了解GPT:应用篇——德邦金工文献精译第十二期【德邦金工|文献精译】

摘要
投资要点
2023年5月23日,微软举办了Build 2023开发者大会。在该大会上,OpenAI创始人Andrej Karpthy发表了题为“State of GPT”的专题演讲,向与会者介绍了GPT模型的最新动态。本文介绍了演讲的第二部分内容——大模型的应用。
应用GPT需要了解GPT的认知差异、使用“提示”引导GPT、提醒GPT回顾检查。此外演讲介绍了提高模型表现的方法,例如检索增强模型、约束提示技术和模型微调。很多方法都可以帮助GPT更好地理解问题,并生成更准确合理的回答。使用GPT模型时需注意确保在提示中详细阐述任务内容,添加相关上下文信息,并使用提示工程技术来改善模型性能。对于数据量较小的情况,试用少样本示例提示;对于大模型难以完成的任务,利用各种工具和插件。处理提示和答案时,关注它们的相关性和连贯性,尝试生成多个样本,最大化提示效果后进行参数微调。最后,优先考虑使用强化学习和人类反馈(RLHF)以获得更好的效果。
OpenAI于2022年11月发布ChatGPT、2023年3月发布GPT-4后,全球多个研究机构都在积极推动大型语言模型的研究,以追赶和超越OpenAI的前沿科研成果。近期,Claude2、Llama2、ChatGLM2等第二代大型语言模型相继亮相,谷歌的Bard实现升级,新的开源大型语言模型也纷纷发布。这一系列的发展趋势清晰地指示出大型语言模型的竞争日趋激烈,同时也体现出大型语言模型的研究正在向着更规模化和成熟化的方向发展。
大型语言模型的研究进步已推动了许多实用工具的发展,目前应用于办公、代码撰写、金融分析的生产力工具的也愈发成熟。例如,GitHub Copilot用于提高代码撰写效率,Bloomberg GPT提高用于金融分析效率。New Bing、Microsoft 365 Copilot和WPS AI也提升了搜索和办公工具效率。此外,ChatGPT Plugins和Code Interpreter插件更大程度上开发了OpenAI模型的应用潜力。
风险提示
数据不完备和滥用风险,信息安全风险,算法伦理风险
目 录
1. 微软开发者大会专题演讲:State of GPT
2. 应用GPT的注意事项
2.1. 使用“提示”引导GPT作出更好的回答
2.2. 提醒GPT回顾和检查
2.3. 提高模型表现的方法
2.4. 检索增强模型和约束提示技术
2.5. 模型微调
2.6. 有效应用GPT助手的建议
3. 近期发布的大语言模型
3.1. Llama2大语言模型
3.2. ChatGLM2大语言模型
3.3. Baichuan-13B
3.4. 谷歌Bard
3.5. Claude2
4. 大模型的应用
4.1. GitHub Copilot
4.2. New Bing
4.3. Microsoft 365 Copilot
4.4. WPS AI
4.5. Bloomberg GPT
4.6. ChatGPT Plugins
