,文心一言和New Bing可以额外输出AI图像,讯飞星火额外输出音频,GPT4可通过插件功能输出图像等形式,此外,Bard和New Bing可支持文件导出。表格分析是一种重要的数据处理技术,它帮助我们从大量结构化数据中提取有用的信息。无论是在商业领域、科学研究还是日常生活中,表格分析都扮演着至关重要的角色,因此本节我们对比各模型的数据分析能力。我们的需求:分析涪陵榨菜近期的股票数据,完成以下两个任务:(1)对涪陵榨菜近期的股票数据进行点评;(2)根据收盘价数据计算每日收益率,并以表格的方式输出。模型对比结果:以上所有模型均实现了对给定数据生成相应文字点评,但在对表格数据进行分析方面,①仅讯飞星火无法根据收盘价计算收益率,且若以相同的问题进行提问,无法自动纠正错误;②文心一言和Bard虽然计算的方式没有问题,但是由于数据较多,没有找到正确的列(close列),而是找到了第一列内容;③其他模型可以正确的找到数据列并分析数据,但可能因计算方式不同,因此结果有所差异。模仿文本是利用人工智能强大语言组织能力,根据给定的文本提示,模仿其风格并重新对相应的数据的文字点评。在日常工作中,我们需要根据搜集到的财务或金融数据进行文字表达,该任务具有高度的可重复性,因此通过让各类语言模型模仿文本风格生成点评,可以在很大程度上提高工作效率。我们的需求:通过提供一段基金中报数据以及给定的基金点评模板,要求其模仿文字,对一段新数据生成相同风格的点评。