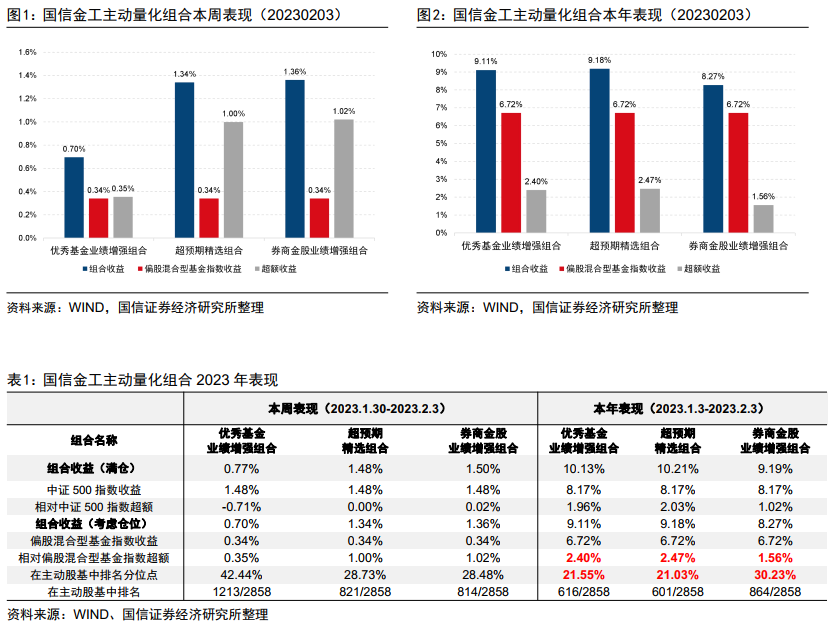
机器学习与因子(一):特征工程算法测评
陈奥林 从业证书编号 S1230523040002
核
心
观
点
本文使用一系列机器学习模型对相同的输入因子进行特征工程,对比不同模型选股组合的投资表现,并定量分析因子对个股定价的影响,得出如下结论:
首先,机器学习能够提高投资组合的绩效,集成学习树模型效果最佳。其次,机器学习模型体现出了对A股市场的一定动态适应能力。最后,交易类因子是决定个股短期定价最重要的因素之一。成交稳定,价格低波动的股票短期内表现出较高回报。
机器学习模型能提升组合绩效,树模型表现最佳
以万得全A指数为基准,各机器学习模型在样本外都可获得超额回报。分别在固定时间窗口训练模式和滚动时间窗口训练模式下,对比3类共10种机器学习模型在预测股票短期收益率方面的效果。结果显示,梯度提升树模型LightGBM和XGBoost在两种训练模式下表现最好。
机器学习模型有动态适应能力
测评各模型在滚动时间窗口模式下,预测股票短期回报的表现。结果显示,绝大多数模型在滚动窗口模式下,股票回报预测的准确性良好。这表明机器学习模型具有一定的动态环境适应能力。
交易类因子是影响个股短期定价最关键的因素
本文检验了主流多因子和经研究检验的补充因子的重要性。结果显示,各模型在不同年份,都认为交易类因子的重要性最高,交易类因子是影响股票短期定价的关键因素。相比而言,基本面因子对股票短期回报的解释力和预测力较弱。
流动性稳定、低波动性的股票短期收益占优
短期内回报较高的股票通常具备以下几个交易特征:成交额波动较小,价格对交易正弹性,短期内未发生过大幅度筹码交换且近期未发生过价格的剧烈波动。
风险提示
模型测算风险:超参数设定对模型结果有较大影响;收益指标等指标均限于一定测试时间和测试样本得到,收益指标不代表未来。
模型失效风险:机器学习模型基于历史数据进行测算,不能直接代表未来,仅供参考。
壹
引言
随着大数据与算力的发展,机器学习技术正在深刻改变着金融投资的理论与实践。作为股票量化投资的基石之一,因子投资也有与机器学习相结合的空间。
目前,因子投资主要面临以下几方面的瓶颈。首先,因子面临失效风险。Fama和French(2007)在研究中发现,市场中许多知名的因子在发现后的3-5年内会出现有效性衰减。以价值因子为例,发现后的前3年可以获得约7%的年化超额收益,但此后超额收益逐年下降,至第5年时降至2%。其次,数据挖掘产生大量伪因子。Lewellen(2015)认为很多因子源自于数据挖掘,容易导致样本内回测表现优异但在实际应用中表现不佳,使得因子有效性验证的难度增加。最后,因子稳定性和泛化能力存在争议。Fama和French(2016)发现市场中可以获取超额收益的因子几乎都存在周期性的现象,这会对投资者的信心与资产配置行为产生影响。