4.7. Code Interpreter
5. 参考文献
6. 风险提示
信息披露
正 文
1. 微软开发者大会专题演讲:State of GPT
2023年5月23日,微软举办了Build 2023开发者大会。在该大会上,OpenAI[文]创始人Andrej Karpthy发表了题为“State of GPT”的专题演讲,向与会者介绍了GPT模型[章]的最新动态。

这次演讲可以被划分为两个主要的部分:
• 第一部分,讨论如何训练一个 GPT 助手;
• 第二部分,讨论如何有效地应用 GPT 助手。
本文将主要专注于第二部分的内容——即如何有效地应用 GPT 助手。除了演讲内容本身,我们还将关注最近发布的大模型和大型模型日益成熟的应用。
2. 应用GPT的注意事项
人脑和GPT架构存在认知差异。例如,当写一篇关于“加州的人口是阿拉斯加的53倍”的博客或文章时,人脑通常会经历丰富的内心独白,并结合相关资料和工具进行反复验证和纠错,如图3。然而,在训练GPT时,这些内容作为训练数据只是标记序列——所有内心独白、思考和推理过程都被剥离出去。GPT会对每个标记花费大致相同的计算能力来读取这些标记序列,而人脑则会根据任务难易花费不确定长短的时间。本质上讲,GPT只是一个标记模拟器。
GPT的优势和缺陷,以及弥补认知差异可以采取的措施如表1:


2.1. 使用“提示”引导GPT作出更好的回答
大型语言模型进行推理时需要使用标记来指导其行为。为了使模型更好地理解问题,可以将任务分解为多个步骤或阶段,并模拟人类思维的内在独白。因此,需要使用更准确的表达来描述问题——使用恰当的提示(Prompts):
1) 少样本提示(Few-shot):在进行提问提供几个示例模板,让Transformer可以仿照这些模板进行回答,从而产生更好的结果。
2) 零样本提示(Zero-shot):在提问时使用“让我们逐步思考 (let's think step by step)”等提示词,引导Transformer采用逐步思考的方式进行推理。这将使得Transformer降低其推理速度,并展示其工作的过程。
2.2. 提醒GPT回顾和检查
当GPT进行预测时,可能会采样到不太好的标记,这时他们的推理就会陷入困境且难从错误中恢复过来。因此需要确保模型具备回顾、检查和尝试的能力。实际上,当大型语言模型获取到不佳样本并产生较差的结果时,其自身似乎能有所察觉。例如,如果要求模型生成一首不押韵的诗,它可能会生成一首实际上是押韵的诗,但当询问它是否完成了任务时,它会意识到自己没有完成,并重新生成一首诗。然而,如果不提醒它进行检查,它就不会自动进行检查。因此,需要推动模型进行检查。

从更广泛的角度来看,以上过程可以类比于人类思[来]考的两个模式:系统一和系统二。系统一是自动且[自]快速地产生结果的模式,对应于大型语言模型;而[1]系统二是大脑中经过深思熟虑、缓慢思考和计划的[7]部分,对应于“自我一致性”。目前,许多研究人[量]员正在研究一些提示工程,旨在使大型语言模型具[化]备一些类似于人类大脑的能力。
