深度专题122:“逐鹿”Alpha 专题报告--基于openFE的基本面因子挖掘框架
重要提示:通过本订阅号发布的观点和信息仅供中信建投证券股份有限公司(下称“中信建投”)客户中符合《证券期货投资者适当性管理办法》规定的机构类专业投资者参考。因本订阅号暂时无法设置访问限制,若您并非中信建投客户中的机构类专业投资者,为控制投资风险,请您请取消关注,请勿订阅、接收或使用本订阅号中的任何信息。对由此给您造成的不便表示诚挚歉意,感谢您的理解与配合!
核心结论
本文介绍了一种基于openFE的基本面因子挖掘方法,将三大报表的数据以及基础算子之间按照一定的结构进行排列组合,构建出70万个不同风格类型的因子,再利用openFE的两步筛选法,筛选出不同风格类型下表现最好的合成因子。对比因子的表现,动量,市值,行业为最重要的因子,其次估值及成长因子表现较好,质量因子在A股的表现较为一般。利用构造的合成因子以及基础因子,训练月频的选股模型,模型在回测区间内,全市场内选股的年化超额为21%,夏普比率为1.19。
简介
本文我们将openFE框架应用于基本面因子挖掘,不同于DeepLOB和AlphaZero,openFE是一种基于枚举法的Expand-And-Reduce框架,能够高效的检验大量因子(>10^6)
OpenFE
openFE生成的因子结构较为简单,可解释性较好,因此非常适合用于基本面因子挖掘。本文采用三大表中的数据作为基础特征,在此基础上构建合成因子,通过进一步筛选,保留表现较好的因子作为新的alpha因子。OpenFE是一个基于枚举法的Expand-And-Reduce框架,首先通过基础特征以及算子的排列组合构建所有可能的因子。而后通过一个两步的筛选步骤,对因子进行筛选。
合成因子
通过openFE的两步筛选,保留各风格重要性最高的10个因子。从各类风格因子的平均重要性可以看出,价值因子的重要性最高,其次为成长因子,质量因子的平均重要性最低。在基础因子中,动量,市值以及行业是表现最好的三个因子
因子回测
利用10个基础因子以及50个合成因子,构建选股模型。策略的表现较为稳定,过去不到3年的时间累计收益达到91.2%,,累计超额收益达到79.4%,年化超额收益21%,夏普比率为1.19
主要内容
一、简介
因子挖掘是金融工程的一个重要方向,它试图从海量的金融数据中提取有价值的信息,并将其应用于投资组合的管理。通过对因子的定义、评估和组合,因子投资策略试图实现长期的超额收益。
常见的因子包括价值、动量、规模、质量和波动率。因子挖掘需要大量的数据收集和预处理、因子评估和回测,还需要统计学和计算机科学的技能。