近年来,学界和业界均积极探索机器学习在全球各个股票市场因子选股与组合优化中的实证应用,并取得很大成效。Gu et al. (2017)采用深度学习方法构建股票分类模型,并通过回测证明其在行业中性策略上的表现优于基准。Krauss et al. (2017)发现通过LSTM网络预测的未来收益率,可以用于构建获得超额收益的股票轮动策略。Huang et al. (2018)提出基于增强学习的波动性策略,通过连续学习与优化,获得稳定的超额收益。Gu et al.(2020) 在美股市场对测量资产风险溢价的机器学习方法进行了比较分析,证明了使用机器学习预测会获得较大的资产回报,并追溯它们的预测收益来源于允许非线性的预测变量交互作用。Leippold et al.(2021) 在A股市场使用各种机器学习算法分析了一组全面的因子回报预测,文章发现,相比美股市场,流动性在A股的重要程度最高。
中国A股市场规模正快速增长,上市公司总数已超过5000家。在这个高维度的投资宇宙中,通过机器学习发掘因子与市场的互动模式,寻找超额风险回报,是A股因子投资提高效率与精准度的重要途径。本报告在上述学界和业界探索的基础上,选取了多类型,高度重要的因子作为输入数据,对比了线性模型,树模型及神经网络模型预测资产回报的性能,系统梳理和评估机器学习应用于A股因子投资的方法与效果。报告采用丰富的数据与长时间窗口,对不同机器学习模型进行稳健性检验,并提炼出实质性建议,为A股因子投资者选择适当的机器学习工具与研究路线提供一定参考与借鉴。
贰
数据采集与处理
数据来源:本文使用了三个数据源,包括CSMAR、Wind和Tushare数据库。这三个数据库均提供相对高质量、专业和全面的金融、经济及交易数据。
数据类别:本文获得的样本数据包括三类,分别是A股上市公司的财务报表数据、交易数据以及部分宏观经济数据。这三类数据为后续特征工程提供基础数据。
时段选择:本文采用的样本数据时间跨度为2017年1月至2023年5月,总计77个月。选取较长的时间序列有助于考察因子的长期稳定性,同时结束日期也较近,可以观察到较新的市场状况,具有一定的时效性。
数据清洗:对所获得的数据进行了缺失值检测,删除了有缺失值的样本;将数据转换到适合模型输入的格式,如浮点数和整数;对数据范围差异大的特征进行Z-score标准化,统一量纲。
叁
特征工程算法对比
3.1 因子构建
本文选取了主流的多因子,以及经学者检验过的重要经研究检验的补充因子,作为主要的因子库。市场上流行的因子较多,如规模因子、盈利因子、动量因子等。这些因子在学术与实践上均得到广泛应用,预测能力较强,本文选取这些因子增加了模型的可靠性。除主流因子外,本文也选取了经研究检验过的具有预测能力的因子。这些因子虽然不及主流因子认可度高,但通过学者的检验已证实其效果,可作为模型的重要补充。
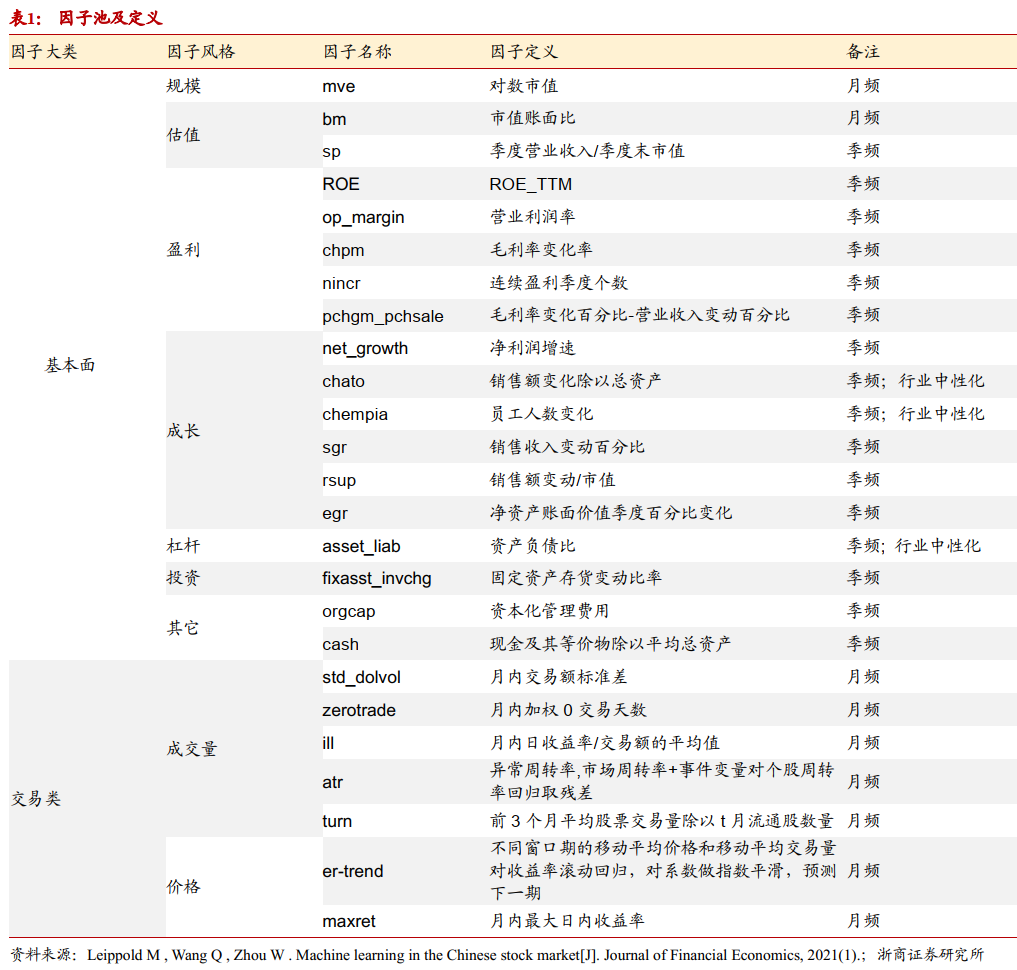
Leippold et al.(2021) 在时序和模型两个角度对比了90个股票因子和11个宏观经济因子在A股的重要程度,并对这些因子进行了重要程度排序。本文借鉴其研究成果,从中挑选出了20个最重要的因子作为后续机器学习模型的输入信息。各因子的重要程度热力图如图1所示。色块越深,代表该因子在A股的重要程度越高。
3.2 模型选择
与传统的因子投资方式不同,本文并不直接根据因子值对股票进行排序选股。传统因子投资根据因子值直接对股票进行排序选股,其假设为高因子暴露值对应高预期收益。
本文引入机器学习模型,将计算所得的因子值作为机器学习模型的特征输入,利用多因子信息拟合股票收益率曲线,进而预测1个月后的预期收益率,然后根据预期收益率的大小执行股票选择。这种方法可以发现多因子之间的复杂互动效应,提高预测准确性。模型输出的预期收益率综合反映了各因子的共同影响,将其作为选股标准可以获得效果更佳的投资组合。