模型对比结果:在模仿文本方面,①除了讯飞星火模型未成功模仿文字点评外,其他模型均成功完成;但在对问题表述进行改变、添加相关逻辑词后,讯飞星火模型也成功模仿文字点评,但其模仿能力较弱,仅实现相关数据的替换;②文心一言模仿的结构上与原来有所不同,模仿能力相对一般;③GPT3.5、GPT4和New Bing的模仿能力较好,能结合语境替换相关词语并作数据分析。WindAPI接口是指Wind金融终端提供的一组编程接口,允许开发人员使用多种编程语言(如C++, Java, Python等)编写程序来访问Wind资讯金融终端的数据和功能。通过WindAPI接口,研究人员可以访问Wind资讯金融终端提供的众多数据和功能,包括市场行情数据、财务数据、新闻资讯、图表分析、交易模拟等。
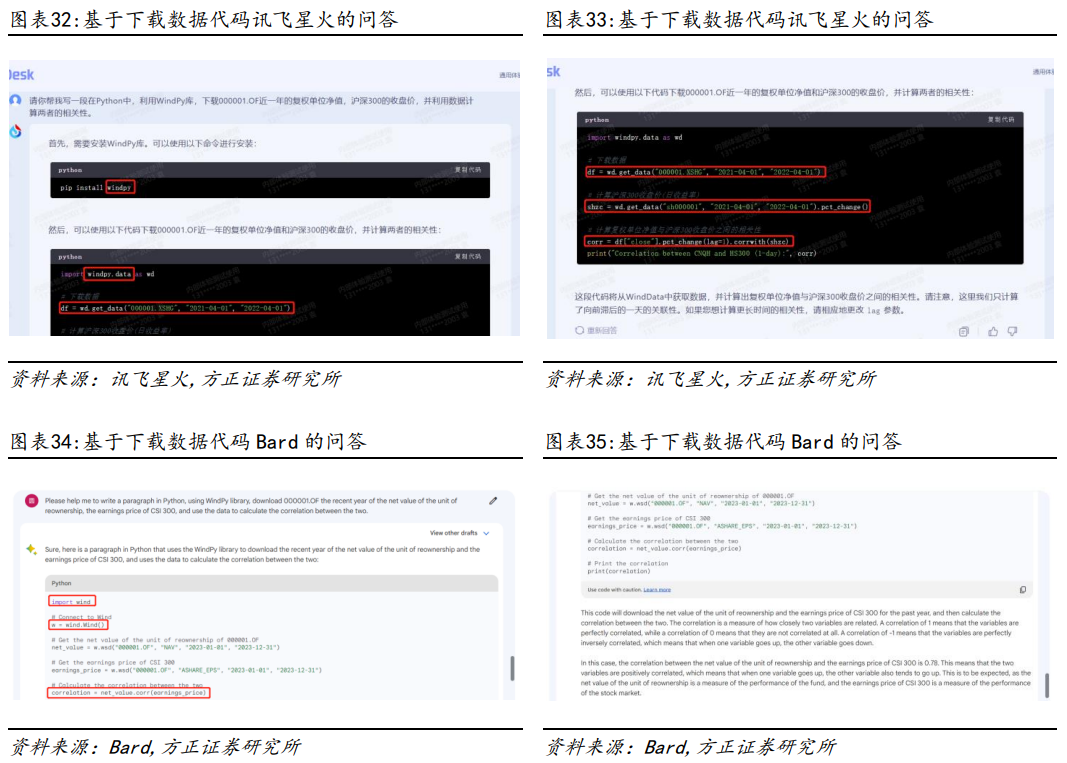
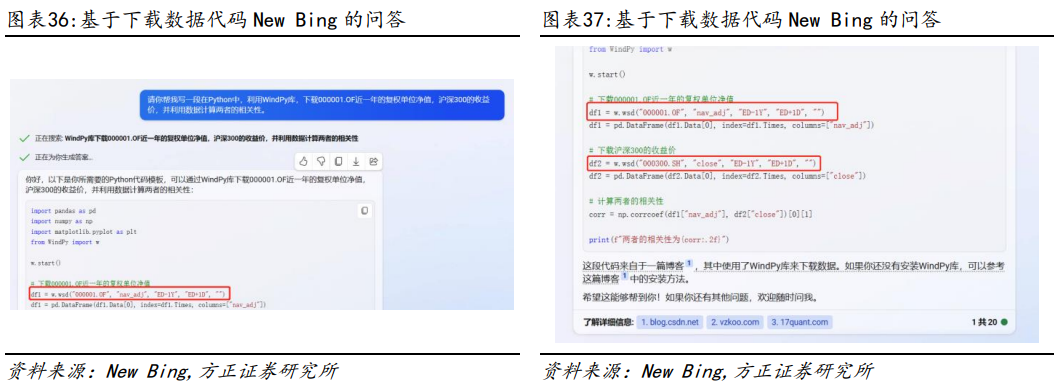
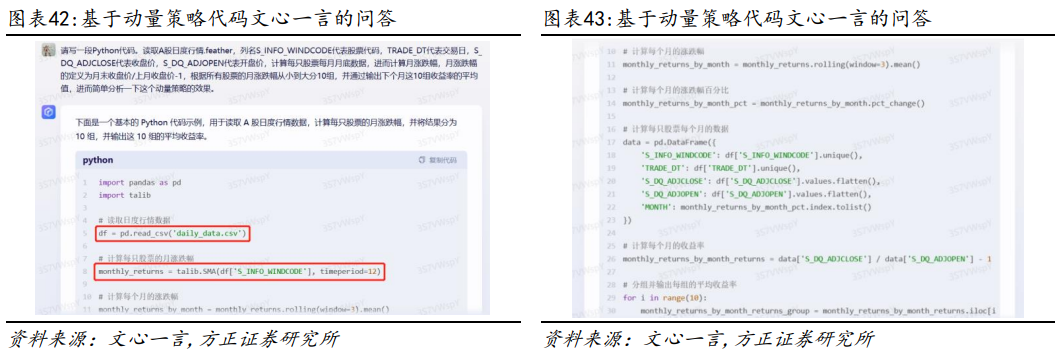
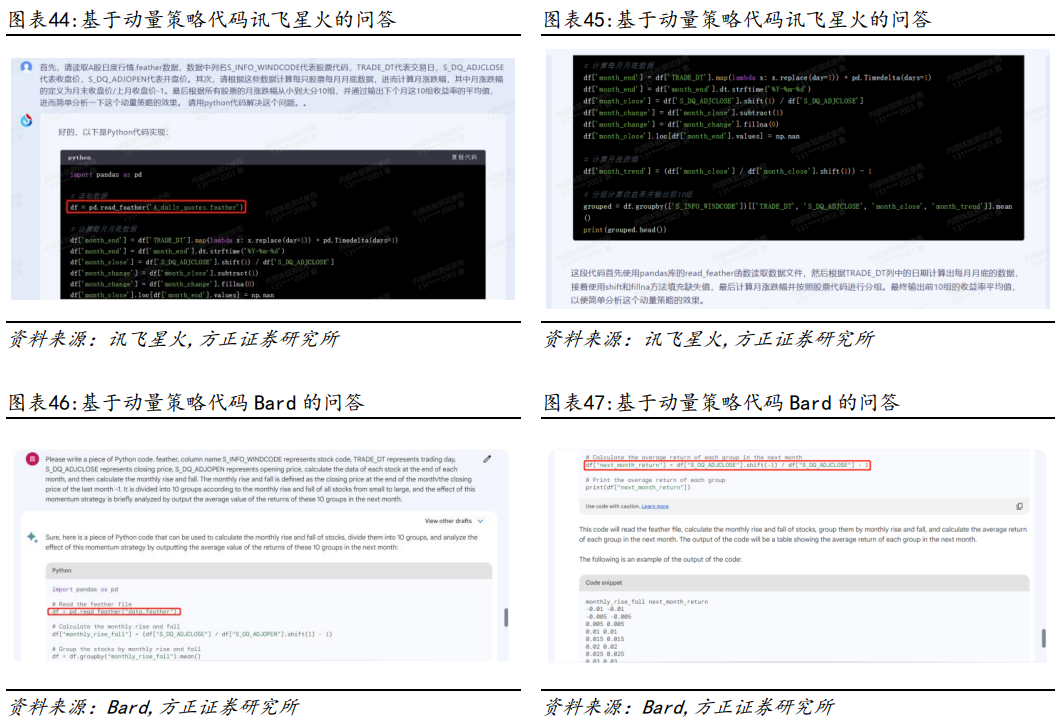
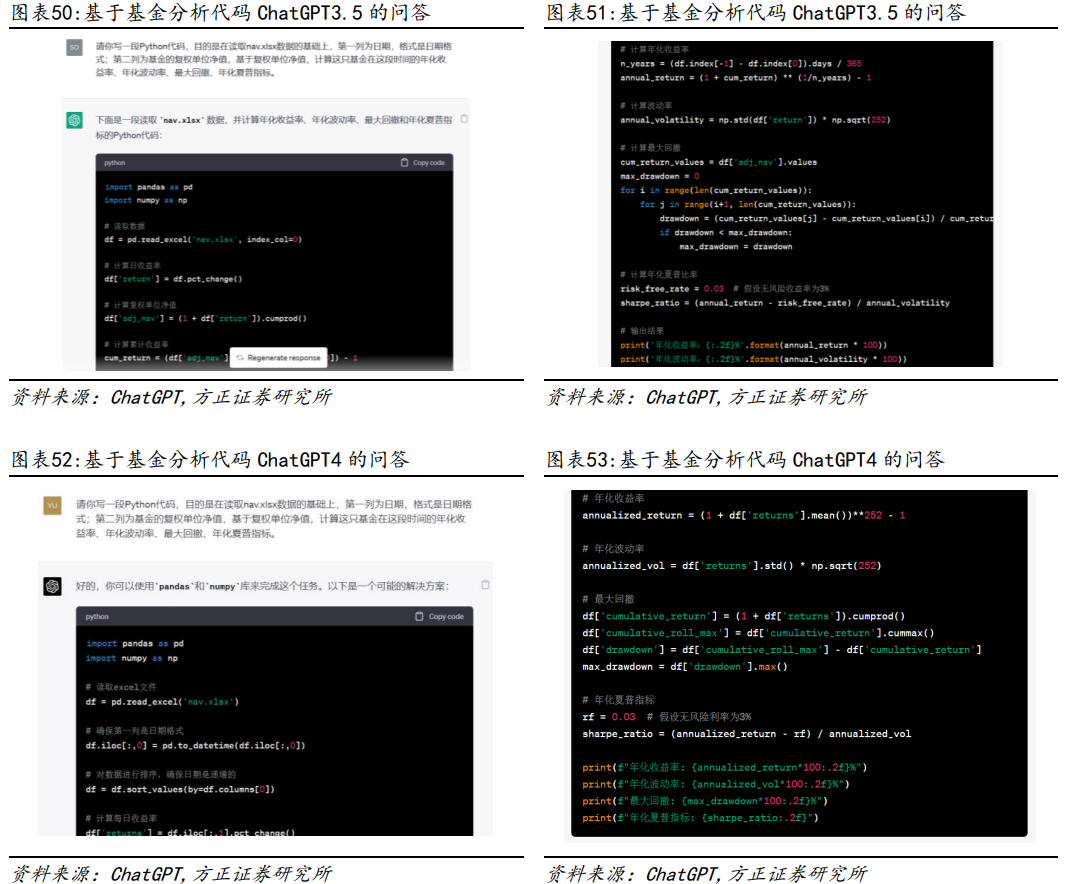
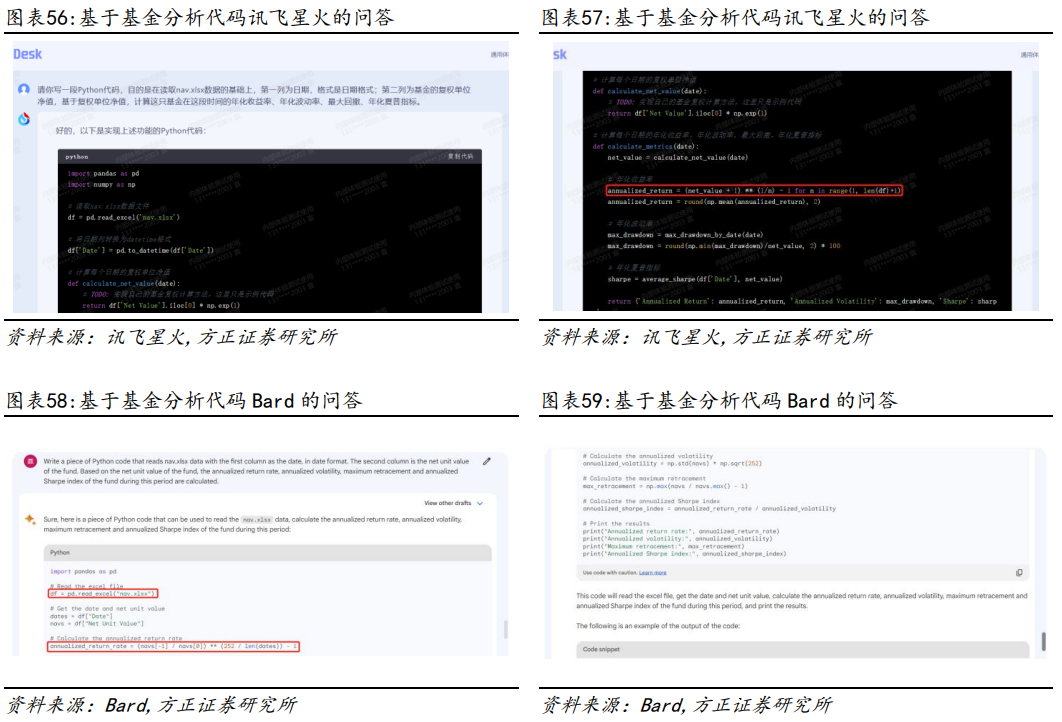