在实际应用中,因子挖掘可以与机器学习、统计学和计算机科学相结合,以提高因子投资的效率和准确性。因子挖掘的成功与否取决于因子的选择和组合,以及因子评估的准确性。
总之,因子挖掘是一种有前途的金融工程方向,具有广泛的应用前景和潜力。
--chatGPT
以上因子挖掘的介绍生成自chatGPT, 随着机器学习尤其是深度学习的发展,各类应用早已深入日常生活,在量化投资领域,也有了较为成熟的应用。
在之前的系列报告中,我们介绍过深度学习模型DeepLOB和基于进化算法的AlphaZero,DeepLOB通过巧妙设计数据结构以及网络结构,使得每一层生成的因子具有一定的经济学意义,AlphaZero是基于进化算法的因子挖掘框架,两者分别代表了深度学习以及启发式算法在因子挖掘中的应用。本文我们将openFE框架应用于基本面因子挖掘,不同与以上两种方法,openFE是一种基于枚举法的Expand-And-Reduce框架,能够高效的检验大量因子(>10^6)。
三种方法分别代表了深度学习,启发式算法以及枚举法在因子挖掘中的应用,深度学习法的优点在于效率较好且样本内效果最好,缺点是生成的因子无法解释且要求算子可导。启发式算法效率介于枚举法和深度学习之间,能够生成批量因子,因子解释性一般,无法保证找到全局最优。枚举法是一种暴力算法,一般生成的因子形式都较为简单,可解释性较好,生成因子数量较多,导致逐一检验时效率较低,因此需要对因子检验的效率进行优化。

二、OpenFE
不同于AlphaZero用于量价因子挖掘,openFE生成的因子结构较为简单,可解释性较好,因此非常适合用于基本面因子挖掘。本文采用三大报表中的数据作为基础特征,在此基础上构建合成因子,通过openFE进一步筛选,保留表现较好的因子作为新的合成因子。
OpenFE是一个基于枚举法的Expand-And-Reduce框架,首先通过基础特征以及算子的排列组合构建具有一定结构的风格因子。而后通过两步的筛选步骤,对因子进行筛选,保留最终特征重要性最高的因子。
2.1 因子Expand
基础特征采用三大报表中的数据(资产负债表,损益表,现金流量表),其中资产负债表为时点数据,损益表和现金流量表为时期数据,我们将损益表和现金流量表中的数据均转为季频数据。
三大报表中的字段共计有100多,大部分字段缺失值较多,对于缺失值大于10%的字段,予以剔除。利用剩下的所有字段训练一个LGBM模型,保留每张报表内重要性排名前15的因子。在这些因子的基础上,再加入市值,行业,动量(过去一个月收益率)三个对股票收益解释度非常高的因子。共计45个基础特征以及3个额外添加的特征。
为使得因子具有较好的可解释性,采用一些较为简单的算子,包括四则运算(+,-,*,/)、同比算子(YOY)、环比算子(QOQ)、以及横截面排序算子(CSRank)。
