"海量"专题(231)——多颗粒度特征的深度学习模型:探索和对比
重要提示:《证券期货投资者适当性管理办法》于2017年7月1日起正式实施,通过本微信订阅号发布的观点和信息仅供海通证券的专业投资者参考,完整的投资观点应以海通证券研究所发布的完整报告为准。若您并非海通证券客户中的专业投资者,为控制投资风险,请取消订阅、接收或使用本订阅号中的任何信息。本订阅号难以设置访问权限,若给您造成不便,敬请谅解。我司不会因为关注、收到或阅读本订阅号推送内容而视相关人员为客户;市场有风险,投资需谨慎。
为了探索这一问题,本文首先展示了单颗粒度模型的效果。在此基础上,尝试搭建两类融合不同频率特征信息的多颗粒度模型。并针对潜在的信息遗忘问题,对模型做了积极的改进。此外,微软亚研院(MSRA)2021年提出的多颗粒度残差学习网络,也在本文中得到了初步的复现。最后,利用多颗粒度模型的收益预测,本文实现了近似“端到端”的指数增强组合构建。
01
单颗粒度模型
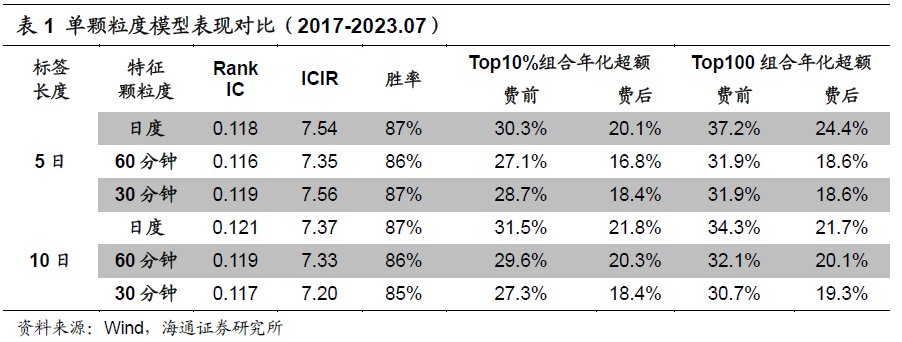
由上表可见,2017-2023.07,基于日度特征训练得到因子有更高的多头超额收益(相对全市场所有股票平均,下文如未明确说明,皆是如此)。那么,这是否意味着高频特征并无增量信息呢?我们进一步对比单颗粒度模型的分年度多头超额收益(表2)。
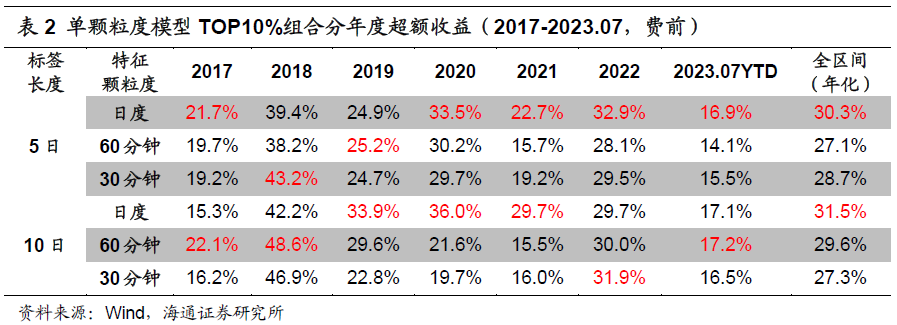
使用日度特征训练得到的因子,并非每一年都表现最优。部分年度中,以60分钟或30分钟特征作为输入的模型,取得了更高的超额收益。例如,当预测标签为未来10日收益时,用60分钟特征训练得到的因子在2017、2018和2023年的表现都更胜一筹;而2022年,则是输入30分钟特征能获得更高的超额收益。
因此,我们认为,尽管使用单一的日度特征已经可以实现不俗的业绩,但更细颗粒度的特征依然有值得挖掘的有效信息。进一步开发包含不同频率特征的多颗粒度模型,有望提升因子的收益,增强业绩的稳定性。
02
多颗粒度模型