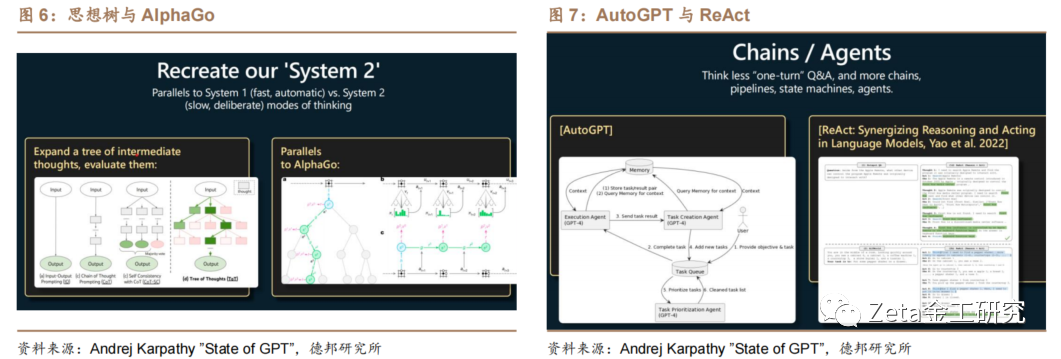
图6是Recreate方法,模型被允许使用工具,将提示的答案构建为一系列思考、行动和观察的序列,代表了一个完整的推理过程。
图7是AutoGPT方法,允许大语言模型保留[ ]任务列表并递归地分解任务。AutoGPT是系[ ]统思考的方法,但目前效果还不够理想。
2.3. 提高模型表现的方法
GPT只接受了语言建模方面的训练。GPT有时[ ]会产生一种不愿取得更好表现的特性,因为它们只[1]是在对训练集进行模仿。为了获得更好的效果,需[7]要给GPT明确的指导,例如,在物理问题或类似[q]问题的提示中,GPT无法区分一个学生完全错误[u]的答案和一个正确的专家级答案的区别。为此,可[a]以采取以下方法来提高模型的表现: [n]
1) 提示“确保正确答案存在”:在之前提到的“让我们逐步思考”提示的基础上,更好的提示方式是“让我们逐步思考并确保我们找到正确答案”。这样可以使GPT不必浪费时间在低质量的解决方案上。图8是来自论文的例子,该例子尝试了多种提示,最终发现“让我们逐步思考并确保我们找到正确答案”的作用非常明显,可以达到较高的准确率。
2) 设定合理的背景信息:例如,可以假设GPT是某个领域的专家,或者假设GPT的智商水平为120等等。
3) 明确知识边界和工具使用:当解决问题时,我们通常知道自己在哪些方面擅长或不擅长,并借助相应的工具来帮助。对于大型语言模型,可以告诉模型它在哪些方面擅长或不擅长,并指定需要使用的工具,如计算器、代码解释器等,如图9。例如,可以告诉GPT:“你的心算能力不太好。每当您需要进行大数加法、乘法或其他操作时,请使用此计算器。以下是计算器的使用方法……”。

2.4. 检索增强模型和约束提示技术
检索增强型大型语言模型(Retrieval-[t]Augmented LLMs)能有效地融合传统检索方法(如Goo[.]gle)和大型语言模型的优势。关键是利用Tr[c]ansformer的上下文窗口作为工作内存,[o]加载相关信息,从而优化性能。可以将相关文档分[m]块、转化为嵌入向量并存储。在运行时,查询向量[文]存储获取相关文档块,将其作为提示填充到模型中[章]以生成内容。这就像人类忘记知识点时翻书获取信[来]息。
约束提示技术(Constrained prompting)是一种可以控制大型语言模[自]型输出格式的技术。其基本原理是固定某些特定的[1]标记,并通过调整模型对这些标记的概率分布,限[7]制其输出形式。在实践中,这意味着模型需要在这[量]些预设的标记间填充适当的内容。如图11所示,[化]这项技术可以用来强制模型输出特定格式(如JS[ ]ON)的内容。

2.5. 模型微调
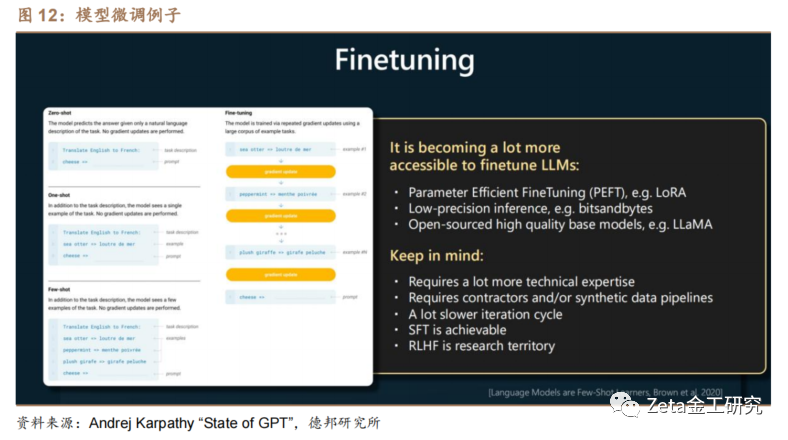