如果采用暴力方式进行排列组合,即使是简单的二阶因子,以上因子以及算子能够组合出~10^9个因子,难以进行处理。
不同类型的风格因子往往具有一定的结构特征,例如常见的PE,PB,PS等估值因子均为简单的一阶因子,分子端净利润/净资产/主营业务收入来自三大报表,分母端为总市值。在构造估值类合成因子时,我们将其扩展为二阶因子,具体做法为分子端的单因子改为a±b的形式,其中a,b∈损益表/现金流量表/资产负债表,分母端为总市值,当a=b,且算子为+时,此二阶因子等价于PE。
同理,借鉴资产负债率,ROE,净利润现金比率,PE,净利润同比增长率等因子结构,本文构建了杠杆因子,收益因子,质量因子,估值因子,成长因子共5类风格因子,因子结构如下表所示。因子均为二阶因子(不考虑CSRank),总因子数量~70万左右。

2.2 因子Reduce
原始的70万因子逐一检验效率较低,openFE采用两步的筛选方法,极大的提高了筛选效率。在第一步筛选中,采用了successive halving(连续二分法)进行单因子检验。具体做法是首先采用部分小样本,对每一类风格的所有因子进行单因子模型LGBM的训练,计算特征的模型表现。下一轮增加样本数量,保留第一次训练中表现较好的部分因子,再此进行训练,以此类推,不断增加样本数量,减少因子数量,直至用全样本训练,得到最终筛选的因子列表。

经过第一轮的单因子筛选后,保留约1/16的因子,此时因子数量依旧较多(>103),为了进一步筛选因子,且剔除因子间的相关性问题,第二轮用所有保留的合成因子以及原始的48个基础特征进行多因子模型LGBM的训练,最终利用LGBM输出所有因子的重要性排序。
LGBM在计算特征重要性时有两种方式,分别为gain和split,其中gain是通过计算总的gini增益来得到特征重要性,split是计算模型中特征出现的次数来计算得到特征重要性,本文采用gain来计算特征重要性。
在利用LGBM进行训练时,openFE采用feature boosing的方法计算因子的边际贡献,即首先利用基础特征计算模型的预测值y1以及效果metric1,将y1作为新的训练的初始值,用新因子训练得到y2和metric2,新因子的边际贡献为metric2 -metric1。
三、合成因子
通过openFE的两步筛选,保留各风格重要性最高的10个因子。最终的因子列表为:


各类风格因子的平均重要性如下图所示,可以看出,价值因子的重要性最高,其次为成长因子,质量因子的平均重要性最低。

除了合成因子外,同样在原始的48个因子中,筛选出表现最好的10个基础因子。其中动量,市值以及行业是表现最好的三个因子。