本文尝试使用如下两种最为常见的多颗粒度模型,融合不同频率特征中的信息。
(1)“多颗粒度输入,一次性训练”(后文简称“混合输入”):将不同颗粒度的特征均作为模型输入,并通过独立的GRU提取序列信息;随后,将GRU的输出结果合并,再通过MLP得到最终的输出。
(2)“单颗粒度训练,输出集成”:单独训练每一个颗粒度的特征,输出对标签的预测;在最终的推理阶段,集成不同颗粒度模型的输出。本文共测试了两种方案,一是集成日度、60分钟和30分钟三个模型的输出(后文简称“输出集成”),二是只集成最粗和最细两个颗粒度模型的输出,即日度和30分钟频(后文简称“输出集成1”)。集成也有多种方式,如简单平均,机器学习中的树模型、基于互信息的对比学习等。为方便计,本文使用简单平均。

下表展示了不同标签长度、调仓周期和成交价格假设下,各单/多颗粒度模型的Rank IC。虽然基于日度特征的单颗粒度模型已展现出较强的周度与双周度选股能力,但通过加入细颗粒度特征,Rank IC得到了普遍的提升。
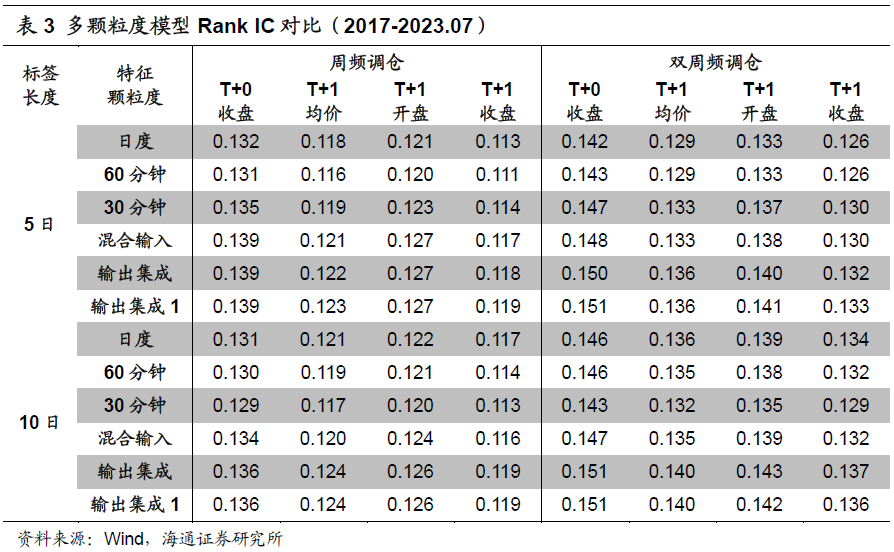
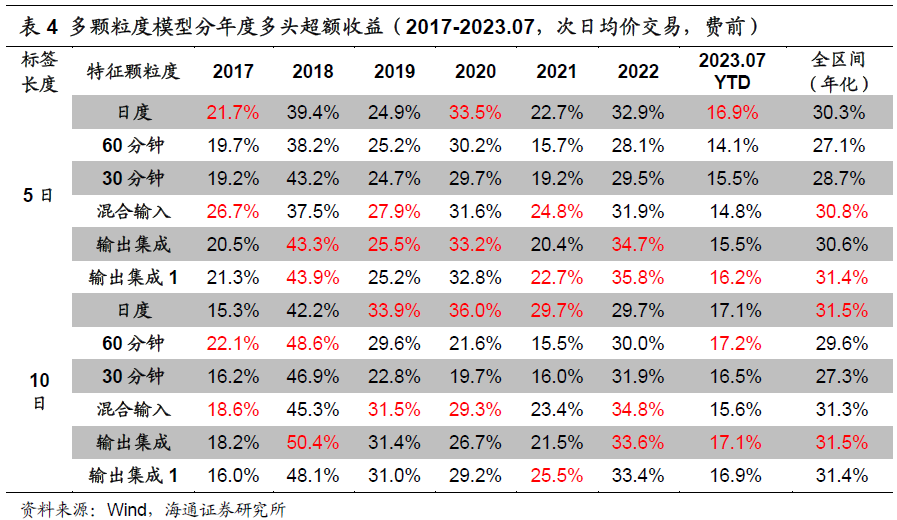
进一步对比不同模型Top10%组合的分年度超额收益,如下表所示,在所有年份上,总有多颗粒度模型能排在前两位。整体而言,输出集成方式的效果最好,10日标签对应的年化超额收益可达31.5%。
03
双向AGRU多颗粒度模型
尽管混合输入或输出集成提升了单颗粒度模型的选股能力,但由于依然使用传统GRU,当特征的颗粒度较细(如60分钟或30分钟)时,“失忆”问题就不可避免。因此,想要进一步提升因子有效性,增强循环神经网络(RNN)的记忆性很有必要。
Transformer类的网络结构是很多学术文献的首选,但通常需要较大的参数量才能获得理想的结果。而在周度或双周度收益预测的情景之下,用于训练的样本较为有限,因此该类模型未必适用。但我们可以借鉴Transformer类网络中的核心思想——注意力机制,即,对历史上各期隐含状态进行注意力加权,来改进传统GRU。