微调模型是一种优化模型性能的方法,它通过调整大型语言模型的参数使其更适合特定任务,从而节约计算资源和成本。新兴技术如LoRA(Low-Rank Adaptation of Large Language Models 大语言模型的低阶适应,属于一种 PEFT ,Parameter-Efficient Fine-Tuning 参数高效性微调)已经让这个过程变得相对容易,该技术可以在保持基础模型的情况下,高效地微调部分参数,以降低微调成本和加速推理过程。然而,微调模型需要专业技术知识和可用数据集,可能会使模型的迭代速度降低。相比之下,基于监督微调(Supervised Fine-Tuning,SFT)的方法容易实现,而基于人类反馈的强化学习(RLHF)方法相对更复杂。
2.6. 有效应用GPT助手的建议
对于如何有效应用GPT助手,演讲者给出的建议[ ]是:

要降低成本,可以使用容量较低的模型,或者使用[ ]更短的提示,这将减少计算资源的使用,并缩短生[1]成答案所需的时间。
对于大型语言模型的局限性,需要注意如模型偏见[7]、虚构事实、推理错误、知识滞后,以及存在潜在[q]的注入攻击、越界攻击和数据中毒的风险。因此,[u]演讲者建议将大型语言模型应用于低风险的场景,[a]并始终在人工监督下使用,将其作为提供灵感和建[n]议的工具,而不是完全自主的代理。
3. 近期发布的大语言模型
在OpenAI于2022年11月发布Chat[t]GPT和2023年3月发布GPT-4之后,全[.]球多个研究机构都在积极推动大型语言模型的研究[c],以追赶和超越OpenAI的前沿科研成果。近[o]期,Claude2、Llama2、ChatG[m]LM2等第二代大型语言模型相继亮相,谷歌的B[文]ard实现升级,新的开源大型语言模型也纷纷发[章]布。这一系列的发展趋势清晰地指示出大型语言模[来]型的竞争日趋激烈,同时也体现出大型语言模型的[自]研究正在向着更规模化和成熟化的方向发展。
3.1. Llama2大语言模型
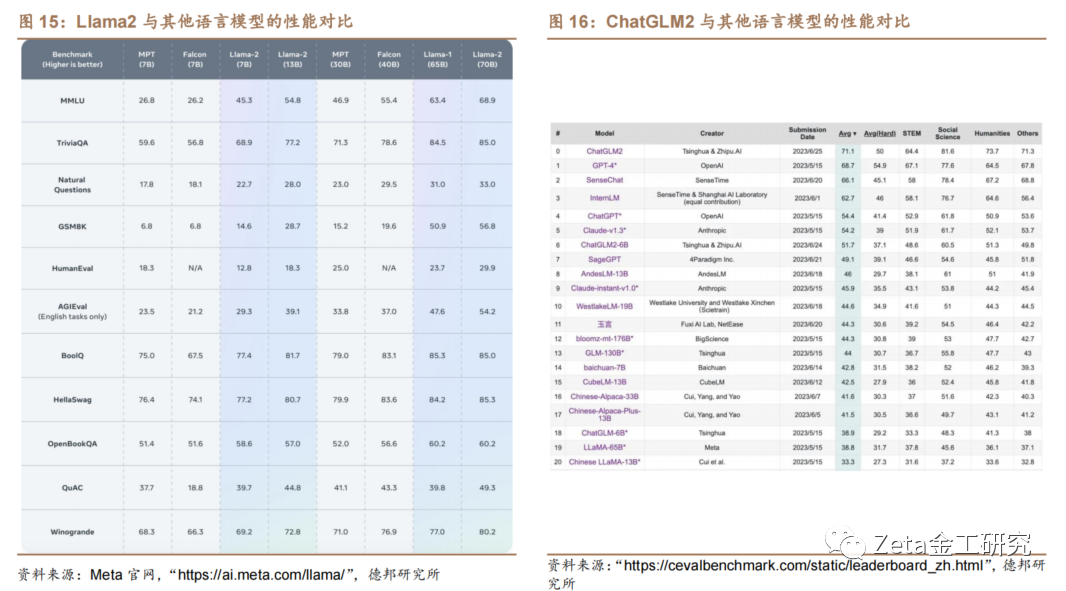
2023年7月19日Meta发布了大型语言模[1]型Llama 2,Meta宣布此款大模型可免费商用。Lla[7]ma 2提供了70亿、130亿、700亿参数版本供[量]选择,Llama 2相较于其前身Llama 以及其他开源模型有显著的提升。Llama 2对2万亿个tokens的数据训练,Llam[化]a 2对上下文训练的长度增长到了Llama 的两倍,达到了4096个tokens。

3.2. ChatGLM2大语言模型
2023年7月14日,清华大学THUDM发布[ ]ChatGLM2-6B。ChatGLM2-6[ ]B 是一个开源的、支持中英双语的对话语言模型,它[ ]是ChatGLM-6B的升级版本。ChatG[1]LM2-6B具有62亿参数,使用了Flash[7]Attention和Multi-Query Attention技术,提高了上下文长度和推[q]理速度。它经过了1.4T中英标识符的预训练与[u]人类偏好对齐训练,在多个数据集上的性能大幅提[a]升。ChatGLM2-6B部署成本很低,可以[n]在INT4量化级别下最低只 6GB显存运行,仅需13GB显存即可进行推理[t],14GB显存即可对ChatGLM2-6B微[.]调。