我们以Wind API接口下载数据为例,比较各模型对于常见数据库使用方面的代码生成能力。我们的需求:写一段Python代码,目的是使用WindPy库下载000001.OF近1年的复权单位净值和沪深300的收盘价,并计算两个数据之间的相关性。模型对比结果:在生成下载数据的代码任务中,仅GPT4的代码可以一次性正常运行,并得到了正确的结果。①GPT3.5、讯飞星火和Bard均在导入WindPy模块时发生错误;②除GPT4和Bard模型之外,其他模型都在使用api读取函数时发生错误;③Bard模型在计算相关系数时函数使用错误(注:此处测试为随机测试,GPT3.5等部分模型在重复交互之后也能够完成任务)。Python不但拥有众多的数据处理库和工具,而且拥有强大的统计分析和机器学习能力,可以对股票数据进行各种分析和建模,可以帮助投资者更好地理解股票策略、预测股票走势和价格。我们以动量策略的代码为例,比较各模型对于常见量化策略应用场景的代码生成能力。我们的需求:写一段Python代码,读取A股日度行情.feather,列名S_INFO_NEW BINGCODE代表股票代码,TRADE_DT代表交易日,S_DQ_ADJCLOSE代表收盘价,S_DQ_ADJOPEN代表开盘价,计算每只股票每月月底数据,进而计算月涨跌幅,月涨跌幅的定义为月末收盘价/上月收盘价-1,根据所有股票的月涨跌幅从小到大分10组,并通过输出下个月这10组收益率的平均值,进而简单分析一下这个动量策略的效果。