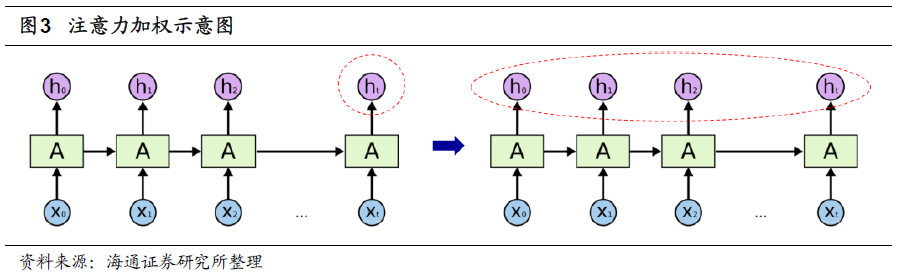
除了引入注意力机制外,我们还将GRU模型从单向改为双向。即,分别按顺序和逆序学习特征序列,并提取信息,进一步缓解早期重要信息的遗忘问题。最终的模型简记为双向AGRU。
下图展示了双向AGRU单颗粒模型的年化多头超额收益。显然,几乎在所有参数下,超额收益都得到了较为显著的提升。
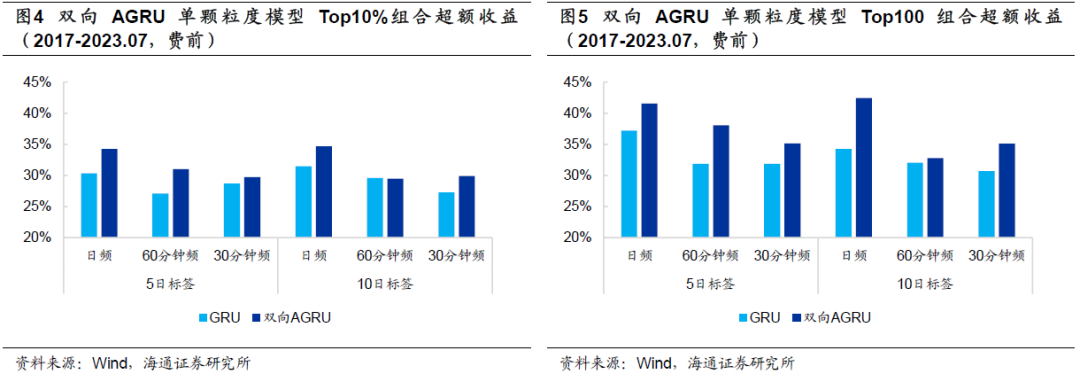
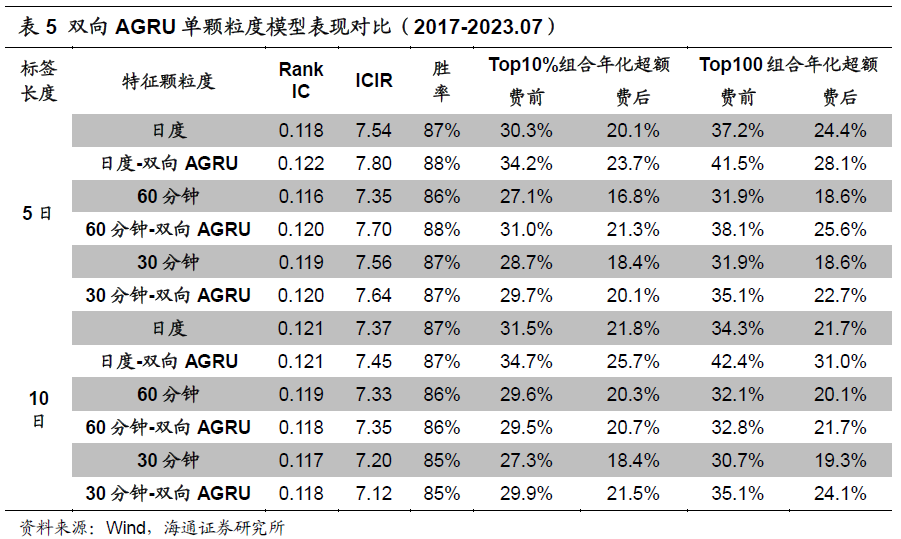
进一步由下表可见,改为双向AGRU后,绝大部分单颗粒度模型的周度Rank IC、ICIR、超额收益都获得明显的改善,费后超额收益的平均提升幅度约为4%-5%。
以下图表为双向AGRU多颗粒度模型的收益表现。和传统的单向GRU相比,新模型的Rank IC、ICIR和多头超额收益都得到了全面而稳定的提升。
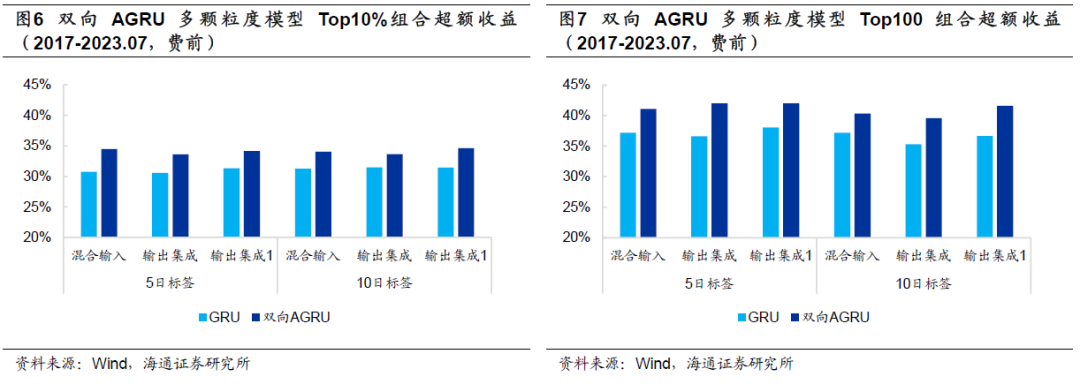
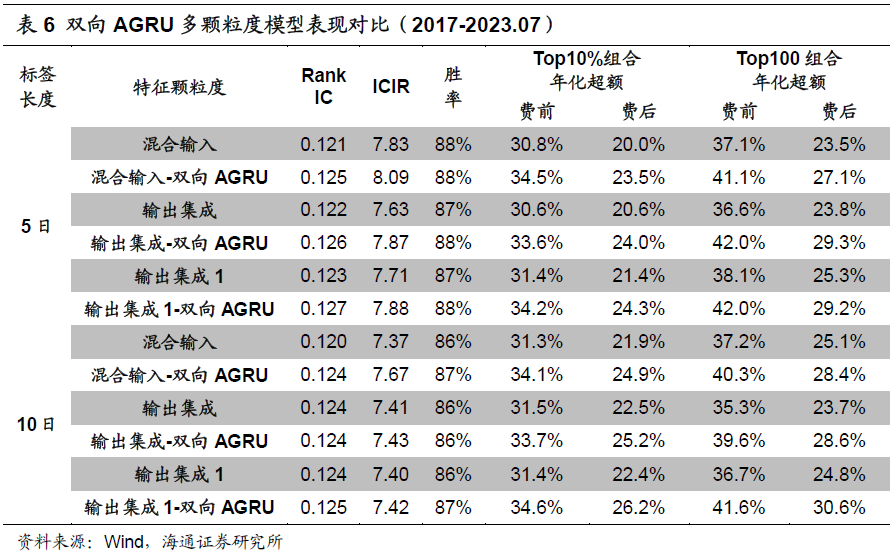
具体地,双向AGRU混合输入和输出集成模型的周均IC都超过0.12,Top10%和Top100组合的费前多头超额收益分别为33%和40%。考虑双边0.3%的交易成本后,两个组合的多头超额收益依然可以达到24%和30%。
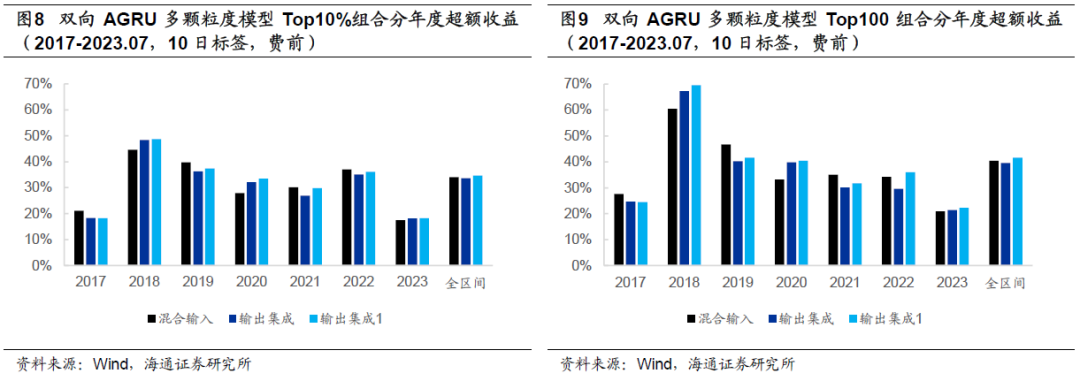
以下两图展示的是双向AGRU多颗粒度模型的分年度费前多头超额收益,从中可见,2019-2022年,超额收益分布较为均匀,未出现明显的衰减态势。2023年,各模型Top10%和Top100组合的YTD超额收益约为18%和21%。
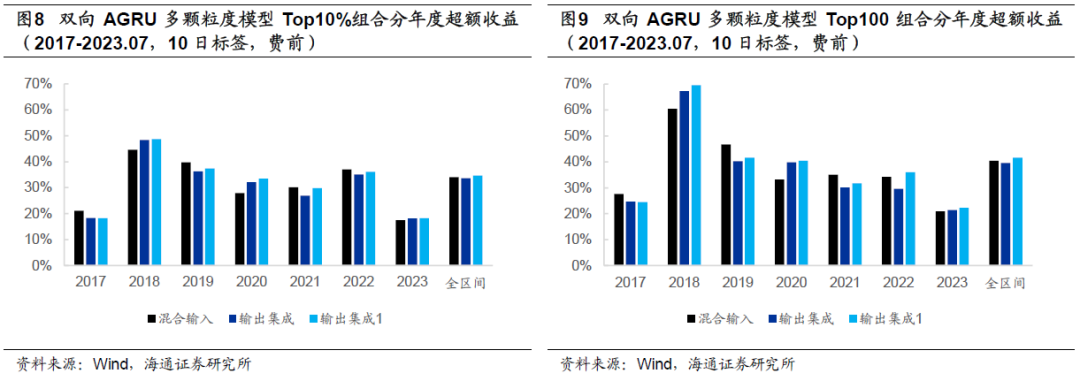
下图为Top10%组合2023年1至7月的费前累计超额收益,两次较大幅度的回撤分别发生在3月上旬至4月上旬和5月中旬至6月中旬。6月中旬至7月底,超额收益累积迅速,且较为平稳。