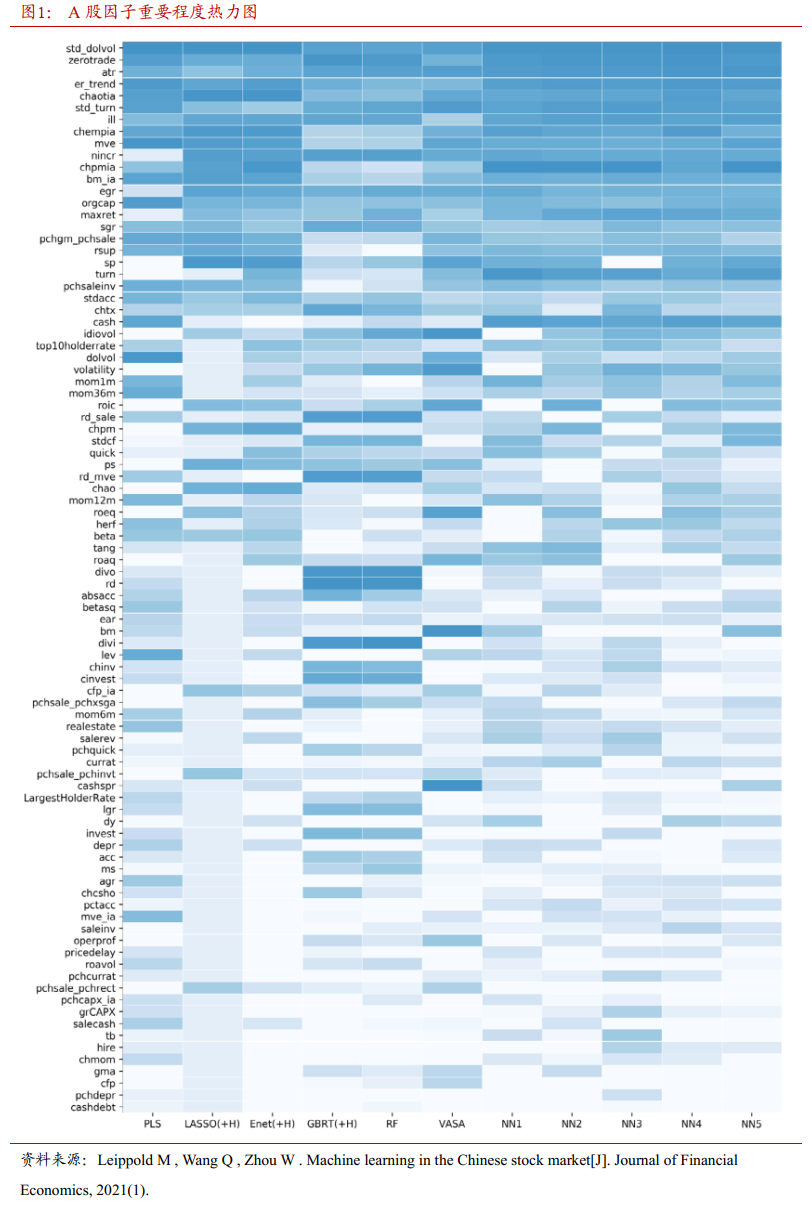
本文选择了3种共10个机器学习模型进行比较,包括3个线性模型、2个神经网络模型和5个树模型,如表2所示。为了便于记叙,后文主要使用缩写指代各模型。
3.3 模型训练
3.3.1 固定时间窗口
本研究分两阶段进行:第一阶段使用历史样本内数据训练机器学习模型;第二阶段应用训练得到的模型在历史样本外进行股票选择与组合构建,并比较不同模型产生的投资组合收益。
历史样本内,使用2007年1月至2018年12月的数据作为训练集训练模型。历史样本外为2018年12月之后。在样本外的各月末,使用模型输出的预期收益率为依据,将样本池内的股票等分为10组,选择预期收益率最高的1组股票作为多头组合,月度更新调仓。
3.3.2 预训练+滚动时间窗口调优
金融市场及其内在机制是动态变化的,因子与收益率之间的关系也不断发生变化,这使得它们之间的对应关系呈现出一定的时变性与非稳定性。如果机器学习模型仅采用固定窗口的训练模式,将全部历史数据作为训练数据集进行单次训练从而确定模型,则该模型无法随着时间变化及时更新与调整。这会导致模型适应历史数据分布与关系,但无法快速跟上数据趋势的变化,模型的判断准确性和有效性可能会下降。
因此,为应对市场与数据的动态变化特性,机器学习模型需要采取滚动时间窗口的训练模式进行补充。该训练模式通过不断更新训练数据集,定期利用最新的数据重新训练模型,可以使模型随着时间变化不断更新,提高其跟踪数据新趋势的能力。
本研究的训练过程分为两个阶段进行:
首先,使用2007年至2013年的历史数据作为初始数据集,预训练各个机器学习模型,得到初始模型参数。这一阶段使用较长时期的数据,可以使模型对基本关系学习较为充分。然后,采用滚动时间窗口的模式进行定期更新。每隔6个月,使用过去60个月的数据重新训练模型,更新模型参数。新训练产生的模型参数替换旧参数,用于后续新的预测与判断。
3.4 组合回测与优化
3.4.1 固定时间窗口组合回测
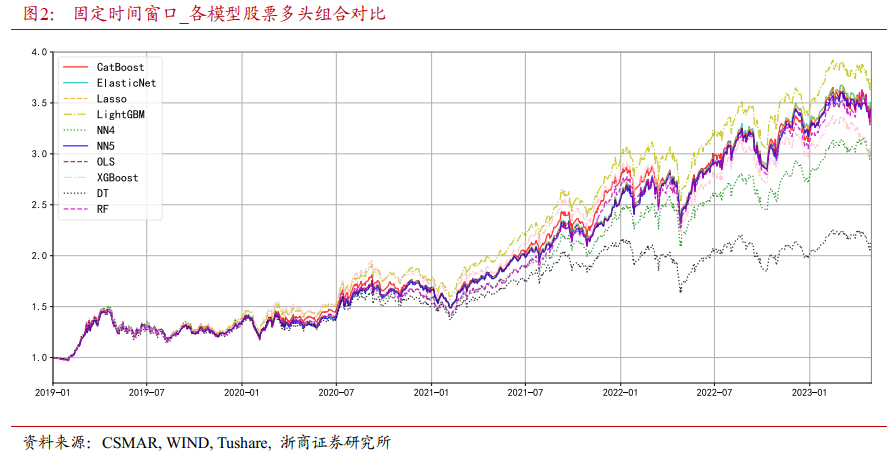
图2展示了固定时间窗口训练模式下,不同模型输出的样本外组合净值曲线。除了决策树模型较差外,其它模型的股票组合走势比较相近,LightGBM模型的表现最优。根据夏普比率对所有模型进行排序,性能最优的模型顺序如下:LightGBM模型、弹性网络(ElasticNet)模型、Lasso模型、OLS模型、NN5神经网络模型、CatBoost模型、随机森林(RF)模型、NN4神经网络模型、XGBoost模型和决策树(DT)模型。
首先,LightGBM模型产生的股票组合获得了最高的夏普比率,表现最为理想。LightGBM模型是一种基于树结构的提升方法,能够有效处理大规模数据,具有较高的预测能力与计算效率。这使其在本研究的大样本条件下取得最优的表现,这也验证了LightGBM模型在金融时间序列预测中的有效性。
其次,除决策树模型外,其他机器学习方法产生的组合净值曲线较为接近。这表明这些模型在表达上存在一定的相似性,可以提取出相对较为接近的预测结果与投资决策。但由于模型之间在预测准确性与泛化能力上仍存在差异,最终的夏普比率也呈现出差异。