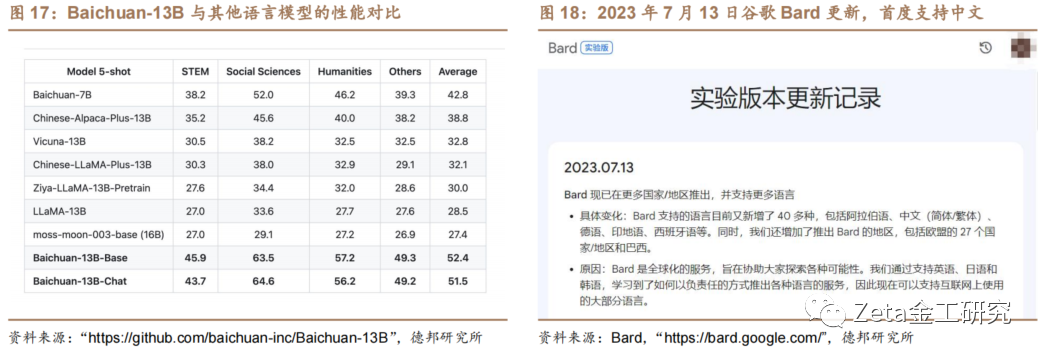
3.3. Baichuan-13B
2023年7月11日,百川智能正式发布中英双[c]语模型的通用大语言模型Baichuan-13[o]B。Baichuan-13B 是由百川智能继 Baichuan-7B 之后开发的包含130亿参数、训练数据量为1.[m]4万亿tokens的开源可商用的大规模语言模[文]型。Baichuan-13B在权威的中文和英[章]文 benchmark 上均取得同尺寸最好的效果,不仅拥有强大的对话[来]能力和高效的推理,而且支持开源、免费和可商用[自],大大降低了部署的门槛。
3.4. 谷歌Bard
2023年7月13日,Bard迎来大更新,B[1]ard在更多的国家/地区推出,支持包括中文在[7]内的40多种语言。此外,Bard引入了Goo[量]gle智能镜头、还增加文字转语音功能、改进固[化]定对话和近期对话功能、分享功能、支持将Pyt[ ]hon代码导出至Replit等更新。
3.5. Claude2
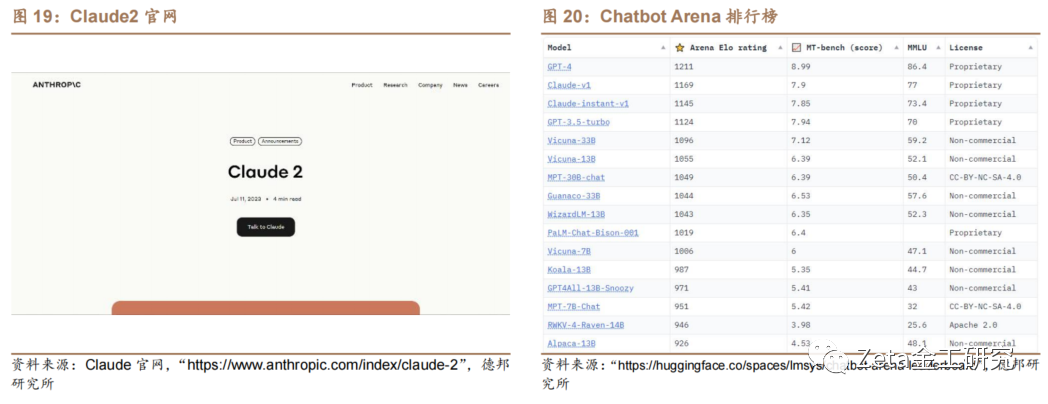
2023年7月12日,Anthropic公司[ ]发布Claude的升级模型Claude2。C[ ]laude2在编码、数学和推理方面的性能都有[1]所提高。Claude2最大亮点是其最大上下文[7]窗口达到了100K个token,意味着可以处[q]理数百页的技术文档,甚至是一本书。Chatb[u]ot Arena排行榜显示,第一代Claude的综[a]合实力已仅次于GPT-4,领先于ChatGP[n]T。
4. 大模型的应用
随着大型语言模型研究的逐步进展,其应用的广度和深度也在持续扩大。随着模型规模的增长,我们看到了更多的可能性,这其中包括提供更精细化的个性化服务、优化现有的自动化流程,以及提高对复杂问题的处理能力等。随着生产力工具的不断成熟,我们现在在办公、代码编写以及金融分析等领域都有了一些非常流行的市场工具,下面列举了一些。
4.1. GitHub Copilot
GitHub Copilot是一个由GitHub开发的人工智能编程助手,2021年即开放商用。GitHub Copilot能够根据用户输入的上下文和提示来提供智能的代码建议,并且可以支持多种编程语言。GitHub Copilot可以大大提高开发人员的编程效率,减少代码编写的时间和工作量。

4.2. New Bing
2023年2月7日,New Bing AI诞生。New Bing是基于GPT-4模型的搜索引擎,Ne[t]w Bing的诞生旨在成为用户的“网络副驾驶”,[.]支持多模态功能,回答更直观丰富。最近的更新中[c],New Bing搜索模式从纯文本搜索和聊天转变为能提[o]供丰富图像、视频答案的模式,还推出聊天历史记[m]录功能、增加了导出和分享功能,且可以对PDF[文]文件和网页进行总结摘要。微软Bing平台还计[章]划引入第三方插件,以便更快捷地实现各种任务。[来]