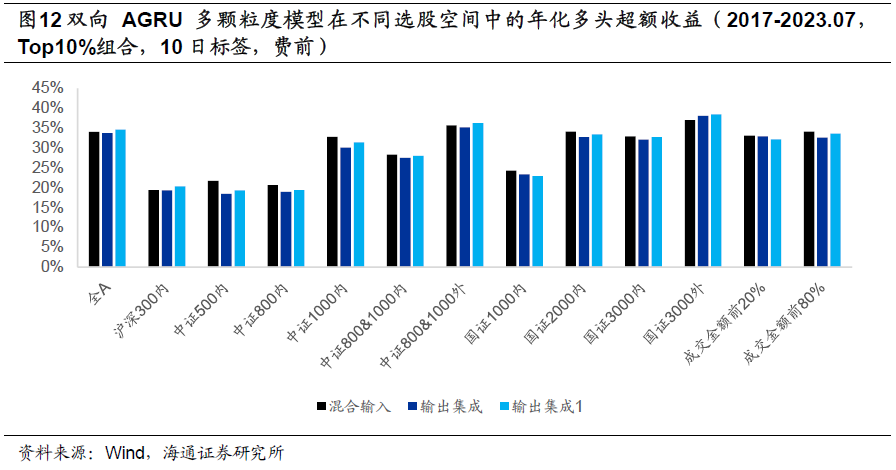
以上测试结果均以全市场为选股范围,但实际投资常常面临各种约束。因此,考察模型在不同选股空间中的表现,有着很强的现实意义。以下两图分别展示了因子的Rank IC和多头超额收益。从中可见,模型在中证800成分股内表现较为一般,周均Rank IC仅为0.08-0.09,多头超额收益约20%,都显著低于全市场的结果。
模型表现较好的选股域包括中证1000内、中证1800外、国证2000内和国证3000外,Rank IC都高于0.12,费前多头超额收益均超过30%。若进一步考虑成交活跃度,将选股范围限定在成交金额排名前20%的股票内,Rank IC和多头超额收益依然可以达到12%和30%。
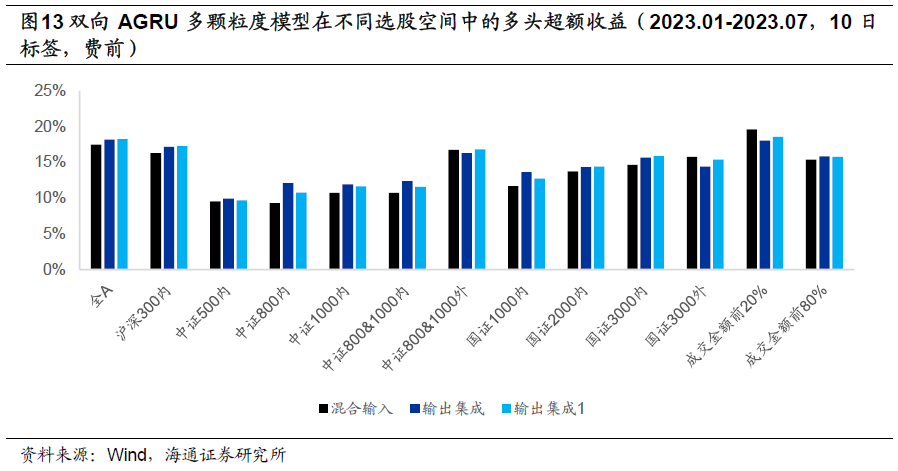
如下图所示,截至2023年7月,模型在中证500、中证1000和国证2000成分股内的YTD超额收益分别为6%-7%、8%-9%和11%-12%,均显著低于历史平均水平。有趣的是,模型反而在沪深300成分股内获得了14%-16%的YTD超额收益,远高于历史平均水平。我们认为,这种选股有效性的此消彼长,或许反映了策略在不同选股域中的拥挤情况。
04
多颗粒度残差学习网络
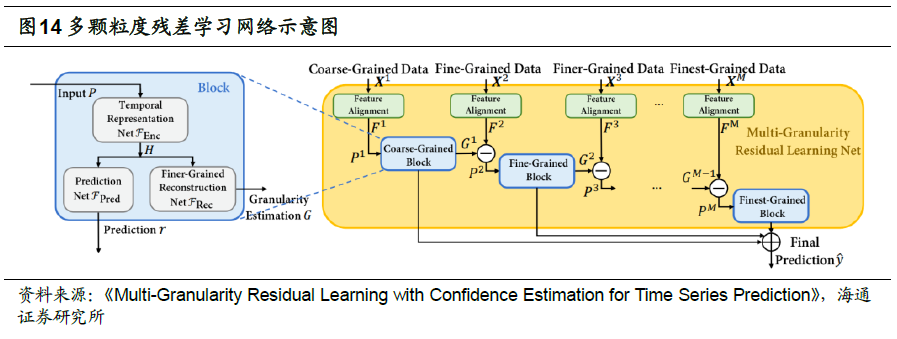
除了混合输入和输出集成外,融合多颗粒度特征的新模型也不断涌现。例如,微软亚研院在《Multi-Granularity Residual Learning with Confidence Estimation for Time Series Prediction》一文中,提出了多颗粒度残差学习网络。其核心理念是,不同颗粒度特征存在较为严重的信息冗余,因此,如何提取每个颗粒度的特有信息,而剔除重复部分,对最终的模型构建非常重要。此外,不同颗粒度特征的有效性往往会随时间变化,还需要判定每个颗粒度特征是否对最终预测有足够的影响。