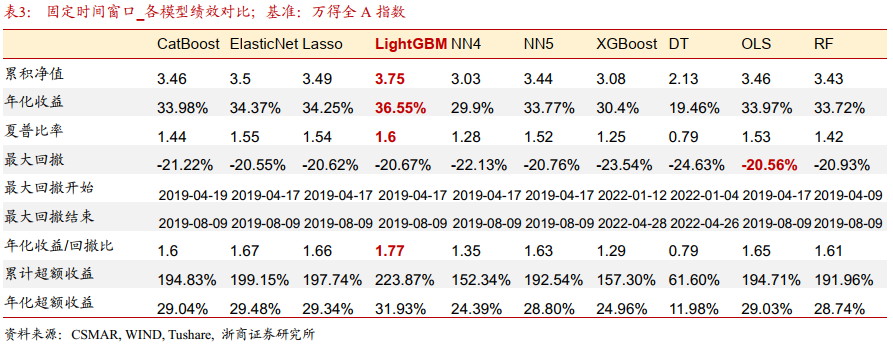
表3展示了各个模型的绩效统计。从获取收益的角度来评价模型,LightGBM的表现最优;控制回撤方面,OLS表现最好;从性价比角度来评价,夏普比在1.5以上的模型有LightGBM, ElasticNet, Lasso, OLS和NN5模型;卡玛比在1.65以上的模型有LightGBM, ElasticNet, Lasso和OLS模型。
LightGBM模型获得了最高的超额收益,表现最为出色。性价比方面,LightGBM模型、弹性网络模型、Lasso模型与OLS模型,这四种方法在表达能力与预测精度上均处于较高水平,可以产生较高的超额收益同时控制回撤风险,这使其夏普比率和卡玛比率较高,体现出较佳的性价比。
相比之下,决策树模型在本文的研究条件下表现比较逊色。决策树模型的泛化能力相对较弱。决策树模型通过树结构来拟合数据,表达能力较为局限,不利于处理复杂与高维的数据。这使其预测结果的准确性与稳定性较其他方法逊色,影响最终的投资表现。
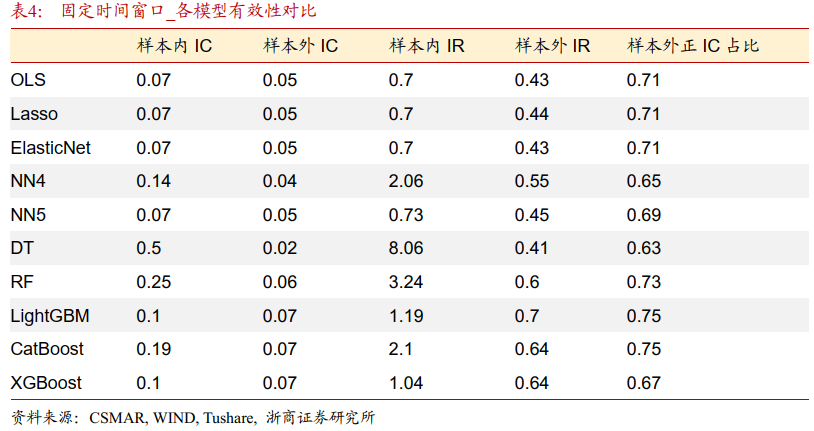
表4展示了不同机器学习模型在样本内外的IC/IR及正IC占比。可以得出以下结论:
第一,不同模型的样本外IC/IR值与实际净值表现的重合度较高。这表明这些模型对因子与收益率之间关系的学习与判断与实际市场情况较为一致,模型的有效性较高。
第二,各个模型的样本外正IC占比差异较大,但是都在60%以上。这表示这些模型大体上都能够学习到因子与收益率之间的方向关系,判断因子变化与收益率变化方向的关系是大概率正确的。只是在判断这种关系的准确度与强度上存在一定差异。
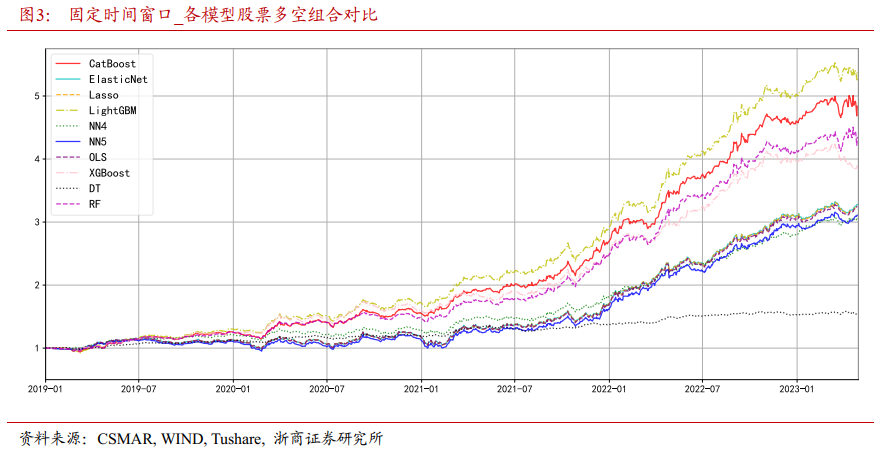
图3显示了不同机器学习模型构建的多空股票组合的净值曲线。可以得到以下观点:
第一,样本外IC/IR值较高的模型对应多空组合的绝对收益表现也较好。如集成学习树模型对应的多空组合实现了较高的绝对收益,神经网络模型对应的多空组合绝对收益表现相对一般。这表明模型判断因子与收益率关系的准确度较高时,其构建的多空组合也能实现较好的绝对收益表现,二者间存在较高的相关性。
第二,样本外IC/IR值较高的模型对应的多空组合的净值曲线走势稳定上升,如集成学习树模型对应的多空组合净值曲线。而神经网络模型的多空组合净值曲线波动较大。
3.4.2 滚动时间窗口组合回测
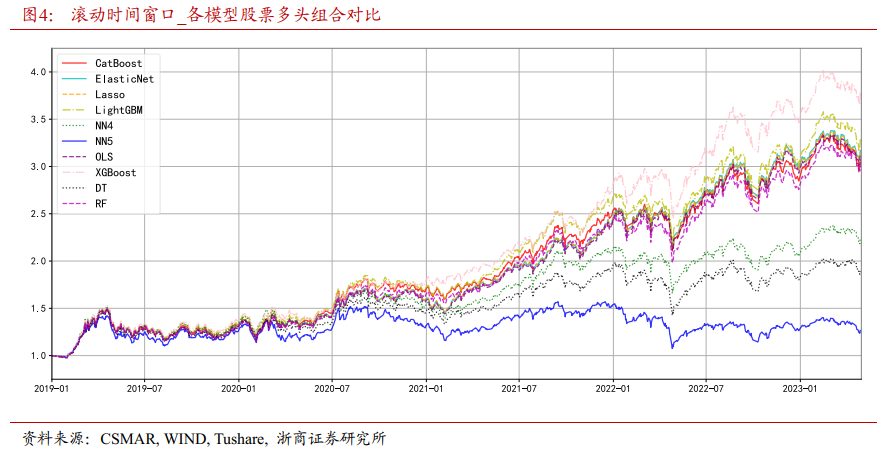
图4呈现了在滚动时间窗口训练模式下,不同机器学习模型构建的多头股票组合的表现。结果显示,与固定窗口训练类似,在滚动窗口下梯度提升树模型对应的多头组合收益能力最强;线性回归模型对应的多头组合表现次之;神经网络模型的表现最差。这表明,不论是固定窗口还是滚动窗口,梯度提升树模型在预测股市收益方面依然具有较大优势。
其次,与固定窗口训练模式相比,除了XGBoost之外,各模型在滚动窗口下对应的多头组合的收益水平略微降低。模型训练所基于的样本变化较大,且样本量减少,使其难以完全记住以往的定量规律与特征,这会在一定程度上削弱模型的表现。
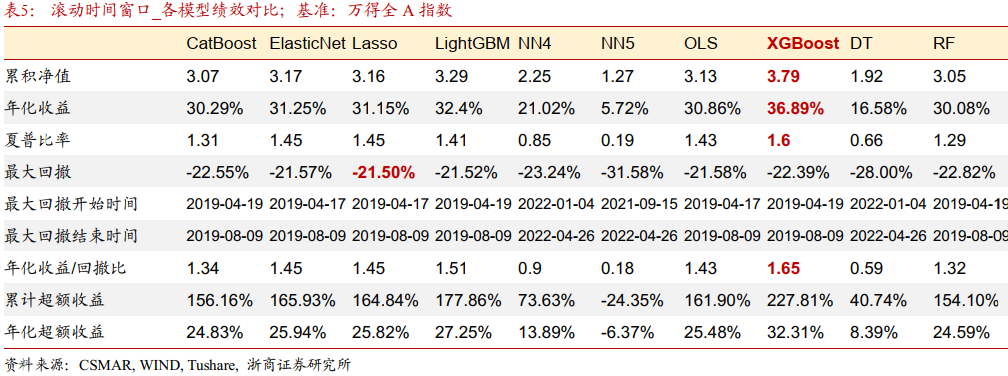