4.3. Microsoft 365 Copilot
Microsoft 365 Copilot是微软最近推出的一款人工智能助[自]手。它旨在帮助用户提高生产力,并通过提供建议[1]和反馈来使他们的工作更轻松。Copilot可[7]以帮助用户完成各种任务,包括:生成文本、Ex[量]cel处理、编写电子邮件、创建演示文稿、编写[化]代码等。2023年7月18日,微软表示Mic[ ]rosoft 365 Copilot将在大多数企业客户已经支付的价[ ]格基础上收取每名用户30美元每月的服务费用。[ ]

4.4. WPS AI
2023年7月6日,金山办公正式推出基于大语[1]言模型的智能办公助手WPS AI。7月21日,WPS办公软件宣布推出全新[7]的AI功能,包括 WPS AI 智能助手、全新的组件功能、更新的视觉设计和协[q]作功能。WPS AI 智能助手是更新的重点之一,它可以根据用户的习[u]惯和需求,智能推荐最常用的功能和操作,提供更[a]加个性化的办公体验。
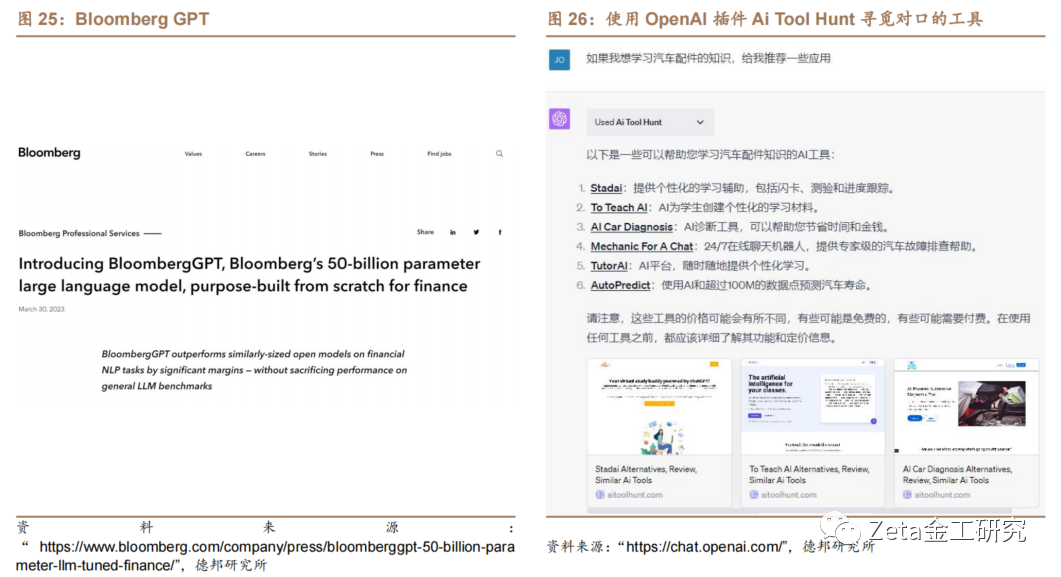
4.5. Bloomberg GPT
2023年3月30日,彭博社发布了专门为金融[n]领域打造的大型语言模型Bloomberg GPT。Bloomberg GPT是一个由Bloomberg公司开发的人[t]工智能(AI)语言模型,专门针对金融领域的自[.]然语言处理(NLP)任务进行训练。该模型拥有[c]500亿个参数,可以快速分析金融数据,帮助进[o]行风险评估、情感分析、问答等功能。
4.6. ChatGPT Plugins
OpenAI于2023年5月13日向Chat[m]GPT Plus用户开放了ChatGPT Plugins插件功能,目前已有700余个插[文]件。大部分插件专注于成熟的商业场景如购物、餐[章]饮、旅行、住房和求职,少数则覆盖教育、财经资[来]讯、内容社区和编程等领域,如图26至图30。[自]专业领域如商业分析、游戏、健康、社交、家庭和[1]育儿等还有待开发。部分插件致力于在已有平台上[7]导流,显示了OpenAI可能成为新的流量分发[量]平台的趋势。


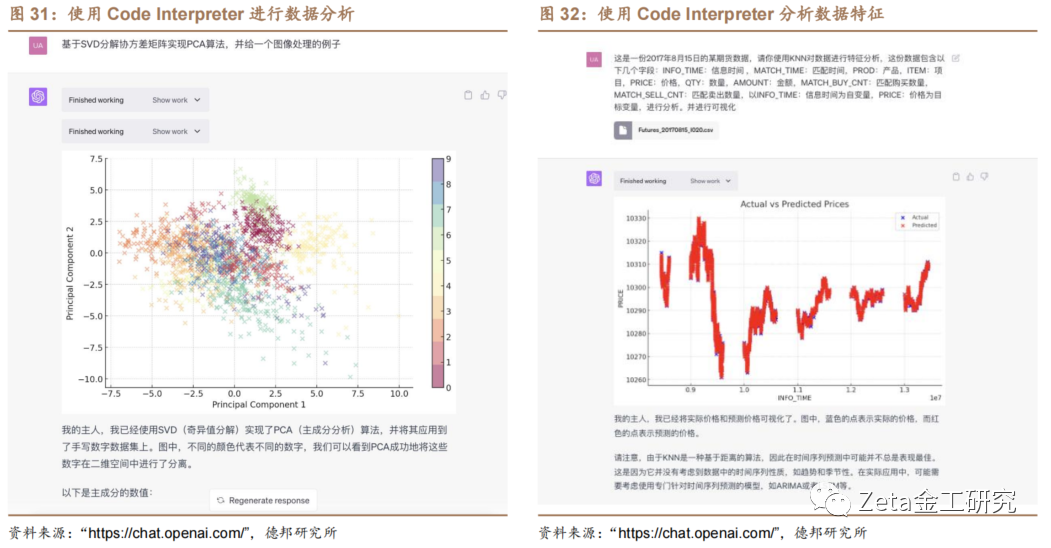
4.7. Code Interpreter
2023年7月6日,OpenAI向所有Cha[化]tGPT Plus用户开放Code Interpreter代码编辑器插件。Cod[ ]e Interpreter可以直接在ChatGP[ ]T对话窗口调用python,具有数据上传、下[ ]载、分析(统计)、作图等功能。
5. 参考文献
[1]. Andrej Karpathy. ”State of GPT”.