具体地,将多个相同的模块叠加,形成整体网络架构,但每个模块只单独处理一个颗粒度的数据。从第二个模块起,输入的特征都需通过取残差的方式,剔除前一颗粒度已包含的信息,即,只保留该颗粒度特有的信息。考虑到不同颗粒度特征的维数有差异,因此需要通过简单的线性变换实现维数对齐,便于计算残差。每个模块都会输出该颗粒度下,对最终标签的预测。再将所有预测集成,作为最终的预测。
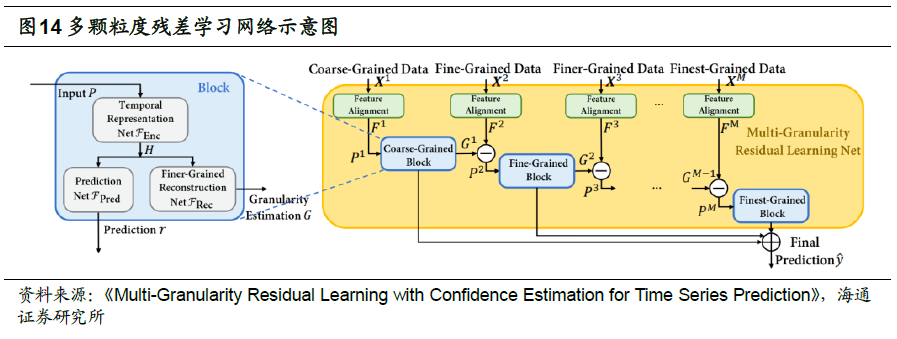
每个模块又由3个不同的部分构成,
1) 时序信息编码网络:双层GRU,用于提取时间序列输入的信息。
2) 预测网络:产生当前颗粒度特征的预测,用于和其他颗粒度预测的最终集成。
3) 细粒度重构网络:提取并重构当前颗粒度的信息,用于和下一颗粒度的特征计算残差。
在集成各颗粒度的预测时,文献也对比了多种解决方案。例如,简单平均,注意力加权、使用对比学习加权。感兴趣的读者可参阅原文,了解更多细节。
在设计损失函数时,除了MSE以外,文献进一步加入了重构损失项和L2正则项。其中,重构损失项为每一颗粒度的输入与上一颗粒度重构输出的Forbenius Norm。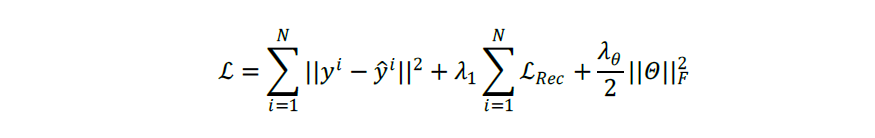
本文尝试复现上述残差学习网络,训练周度选股因子,并与前文的多颗粒度模型进行对比。由于该网络的结构和损失函数都较为复杂,模型训练的开销巨大。因此,我们仅测试日度及30分钟两种颗粒度,结果如下表所示。
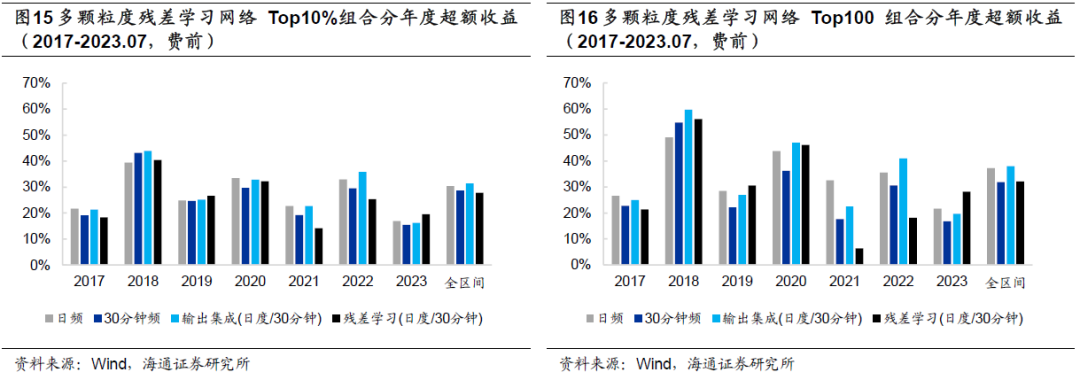
多颗粒度残差学习网络并未展现出显著的优势,相反,Rank IC、ICIR、多头组合超额收益均弱于输出集成模型。由以下两图的分年度超额收益可见,多颗粒度残差学习网络仅在2019和2023年表现较优,其余年份上均有所不及,尤其是2021和2022年。但考虑到该网络对应的损失函数中,存在两个可调整的超参数,本文未能达到文献所展示的那般优异的效果,或许和超参数的选择有关。在后续的研究中,我们还会对该网络进行更加详细的研究和测试。