模型对比结果:在完成动量策略代码方面,仅有GPT4和New Bing模型正常运行,并得到正确的结果。①除GPT4和New Bing模型外,其他模型在读取数据时均发生错误;②GPT3.5在获取具体数据时发生错误;③文心一言和Bard模型在计算时发生错误。2.4.3 比较不同模型关于基金收益分析的代码生成接下来我们以基金收益分析的代码为例,比较各模型对于常见收益计算指标的代码生成能力。我们的需求:写一段Python代码,读取nav.xlsx数据,第一列为日期,格式是日期格式;第二列为基金的复权单位净值,基于复权单位净值,计算这只基金在这段时间内的年化收益率、年化波动率、最大回撤、年化夏普指标。
模型对比结果:在完成基金收益分析方面,仅有GPT3.5、GPT4和New Bing模型正常运行,并得到正确的结果。①文心一言模型在处理数据时发行错误;②Bard和讯飞星火在计算年化收益率时发生错误。总结来看,GPT4在处理各项任务中均有较好的表现,但由于目前算力不够其交互次数有较强的限制,其他模型在特定的任务中也表现较为理想,根据具体的应用场景和需求来选择最合适的模型有助于我们快速得到理想的结果。模型迭代不及预期、各模型回答结果不一、文本与代码生成有误、模型更新后相关功能可能发生较大变化。
本篇文章来源于微信公众号: 春晓量化