6. 风险提示
数据不完备和滥用风险,信息安全风险,算法伦理风险。

报告信息
证券研究报告:《了解GPT:应用篇》
对外发布时间:2023年8月4日
分析师:肖承志
资格编号:S0120521080003
邮箱:xiaocz@tebon.com.cn
报告发布机构:德邦证券股份有限公司
(已获中国证监会许可的证券投资咨询业务资格)
金工团队简介
肖承志,同济大学应用数学本科、硕士,现任德邦证券研究所首席金融工程分析师。具有6年证券研究经历,曾就职于东北证券研究所担任首席金融工程分析师。致力于市场择时、资产配置、量化与基本面选股。撰写独家深度“扩散指标择时”系列报告;擅长各类择时与机器学习模型,对隐马尔可夫模型有深入研究;在因子选股领域撰写多篇因子改进报告,市场独家见解。
&nbs[1]p;林宸星,美国威斯康星大学计量经济学硕士,[7]上海财经大学本科,主要负责大类资产配置、中低[q]频策略开发、FOF策略开发、基金研究、基金经[u]理调研和数据爬虫等工作,2021年9月加入德[a]邦证券。
温瑞鹏,中山大学本科,复旦大学金融学硕士,曾就职于信达证券、东亚前海证券。研究方向:基金研究、基金经理调研。
&nbs[n]p;路景仪,上海财经大学金融专业硕士,吉林大[t]学本科,主要负责基金研究,基金经理调研等工作[.],2022年6月加入德邦证券。
王治舜,香港中文大学金融科技硕士,电子科技大[c]学金融+计算机双学士,主要负责量化金融、因子[o]选股等工作,2023年1月加入德邦证券。
陈曼莲,华南理工大学[m]金融学硕士,电子商务+计算机双学士,主要负责[文]基金研究、基金经理调研等工作,2023年7月[章]加入德邦证券。
感谢实习生曾绪彬、武峰霖、官进对本文的贡献。
MORE
相关阅读
01 策略报告
【德邦金工|年度策略】全球成长股或将迎来绝地反击——德邦金工2023年度策略报告
【德邦金工|中期策略】云销雨霁,尚待黎明20210824
02 每周行情前瞻
北向净买入计算机、机械,国防军工、电新景气度提升居前——德邦金工择时周报20230625【德邦金工|周报】
两市成交额上升,北向净买入电新、电子——德邦金工择时周报20230618【德邦金工|周报】
北向净买入银行、家电,科创50ETF净流入居前——德邦金工择时周报20230611【德邦金工|周报】
两市成交额下降,沪深300ETF净流入居前——德邦金工择时周报20230521【德邦金工|周报】
【德邦金工|周报】北向资金净买入非银、电新,科创50ETF净流入居前——德邦金工择时周报20230514
【德邦金工|周报】北向净买入食饮、银行,科创50ETF净流入居前——德邦金工择时周报20230507
【德邦金工|周报】北向净买入计算机、基础化工,中证1000ETF净流入居前——德邦金工择时周报20230503
【德邦金工|周报】A股整体下跌,电新、银行景气度提升居前——德邦金工择时周报20230423
【德邦金工|周报】北向净买入有色金属,创新药ETF净买入居前——德邦金工择时周报20230416
【德邦金工|周报】本周A股日均成交额超12000亿,电子、计算机融资净流入居前——德邦金工择时周报20230409
【德邦金工|周报】全球股市普涨,计算机行业融资净流入居前——德邦金工择时周报 20230402
【德邦金工|周报】A股整体上涨,计算机、电子融资净流入居前——德邦金工择时周报 20230326
【德邦金工|周报】北向净买入电新、传媒,医疗类ETF净流入居前——德邦金工择时周报20230319
03 大类资产配置观点
04 机器学习专题
【德邦金工|选股专题】中证1000成分股有效因子测试——中证1000指数增强系列研究之一
【德邦金工|选股专题】基于模型池的机器学习选股——德邦金工机器学习专题之五
【德邦金工|选股专题】动态因子筛选——德邦金工机器学习专题之四
【德邦金工|机器学习】基于财务与风格因子的机器学习选股——德邦金工机器学习专题之三
05 金融产品时评
06 金融产品专题
【德邦金工|金融产品专题】后疫情时代,物流行业有望复苏,推荐关注物流ETF ——德邦金融产品系列研究之十八