05
AI指数增强组合
为了进一步考察双向AGRU多颗粒度模型的效果,我们将其输出值作为股票的收益预测,构建周度调仓的中证500和中证1000 AI增强组合。其中,增强组合的风险控制模块包括以下几个方面的约束。
1) 个股偏离:相对基准的权重偏离不超过0.5%/1%;
2) 因子暴露:估值中性、市值(500增强:中性;1000增强:[-0.2, 0.2]),常规低频因子:[-0.8, 0.8];
3) 行业偏离:严格中性/偏离上限2%;
4) 选股空间:全市场/80%指数成分股权重;
5) 换手率限制:单次单边换手不超过30%。
两个组合的优化目标均为最大化预期收益,目标函数如下所示。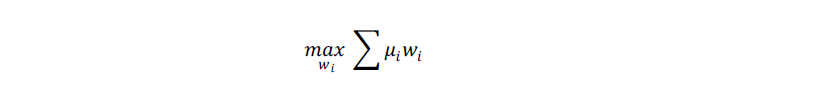
其中,w_i为组合中股票i的权重,μi为股票i的预期超额收益。为使测试结果贴近实践,下文的测算均假定以次日均价成交,同时扣除双边3‰的交易成本。
如下表所示,2017.01-2023.07,随风控参数的变化,基于双向AGRU多颗粒模型的中证500 AI增强组合(无成分股约束),年化超额收益为15%-20%。其中,2023年的YTD超额收益为10%-16%。相较而言,使用未来10日超额收益作为训练标签的模型,整体超额收益更高。我们认为,这可能是因为标签越短,模型表现越依赖于交易能力。在次日均价成交的设定下,短标签模型反而处于劣势。
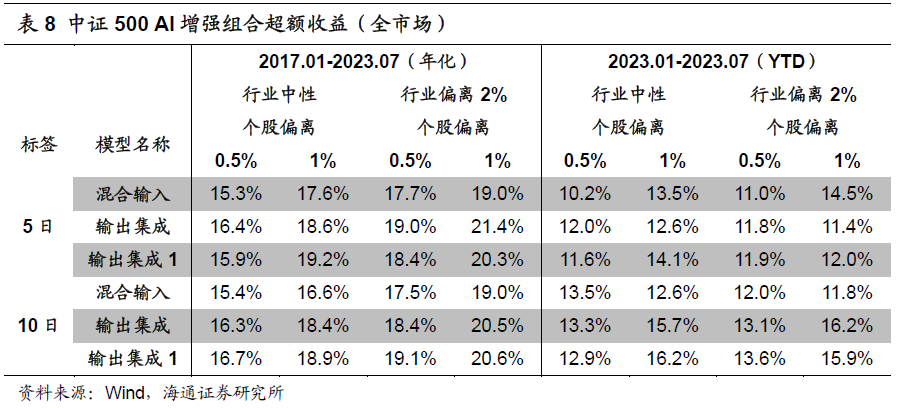
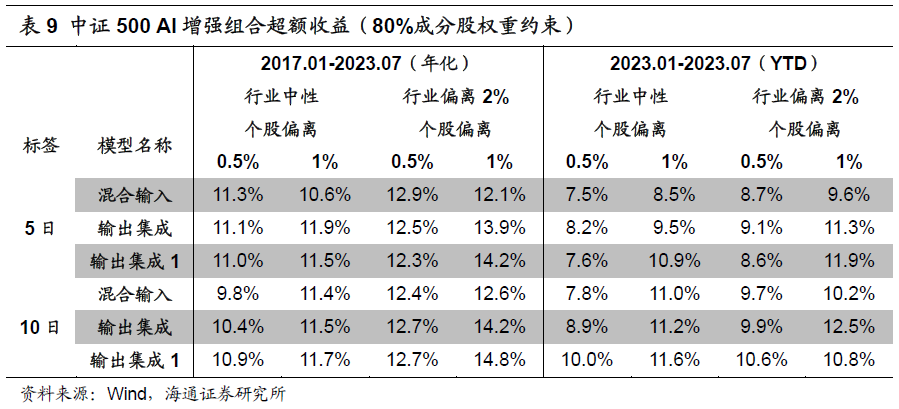
添加80%成分股权重约束后,各组合年化超额收益从15%-20%下降至10%-15%。其中,2023年的YTD超额收益从10%-16%下降至7%-12%。由此可见,成分股约束对中证500增强组合的超额收益有着较为显著的影响。类似地,10日标签模型的超额收益相对更高。
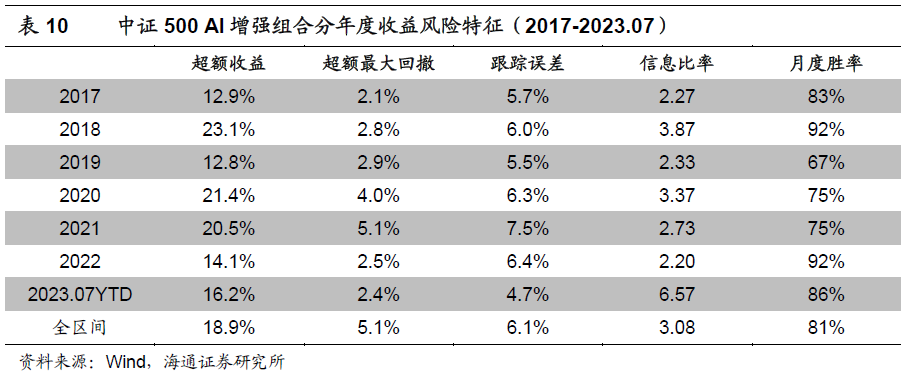