四、因子回测
利用以上10个基础因子以及50个合成因子,构建选股模型。具体做法是从2020年1月31日至2022年12月31日,每月滚动训练LGBM模型,模型的输入为过去10年的月频因子,预测目标为未来一个月收益率。训练集长度为9年,测试集为1年,按照时间先后进行切分。股票池为全A股票,剔除其中的次新股,ST股,涨跌停股票以及流动性过低的股票(日成交金额<500万或者换手率<0.02%)。每次调仓等权买入得分最高的400只股票。
最终策略的表现如下图所示:
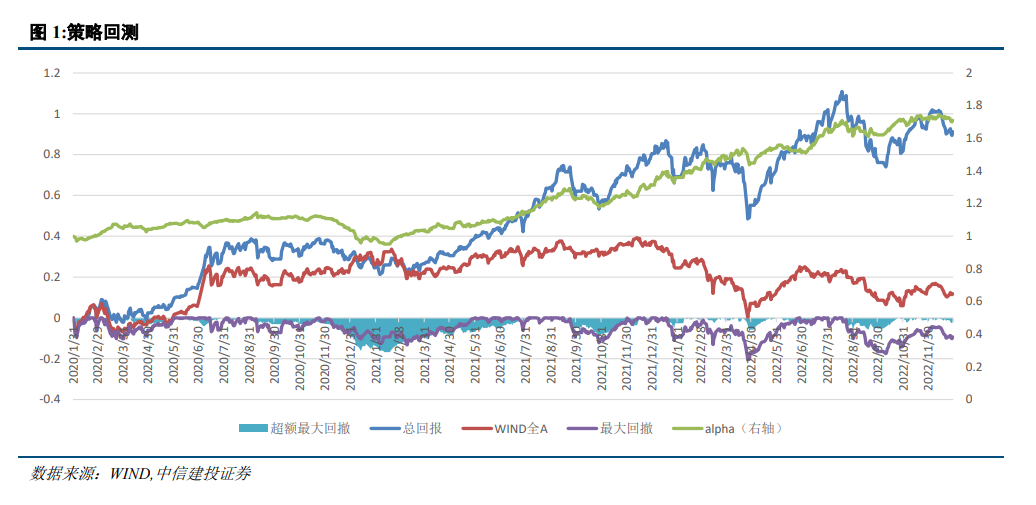
策略的表现较为稳定,过去不到3年的时间累计收益达到91.2%,,累计超额收益达到79.4%。策略的具体表现如下表所示:

分年度来看, 在过去3年均能取得正向超额收益。其中21年和22年策略的表现较为突出,超额收益均超过20%。
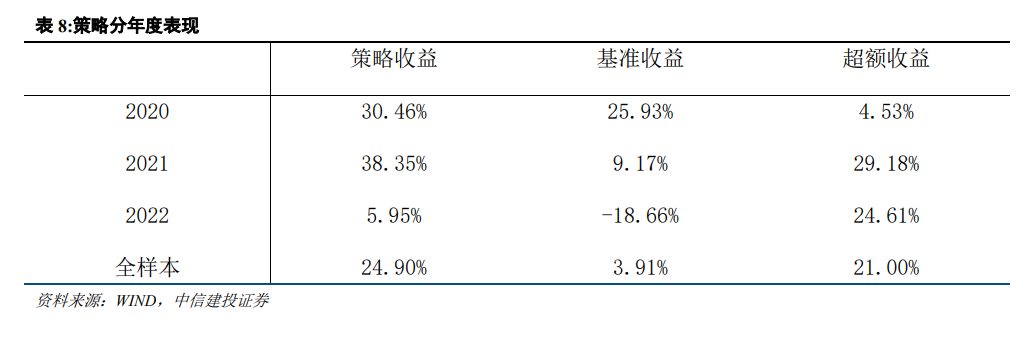
从因子的分组收益率可以看出,因子单调性较好,且多头组收益显著。
随着每次训练的样本区间发生变化,模型的特征重要性排序也会随之发生变化。对比 2020年1月以及2022年11月两次模型的特征重要性排序,动量,市值,行业均为最重要的因子,其次是估值因子和成长因子。在所有的基础因子中,应交税费在两次模型中的表现较好。在2020年1月,大部分因子均为成长因子和估值因子,在2022年11月,杠杆因子,盈利因子的数量有所增加。



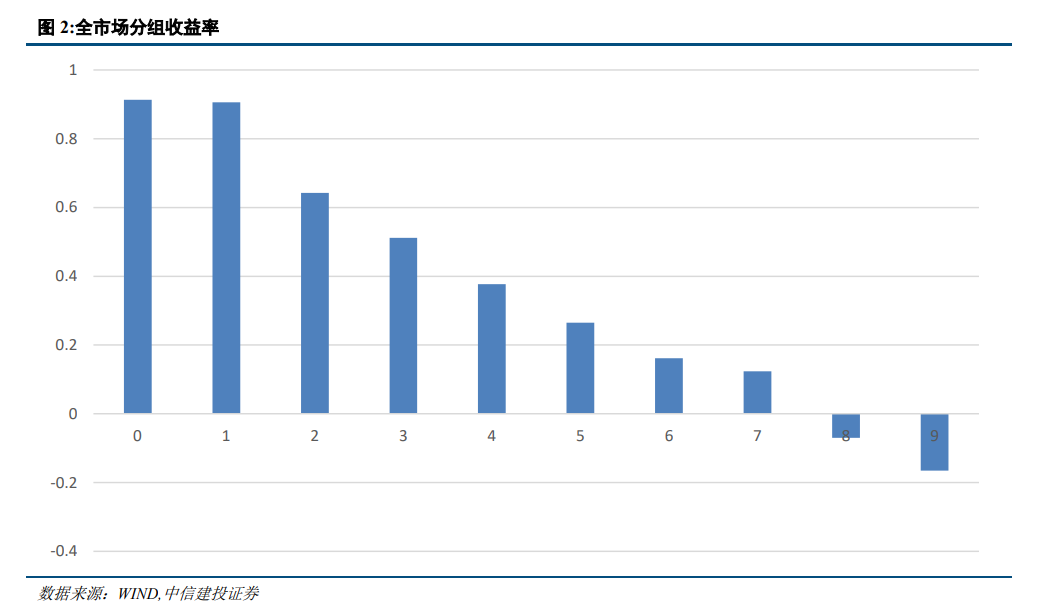
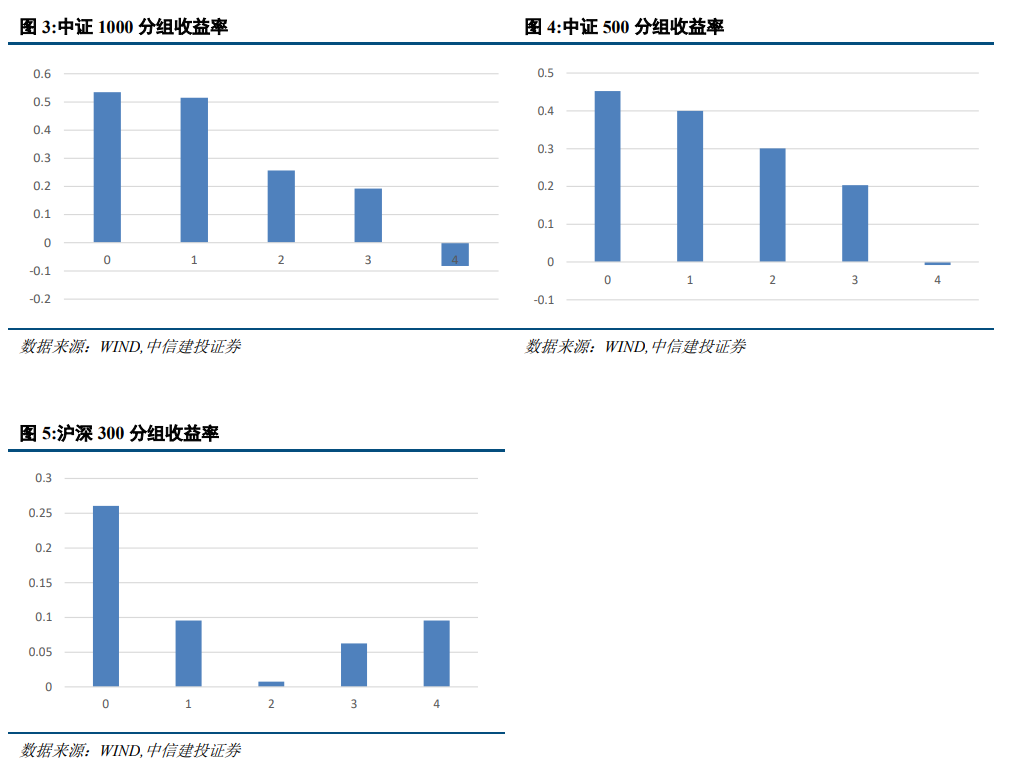
将训练好的模型应用于不同的指数成分股中进行预测,策略的表现会出现明显的分化,在中证500和中证1000中,模型表现较好,而在沪深300中,模型表现一般。
风险分析
openFE挖掘出的基本面因子是基于历史统计结果的展示,未来有可能发生风格切换导致因子失效的风险。模型运行存在一定的随机性,初始化随机数种子会对结果产生影响,单次运行结果可能会有一定偏差。历史数据的区间选择会对结果产生一定的影响。模型参数的不同会影响最终结果。模型对计算资源要求较高,运算量不足会导致结果存在一定的欠拟合风险。本文所有模型结果均来自历史数据,模型存在统计误差,不保证模型未来的有效性,对投资不构成任何建议。
证券研究报告名称:《“逐鹿”Alpha 专题报告(十三)——基于openFE的基本面因子挖掘框架》
对外发布时间:2023年2月17日
报告发布机构:中信建投证券股份有限公司
本报告分析师:丁鲁明 执业证书编号:S1440515020001