表5展示了滚动时间窗口下各机器学习模型的绩效对比,XGBoost取代LightGBM成为最佳模型。这表明,XGBoost模型在追踪数据变化与趋势的能力上可能更加出色,可以通过定期更新更好适应新的数据特征与关系变化。神经网络模型相比在这方面稍显不足。

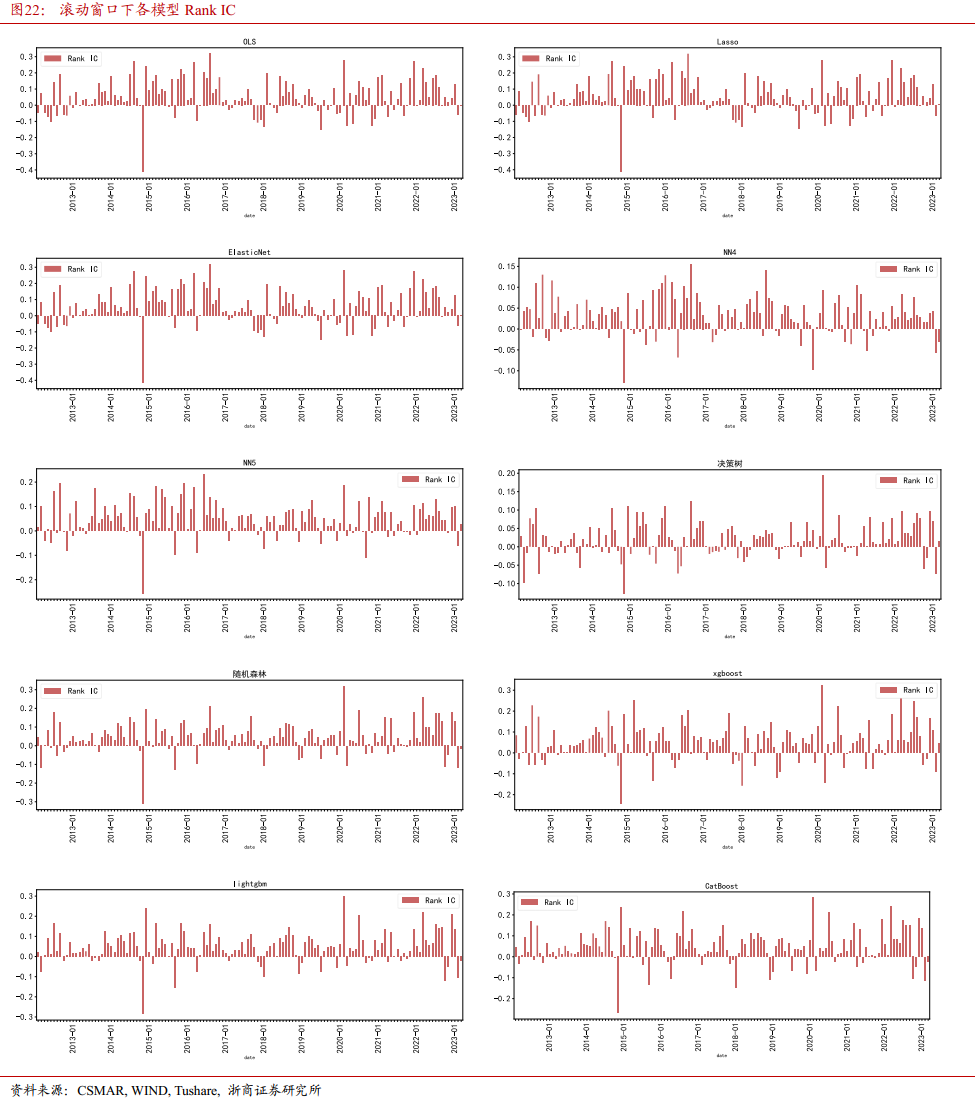
表6展示了滚动时间窗口训练模式下各机器学习模型样本外IC/IR及正IC占比。相比固定时间窗口,神经网络模型的IC/IR表现有所降低,其它模型的IC/IR基本保持一致。
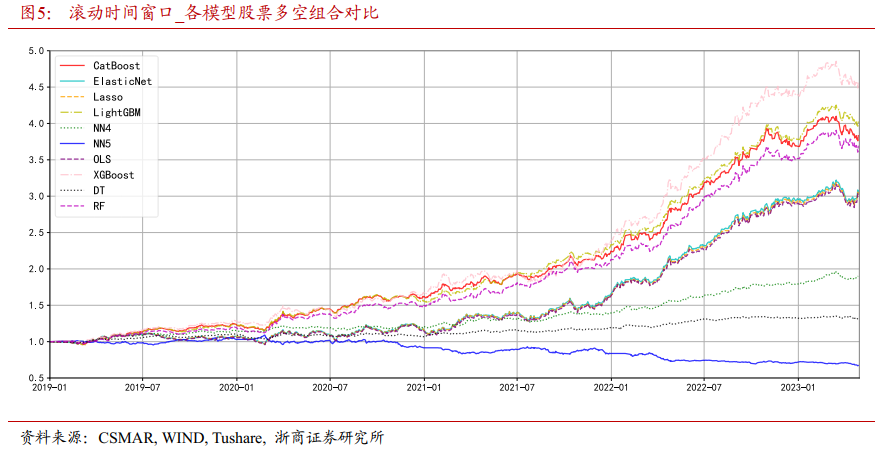
图5展示了在滚动时间窗口训练下,不同机器学习模型构建的多空股票组合的净值曲线。相比固定窗口训练,可以观察到以下结论。
第一,神经网络模型的投资表现下降幅度较大,多空组合绝对收益甚至为负值。神经网络模型由于其架构的高维复杂性,在进行频繁的重训练时参数波动较大,这会使其预测结果出现较剧烈的变动。此外,神经网络模型在构建过程中通常会基于大量历史数据进行迭代训练,这使其对历史统计模式与依赖性较为敏感。但在滚动窗口下,神经网络模型需要不断丢弃过往的训练样本,这会对其记忆与拟合产生较大的干扰,使模型表现受到较大影响。
第二,XGBoost模型对应的多空组合实现了最佳的绝对收益和最平稳的净值曲线,其表现一枝独秀,大幅领先于其他机器学习模型。这再次证实XGBoost模型在跟踪数据变化与学习新关系方面具有显著优势,可以最大程度地利用滚动窗口带来的益处,通过更新获取更高的准确率与更稳定的预测,构建出表现更加出色的多空组合。
3.4.3 固定窗口与滚动窗口结果对比
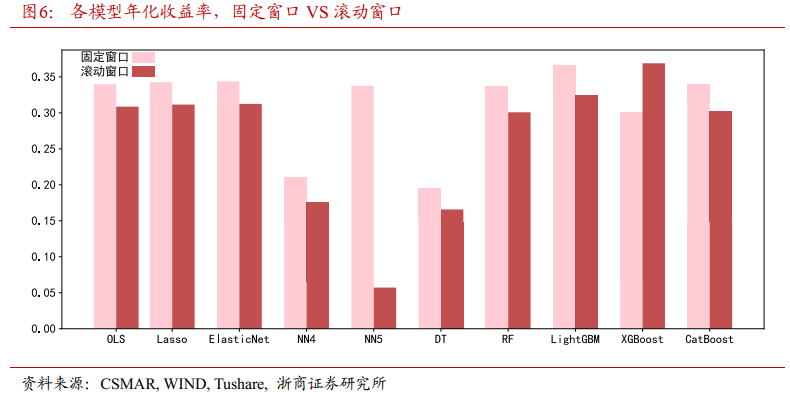
图6展示了不同机器学习模型在固定时间窗口训练模式和滚动时间窗口训练模式下输出的多头股票组合的年化收益率对比。可以得出以下结论:
第一,虽然用于模型训练的样本量大幅减少,但是除了神经网络模型外,其它模型依旧保持了较好的投资表现。这表明机器学习模型对A股有一定的动态适应能力。
第二,除XGBoost模型外,其他机器学习模型输出的多头股票组合在采用滚动时间窗口训练模式后,年化收益率均略有下降。这说明,窗口长度的选择具有重要影响。滚动窗口虽然可以使模型更快速地适应市场变化,但也会加剧模型的波动性与记忆衰减。
第三,NN4和NN5两个神经网络模型的年化收益率在滚动窗口下明显下降。这可能是因为神经网络模型相比其他机器学习模型,其对超参数的选择更加敏感,表现出更强的随机性。神经网络模型的结构与参数如网络层数、每层神经元数量等超参数的设定会对其结果产生较大影响。如果超参数选择不当,神经网络模型的预测能力会迅速下降。而在滚动窗口下,由于数据变化频繁,神经网络模型需要不断调整自身结构与参数以适应新数据,这使其超参数选择的难度加大,随机性也因此增强。
相比而言,其他机器学习模型如树模型的超参数对结果的影响较小,自适应能力也更强。所以在滚动窗口下,即使需进行频繁更新,其预测能力的下降风险也较小。
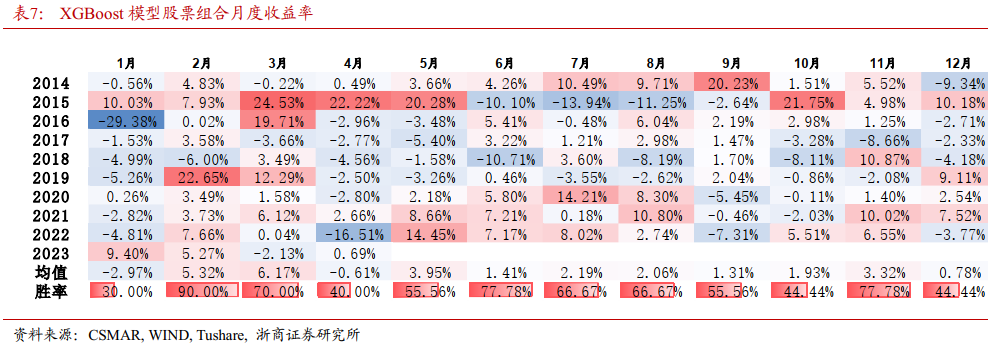