下表为“全市场选股、行业中性、个股偏离1%、输出集成”这组特定参数的中证500 AI增强组合的分年度收益风险特征。2017年以来,组合年化超额收益18.9%,超额最大回5.1%,发生在2021年。其中,2019和2022年表现相对较弱,2023年YTD超额收益16.2%。
如下表所示,2017.01-2023.07,随风控参数的变化,基于双向AGRU多颗粒模型的中证1000 AI增强组合(无成分股约束),年化超额收益为25%-30%。其中,2023年的YTD超额收益为15%-18%。相较而言,放松个股或行业偏离,以及使用未来10日超额收益作为训练标签,可以获得更好的业绩表现。
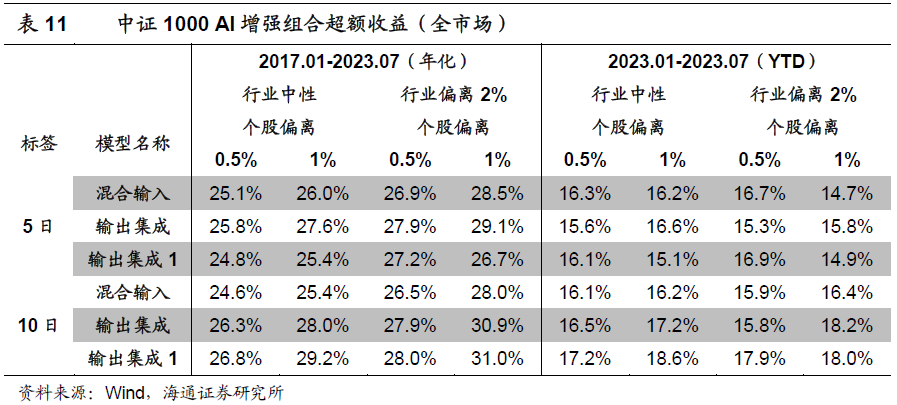
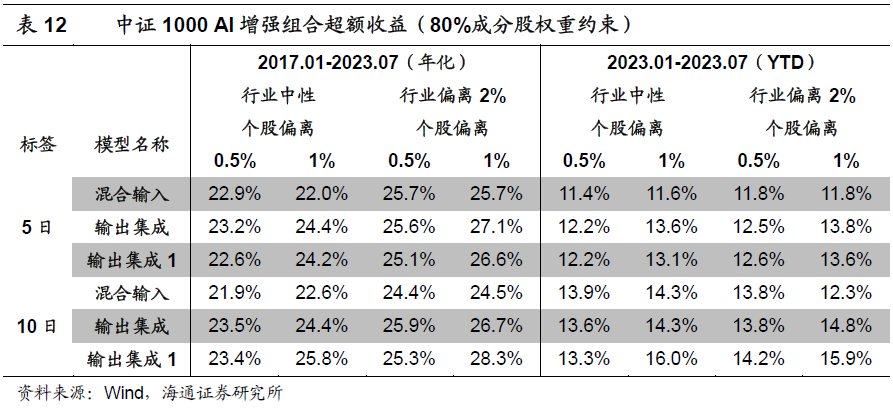
添加80%成分股权重约束后,各风控参数下,组合的年化超额收益为22%-28%。其中,2023年的YTD超额收益为11%-16%。和无成分股约束的结果相比,下降2%-3%,幅度明显小于中证500 AI增强组合。我们猜测,可能的原因是,近年来,深度学习模型在中证500成分股内的选股效果逐步下滑,且显著弱于全市场;而在中证1000成分股内,则依然可以维持和全市场接近的表现。
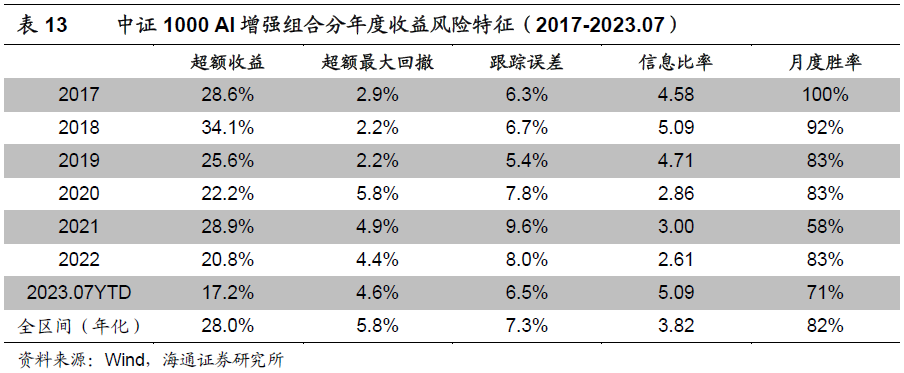
下表为“80%成分股权重约束、行业中性、个股偏离1%、输出集成”这组特定参数的中证1000 AI增强组合的分年度收益风险特征。2017年以来,组合年化超额收益28.0%,超额最大回撤5.8%,发生在2020年。其中,2023年YTD超额收益17.2%。
06
总结
尽管使用单一的日度特征已经可以实现不俗的业绩,但更细颗粒度的特征依然有值得挖掘的有效信息。因此,本文引入了两类多颗粒度模型。(1)“多颗粒度输入,一次性训练”:将不同颗粒度的特征均作为模型输入,并通过独立的GRU提取序列信息;随后,将GRU的输出结果合并,再通过MLP得到最终的输出。(2)“单颗粒度训练,输出集成”:单独训练每一个颗粒度的特征,输出对标签的预测;在最终的推理阶段,集成不同颗粒度模型的输出。