王超 执业证书编号:S1440522120002
免责声明:
本公众订阅号(微信号:中信建投金融工程研究)为丁鲁明金融工程研究团队(现供职于中信建投证券研究发展部)设立的,关于金融工程研究的唯一订阅号;团队负责人丁鲁明具备分析师证券投资咨询(分析师)执业资格,资格证书编号为:S1440515020001。
本公众订阅号所载内容仅面向专业机构投资者,任何不符合前述条件的订阅者,敬请订阅前自行评估接收订阅内容的适当性。订阅本公众订阅号不构成任何合同或承诺的基础,本公司不因任何订阅或接收本公众订阅号内容的行为而将订阅人视为本公司的客户。
本公众订阅号不是中信建投证券研究报告的发布平台,所载内容均来自于中信建投证券研究发展部已正式发布的研究报告或对报告进行的跟踪与解读,订阅者若使用所载资料,有可能会因缺乏对完整报告的了解而对其中关键假设、评级、目标价等内容产生误解。提请订阅者参阅本公司已发布的完整证券研究报告,仔细阅读其所附各项声明、信息披露事项及风险提示,关注相关的分析、预测能够成立的关键假设条件,关注投资评级和证券目标价格的预测时间周期,并准确理解投资评级的含义。
本公司对本帐号所载资料的准确性、可靠性、时效性及完整性不作任何明示或暗示的保证。本帐号资料、意见等仅代表来源证券研究报告发布当日的判断,相关研究观点可依据本公司后续发布的证券研究报告在不发布通知的情形下作出更改。本公司的销售人员、交易人员以及其他专业人士可能会依据不同假设和标准、采用不同的分析方法而口头或书面发表与本帐号资料意见不一致的市场评论和/或观点。
本帐号内容并非投资决策服务,在任何情形下都不构成对接收本帐号内容受众的任何投资建议。订阅者应当充分了解各类投资风险,根据自身情况自主做出投资决策并自行承担投资风险。订阅者根据本帐号内容做出的任何决策与本公司或相关作者无关。
本帐号内容仅为本公司所有。未经本公司许可,任何机构和/或个人不得以任何形式转发、翻版、复制和发布相关内容,且不得对其进行任何有悖原意的引用、删节和修改。除本公司书面许可外,一切转载行为均属侵权。版权所有,违者必究。
中信建投金融工程深度专题报告回顾
(点击标题可查看历史文章)
【资产配置】
【因子选股】
【交易策略与衍生品】
深度专题7:2015年衍生品市场政策总结及交易策略 |
【基金产品研究与FOF】
深度专题14:非传统型基金产品概述:躲不过的中国资本市场宏观对冲时代match 深度专题68:工具化、配置化、异质化之路——公募基金市场综述与展望 深度专题71:科创板发行制度解析及上市表现猜想——来自海内外的经验 深度专题77:因子投资热潮渐起,聪明指数未来可期——Smart Beta市场综述 |
本篇文章来源于微信公众号: 鲁明量化全视角