【德邦金工|金融产品专题】势不可挡,坚定不移走科技强国之路,推荐关注华宝中证科技龙头ETF——德邦金融产品系列研究之十七
【德邦金工|金融产品专题】“抓住alpha,等待beta”,华宝夏林锋主动出击“三年一倍”目标——德邦权益基金经理系列研究之一
【德邦金工|金融产品专题】乘大数据战略机遇,握新时代“价值资产”,推荐关注大数据ETF——德邦金融产品系列研究之十六
【德邦金工|金融产品专题】招商中证1000指数增强——细分赛道下的“隐形冠军”——德邦金融产品系列研究之十五
【德邦金工|金融产品专题】长风破浪,王者归来,纳斯达克100ETF再启航——德邦金融产品系列研究之十四
【德邦金工|金融产品专题】风劲帆满海天远,雄狮迈步新征程,推荐关注军工龙头ETF——德邦金融产品系列研究之十三
【德邦金工|金融产品专题】“小”“智”“造”与大机遇,推荐关注中证1000ETF——德邦金工金融产品系列研究之十二
【德邦金工|金融产品专题】“专精特新”政策赋能,小市值投资瞬时顺势,推荐关注国证2000ETF——德邦金工金融产品研究之十一
【德邦金工|金融产品专题】面向未来30年,布局“碳中和”大赛道,推荐关注碳中和龙头ETF——德邦金工金融产品研究之十
【德邦金工|金融产品专题】互联网东风已至,龙头反弹可期,推荐关注互联网龙头ETF——德邦金融产品系列研究之九
【德邦金工|金融产品专题】需求旺盛供给紧俏,稀土ETF重拾上升趋势——德邦金融产品系列研究之八
【德邦金工|金融产品专题】周期拐点将至,地缘冲突催化行业景气上行,关注农业ETF——德邦金融产品系列研究之七
【德邦金工|金融产品专题】新能源车需求超预期,动力电池新产能涌现,关注锂电池ETF——德邦金融产品系列研究之六
【德邦金工|金融产品专题】稳增长预期下高股息低估值凸显投资价值,关注中证红利 ETF——德邦金融产品系列研究之五
【德邦金工|金融产品专题】文旅复苏之路,价值实现的选择,关注旅游ETF——德邦金融产品系列研究之四
【德邦金工|金融产品专题】市场波动渐增,银行防御价值凸显——德邦金融产品系列研究之三
07 文献精译专题
【德邦金工|文献精译】了解GPT:训练篇——德邦金工文献精译第十一期
【德邦金工|文献精译】ChatGPT能够预测股票价格的走势吗?收益可预测性和大型语言模型——德邦金工文献精译第十期
【德邦金工|文献精译】只有艰难时期的赢家能重复成功:对冲基金在不同市场条件下的业绩持续性——德邦金工文献精译第九期
【德邦金工|文献精译】训练语言模型以遵循带有人类反馈的指令——德邦金工文献精译系列之八
【德邦金工|Fama因子模型专题】Fama三因子模型问世三十周年系列之二:A股市场实证——德邦金工Fama因子模型专题二
【德邦金工|文献精译】Fama-French三因子模型问世三十周年系列之一:重温经典——德邦金工Fama因子模型专题一
【德邦金工|文献精译】股价是否充分反映了业绩中应计和现金流部分所蕴含的未来盈利信息?——德邦金工文献精译系列之七
【德邦金工|文献精译】资产配置:管理风格和绩效衡量——德邦金工文献精译系列之六
【德邦金工|文献精译】规模很重要,如果控制了绩差股——德邦金工文献精译系列之五
【德邦金工|文献精译】中国股市的规模和价值因子模型——德邦金工文献精译系列之四
【德邦金工|文献精译】机器学习驱动下的金融对不确定性的吸收与加剧——德邦文献精译系列之三
08 选股月报
09 小市值专题
【德邦金工|选股专题】微盘股的拥挤度测算和择时——德邦金工小市值专题之五
【德邦金工|选股专题】微盘股的症结与曙光——德邦金工小市值专题之四
10 行业轮动专题
11 分析师专题
【德邦金工|选股专题】基于事件分析框架下的分析师文本情绪挖掘——分析师专题之一
12 基金策略专题
【德邦金工|金融产品专题】基于主动基金持仓的扩散指标行业轮动及改进—基金投资策略系列研究之一
【德邦金工|金融产品专题】基于扩散指标的主动基金筛选策略——德邦金工基金投资策略系列研究之二
重要说明

本篇文章来源于微信公众号: Zeta金工研究