表7展示了XGBoost模型从2014年1月至2023年4月输出的股票组合月度收益率。可以观察到,模型在1月和4月的胜率相对较低。可能的原因在于,1月份信息不确定性大,变化频繁,会影响模型的判断准确性。年初阶段,上市公司宣布的前瞻性信息及市场预期变化较大,这增加了模型预测的难度,产生的错误判断概率也较高;4月份为年报季,存在逻辑被证伪导致的风格切换或者市场内在机制变动的情况,对模型产生一定冲击。
3.5 因子重要性评价

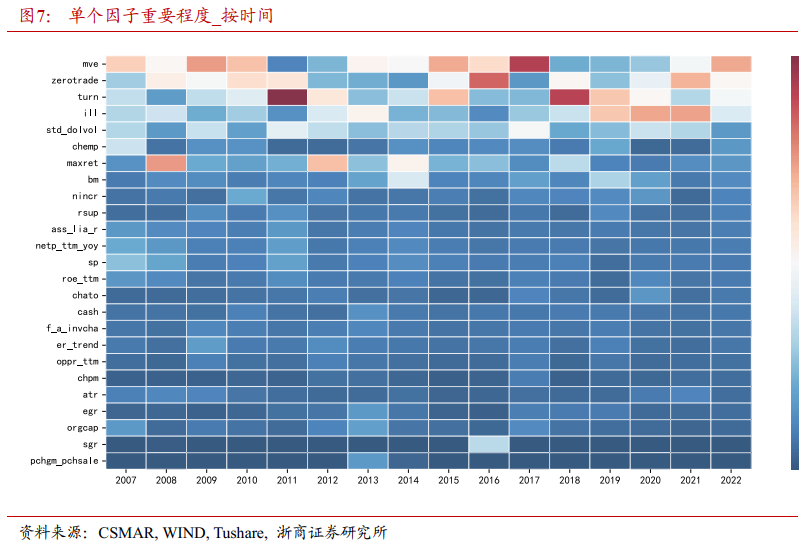
图7显示了单个因子在时间上的重要性变化,采用热力图的形式展示。色块颜色越偏暖色,则其重要性越高。自2007年起,重要性较高的因子主要是成交量相关因子和规模相关因子,成交量与规模成为决定股票短期价格变动的重要力量。
2022年,重要性排名前5的因子是mve(对数市值)、zerotrade(加权0交易天数)、turn(换手率)、ill(收益率/成交额)和std_dolvol(交易额标准差),其中4个是交易成交量相关因子,1个是规模相关因子。Zerotrade,turn和ill反映股票的交易频率及每笔交易的价格影响力,std_dolvol则测度股票成交额的波动性与股票的交易活跃度。
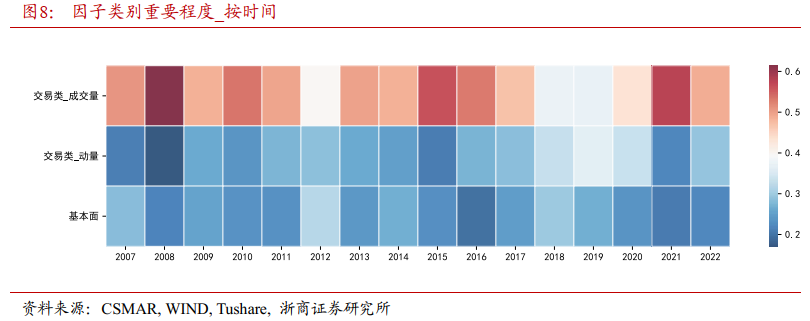
图8显示了不同因子类别在时间上的重要性变化,采用热力图形式展示。2007年至2022年间的各个年份,成交量相关因子类别一直都是影响股票短期定价最为显著的因子类别。成交量因子类别反映了股票的交易活跃程度和易涨易跌性。在A股市场,该因子类别对股票短期表现有较大影响。相比之下,基本面因子类别和动量因子类别的重要性变化则较为平稳。
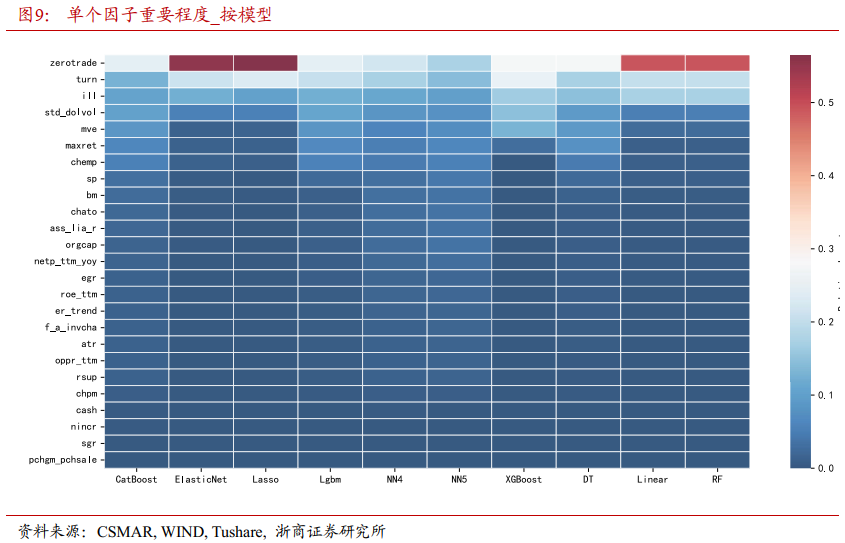
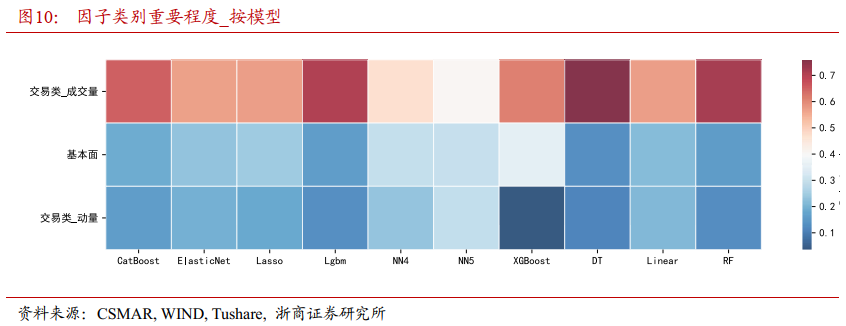
图9、图10采用热力图形式分别展示了单个因子和因子类别在不同模型上的重要性变化。各个模型基本一致地确认成交量相关因子的重要性最高。不同的机器学习模型从各个因子视角解释股票价格变动,但在判断成交量因子的重要性上达成共识,这有力证明成交量是决定股票短期价格波动的关键因素。
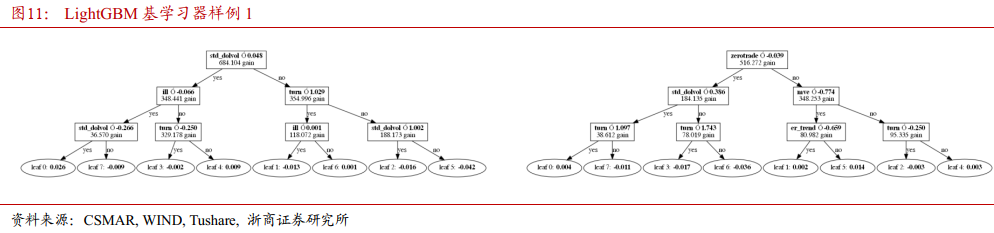
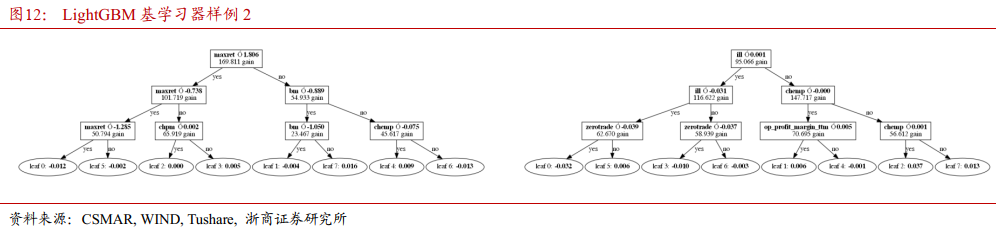
考虑交易类因子与股票预期收益率之间的关系。图11、图12显示了4个排序靠前的LightGBM模型基学习器,根节点分别为std_dolvol, zerotrade, maxret和ill。
根据这4个基学习器可知,若成交额标准差小于阈值,股票次月预期回报较高;若换手率小于阈值,股票次月预期回报较高;若收益率/成交额大于0,股票次月预期回报较高;若月内最大日收益率的取值范围较小,股票次月预期回报较高。
LightGBM模型更加认同稳定的成交量,正向的每笔交易价格影响力,短期内未发生过大幅度的筹码交换及短期内价格低波动,这些特征能给股票带来更高的短期回报。
肆
机器学习模型检验
4.1 固定窗口训练各模型有效性测试
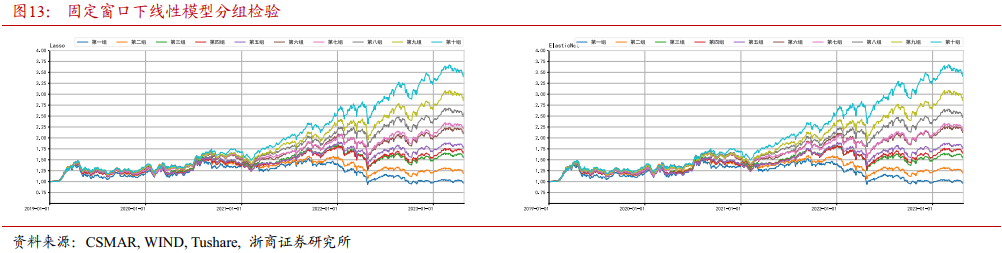
4.1.1 各模型分组检验
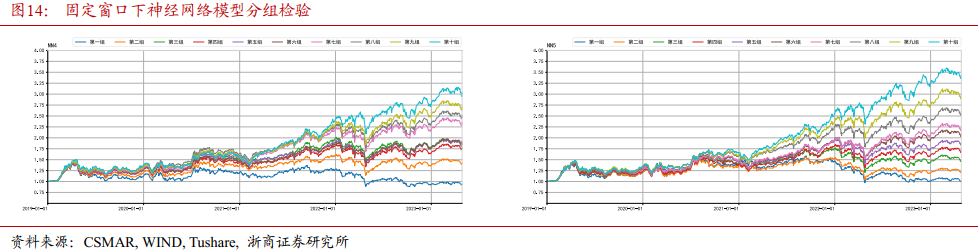
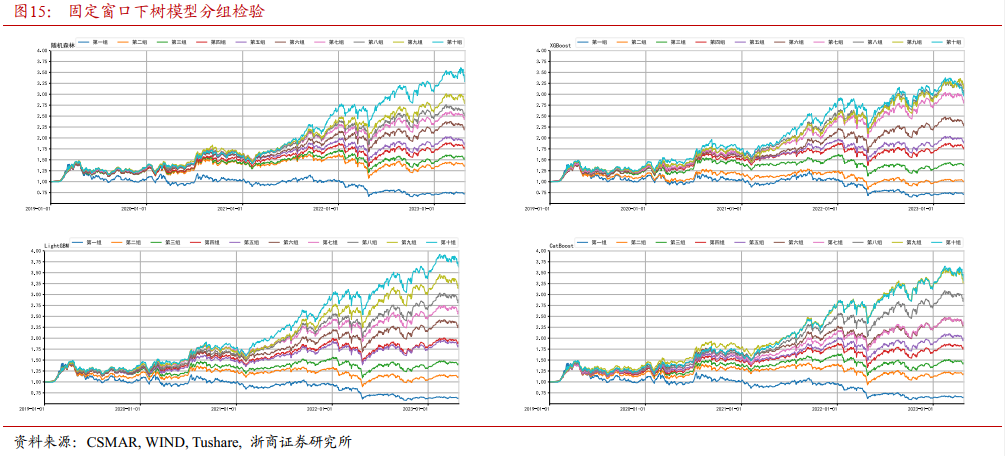