在不同标签长度、调仓周期和成交价格假设下,多颗粒度模型的Rank IC和年化多头超额收益,相比单颗粒度模型都得到了不同程度的提升。整体而言,输出集成方式的效果最好,10日标签对应的费前年化超额收益可达31.5%。
为缓解早期重要信息的遗忘问题,我们不仅引入了注意力机制,还将GRU模型从单向改为双向。即,分别按顺序和逆序学习特征序列,并提取信息。和传统的单向GRU相比,双向AGRU多颗粒度模型的Rank IC、ICIR和多头超额收益都得到了全面而稳定的提升。具体地,周均Rank IC超过0.12,Top10%和Top100组合的费前多头超额收益分别为33%和40%。
微软亚研院在《Multi-Granularity Residual Learning with Confidence Estimation for Time Series Prediction》一文中,提出了多颗粒度残差学习网络。其核心理念是,将多个相同的模块叠加,形成整体网络架构,但每个模块只单独处理一个颗粒度的数据。从第二个模块起,输入的特征都需通过取残差的方式,剔除前一颗粒度已包含的信息,即,只保留该粒度特有的信息。每个模块都会输出该颗粒度下,对最终标签的预测。再将所有预测集成,作为最终的预测。
将双向AGRU多颗粒度模型的输出值作为股票的收益预测,构建周度调仓的中证500和中证1000 AI增强组合。2017.01-2023.07,无成分股约束时,中证500和中证1000 AI增强组合分别取得15%-20%和25%-30%的年化超额收益。其中,2023年的YTD超额收益分别为10%-16%和15%-18%。添加80%成分股权重约束后,两个组合的超额收益分别下降5%-6%和2%-3%,至10%-15%和23%-27%。
07
风险提示
市场系统性风险、资产流动性风险、政策变动风险、因子失效风险。

联系人


本篇文章来源于微信公众号: 海通量化团队