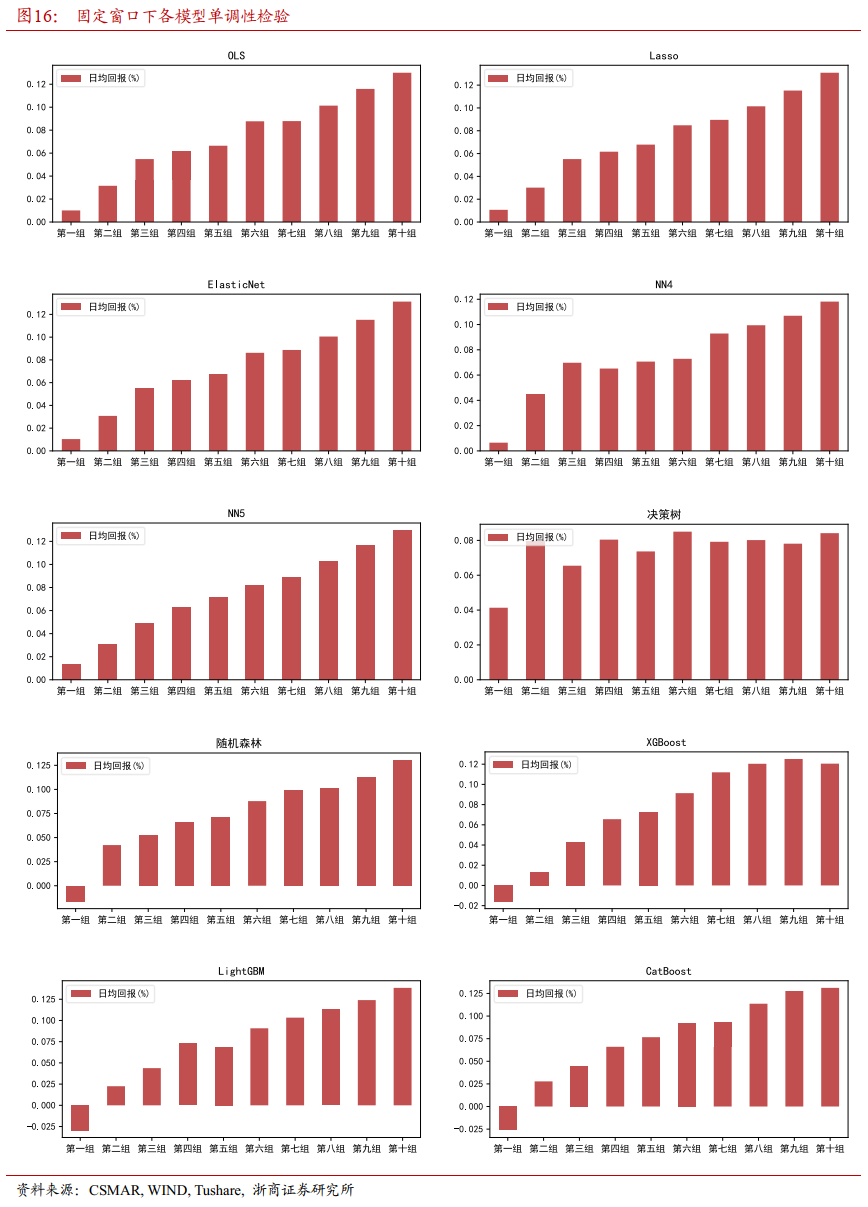
4.1.2 各模型单调性检验
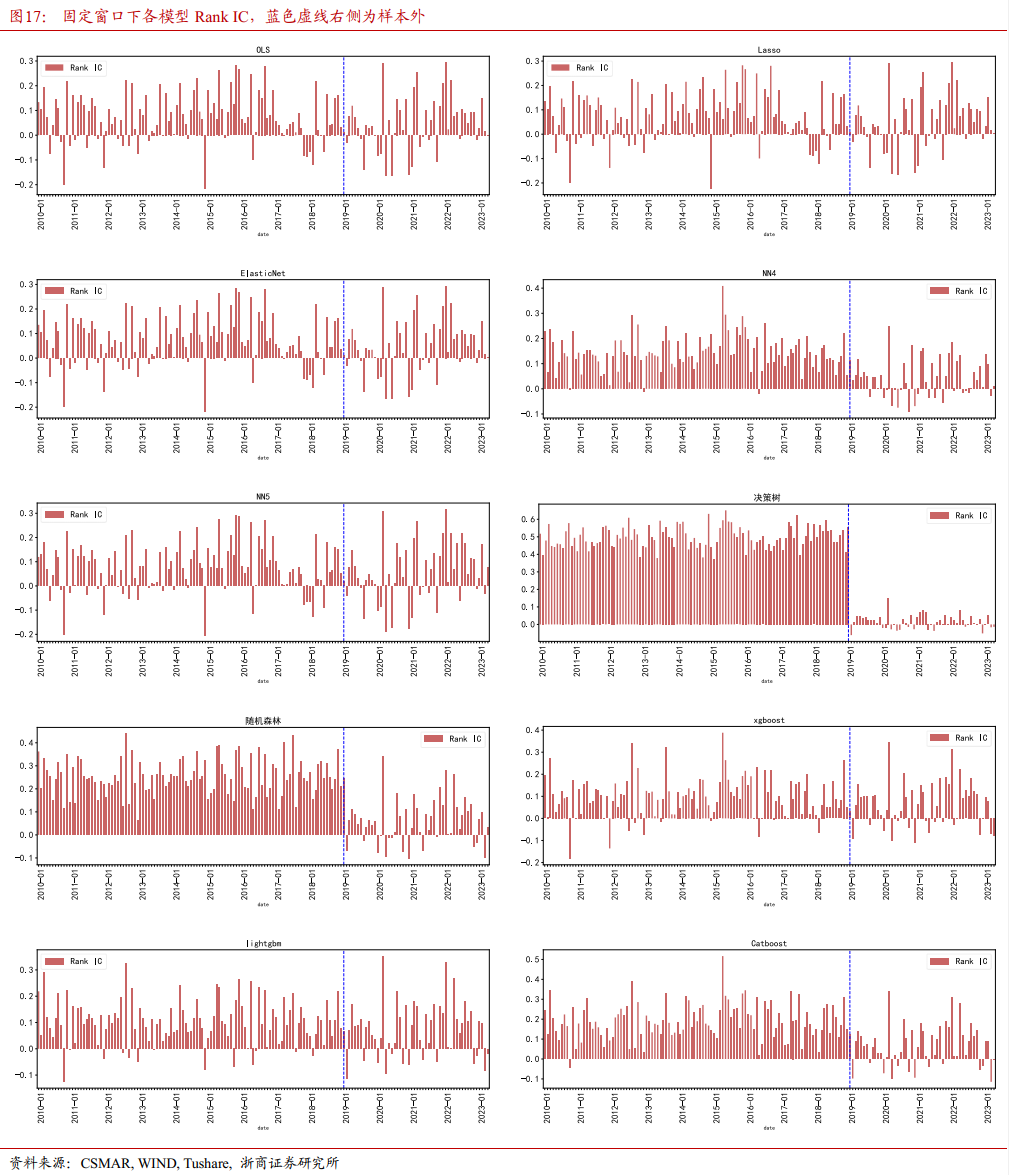
4.1.3 各模型IC检验
4.2滚动窗口训练各模型分组测试
4.2.1 各模型分组检验
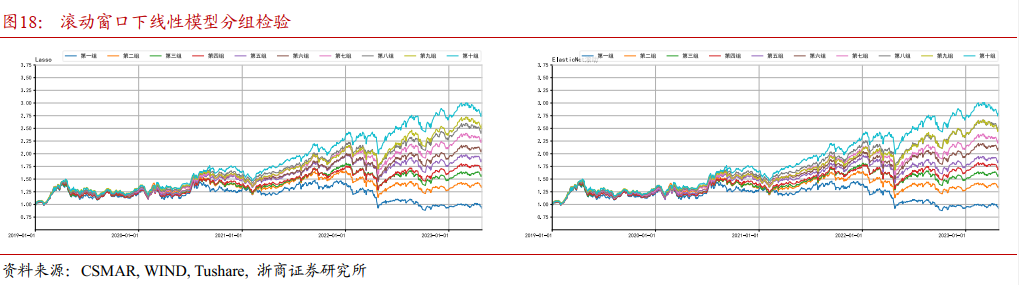
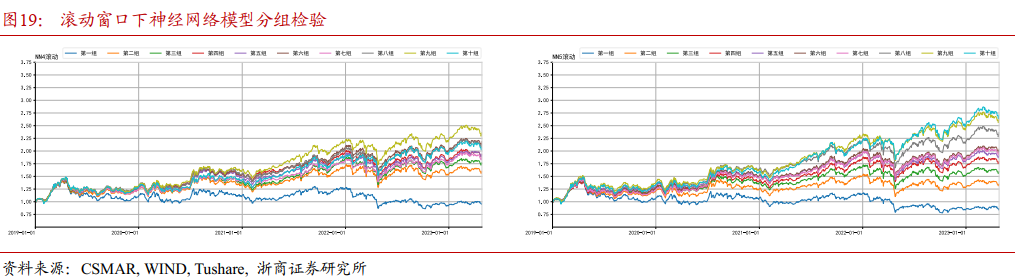
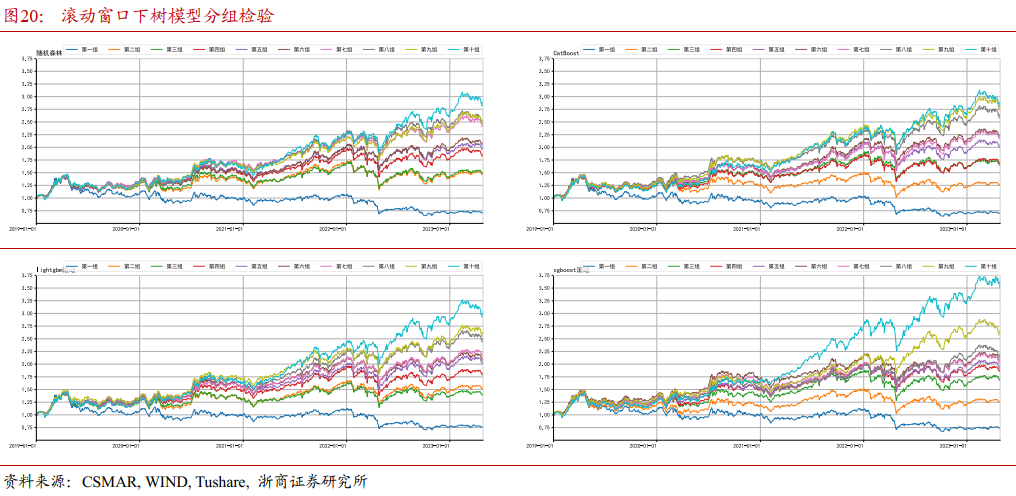
4.2.2 各模型单调性检验
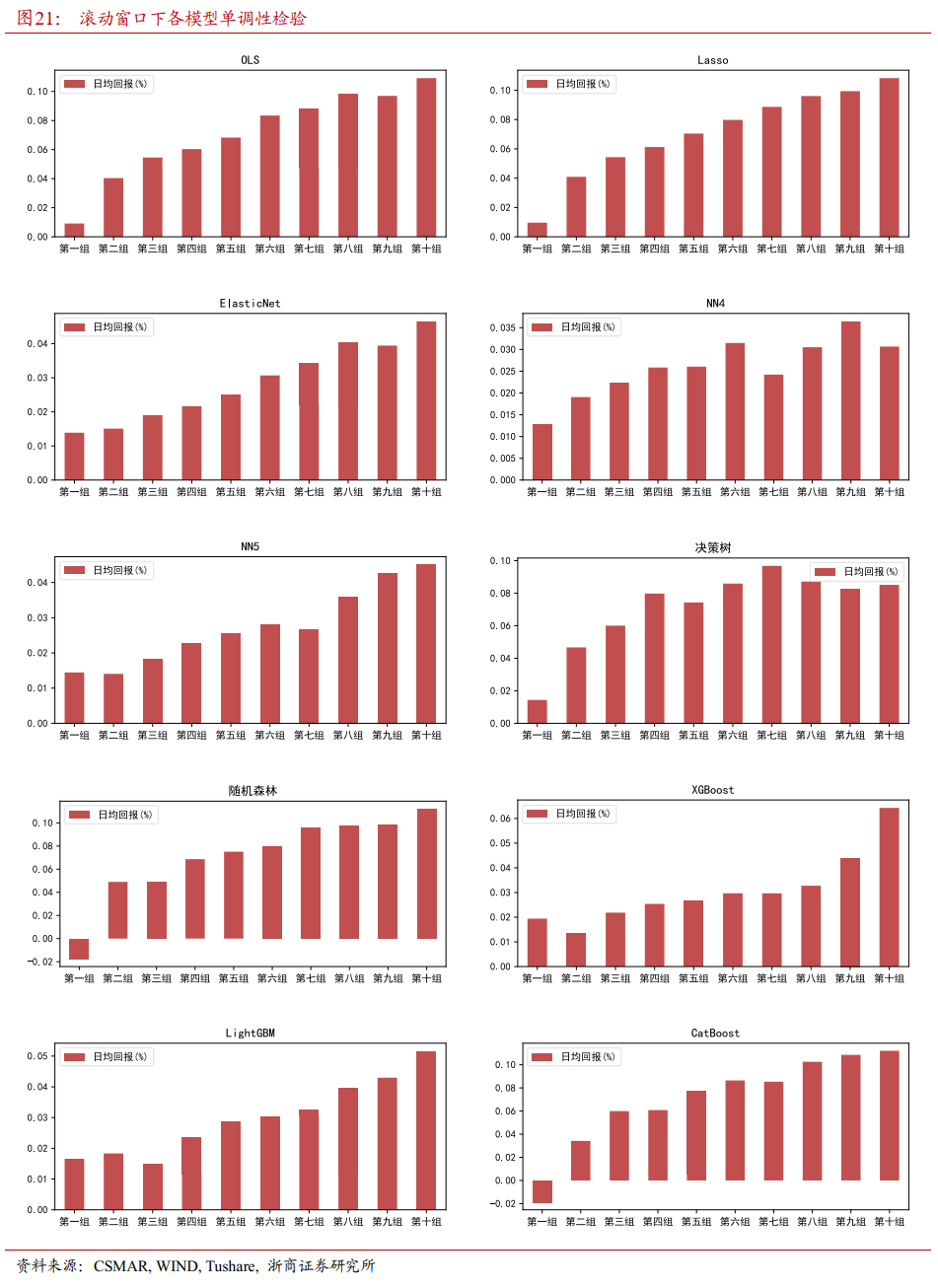
4.2.3 各模型IC检验
伍
结论
机器学习模型具有效提高投资组合绩效的能力。对A股市场短期回报预测而言,梯度提升树模型的表现最佳。梯度提升树模型可以学习因子和收益率之间复杂的非线性关系,具有强大的特征交叉作用与拟合能力。这使其在如A股市场这种信息环境变化频繁且关系复杂的市场中,预测效果最佳。相比而言,线性学习模型的表现次之。神经网络模型由于对超参数过于敏感,其表现并不稳定。
机器学习模型对A股市场环境具有较强的自适应能力。机器学习模型可以通过训练过程自动学习环境中的信息与关系,建立判断逻辑。当环境发生变化时,模型也可以通过再训练来更新自身,适应新的环境特征与信息。这使得机器学习模型可以适应A股市场的高变化环境,保持较强的判断与预测能力。
交易类信息是影响个股短期定价最重要的因素。不同的机器学习模型在不同的年份都认同交易类信息对于股票短期回报预测的任务是最重要的输入信息。交易类信息对个股收益的影响具体体现在成交额稳定、成交对价格有正向影响、短期内未发生过大幅筹码交换和价格变动的股票,其短期预期收益率更高。
陆
风险提示
模型测算风险:超参数设定对模型结果有较大影响;收益指标等指标均限于一定测试时间和测试样本得到,收益指标不代表未来。
模型失效风险:机器学习模型基于历史数据进行测算,不能直接代表未来,仅供参考。
柒
参考文献
[1] Fama, Eugene F., and Kenneth R. French. "Migration." Financial Analysts Journal, 63(3), (2007): 48-58.
[2] Ma, Zheng, et al. "Learning stock relationships from graph neural networks and attention mechanisms." arXiv preprint arXiv:1911.10947 (2019).
[3] Zhang, Xiao, and Dacheng Zhao. "Island-Attention Networks for Stock Movement Prediction." arXiv preprint arXiv:2002.08599 (2020).
[4] Fama, Eugene F., and Kenneth R. French. "Dissecting anomalies with a five‐factor model." The Review of Financial Studies 29.1 (2016): 69-103.
[5] Lewellen, Jonathan. "Factor investing and trading costs." AFA Presidential Address (2015).
[6] Harvey, Campbell R., Yan Liu, and Heqing Zhu. "... and the cross-section of expected returns." Rev. Financ. Stud. 29 (2015): 5-68.
[7] Frazzini, Andrea, Jacques Friedman, and Lukasz Pomorski. "Deactivating active share." Financial Analysts Journal 74.2 (2018): 100-107.
[8] Leippold M , Wang Q , Zhou W . Machine learning in the Chinese stock market[J]. Journal of Financial Economics, 2021(1).
[9] Gu S , Kelly B , Xiu D . Empirical Asset Pricing via Machine Learning[J]. Review of Financial Studies, 2020, 33.
详细报告请查看20230615发布的浙商证券金融工程深度报告《机器学习与因子(一):特征工程算法测评》
特别声明:
法律声明:
本公众号为浙商证券金工团队设立。本公众号不是浙商证券金工团队研究报告的发布平台,所载的资料均摘自浙商证券研究所已发布的研究报告或对报告的后续解读,内容仅供浙商证券研究所客户参考使用,其他任何读者在订阅本公众号前,请自行评估接收相关推送内容的适当性,使用本公众号内容应当寻求专业投资顾问的指导和解读,浙商证券不因任何订阅本公众号的行为而视其为浙商证券的客户。
本公众号所载的资料摘自浙商证券研究所已发布的研究报告的部分内容和观点,或对已经发布报告的后续解读。订阅者如因摘编、缺乏相关解读等原因引起理解上歧义的,应以报告发布当日的完整内容为准。请注意,本资料仅代表报告发布当日的判断,相关的研究观点可根据浙商证券后续发布的研究报告在不发出通知的情形下作出更改,本订阅号不承担更新推送信息或另行通知义务,后续更新信息请以浙商证券正式发布的研究报告为准。
本公众号所载的资料、工具、意见、信息及推测仅提供给客户作参考之用,不构成任何投资、法律、会计或税务的最终操作建议,浙商证券及相关研究团队不就本公众号推送的内容对最终操作建议做出任何担保。任何订阅人不应凭借本公众号推送信息进行具体操作,订阅人应自主作出投资决策并自行承担所有投资风险。在任何情况下,浙商证券及相关研究团队不对任何人因使用本公众号推送信息所引起的任何损失承担任何责任。市场有风险,投资需谨慎。
浙商证券及相关内容提供方保留对本公众号所载内容的一切法律权利,未经书面授权,任何人或机构不得以任何方式修改、转载或者复制本公众号推送信息。若征得本公司同意进行引用、转发的,需在允许的范围内使用,并注明出处为“浙商证券研究所”,且不得对内容进行任何有悖原意的引用、删节和修改。
本篇文章来源于微信公众号: Allin君行