机器学习与因子(三):基于 Transformer 因子挖掘的指增策略


摘要
01
引言
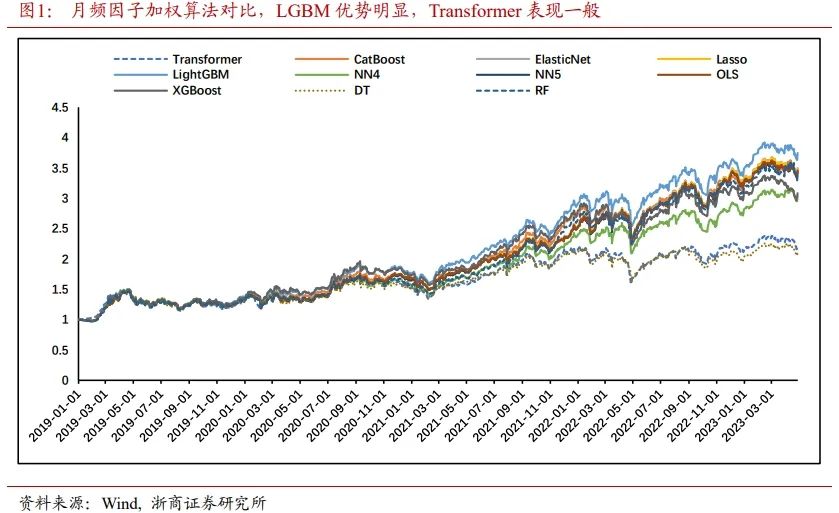
在机器学习与因子(二)中,我们尝试使用Transformer模型对月频因子进行加权。该加权方式相较于线性加权模型和梯度提升树模型,并没有在性能上展现出优势。主要原因在于Transformer是一种需要大参数量才能发挥性能优势的模型,而月频因子的样本量无法满足大参数模型的训练需求。相对于训练样本,过于复杂的模型设定非常容易出现过拟合。然而,浅层的模型设计又无法发挥出Transformer模型的优势。
本文调整了Transformer模型的功能设定,由因子加权改为因子挖掘,并且使用日频交易数据作为基础数据,大幅提升了可供模型训练的样本。
02
数据与模型
2.1. 数据
本文选用全A股票池,剔除上市不满120个交易日的股票和ST股票。ST股票在取消ST标识30交易日后重新加入股票池。本文使用2007年1月1日至2018年12月31日的数据作为训练集,2019年1月1日至2019年12月31日的数据作为验证集,2020年1月1日至2023年11月20日的数据作为测试集。
本文使用的基础特征数据是股票日频开盘价、最高价、最低价、收盘价、VWAP和换手率。为了统一量纲,消除股票间绝对价格不可比的情况,且保存特征在时序上的动态信息,对于5个价格数据,单只股票时序上都除以t-T日收盘价;对于换手率,时序上都除以t-T日换手率。其中,t为样本日,T为模型的时间步长。经过测试,T取20以上,模型的性能较好。为平衡计算开销和模型性能,本文T取30。
为了同时保存特征在截面和时序上的大小关系,在统一量纲之后,进行z-score标准化。对于同一特征,在整个训练集上采用相同的参数进行标准化。本文未采用训练求解参数的方式,而是将参数固定为特征在训练集上的均值和标准差。验证集和测试集的标准化使用训练集的参数。
经过以上处理,可得到模型的输入数据,维度信息为(samplesize * T * 6)。
2.2. 模型设计
2.2.1 模型架构
模型架构方面,本文在机器学习多因子(二)Transformer架构基础上做调整。时间信息的赋值方法,机器学习多因子(二)采用位置编码与特征时序相加,本文改为Time2Vec与特征时序数据的合并。模型深度方面,机器学习多因子(二)中经过测试,1层encoder效果最好,超过1层encoder非常容易过拟合。本文使用的训练样本量提升至623万条,encoder的层数限制得到突破。集成学习方面,本文独立多轮训练模型,对每个模型得到的TF因子进行加权后,得到最终的集成因子TF_E。
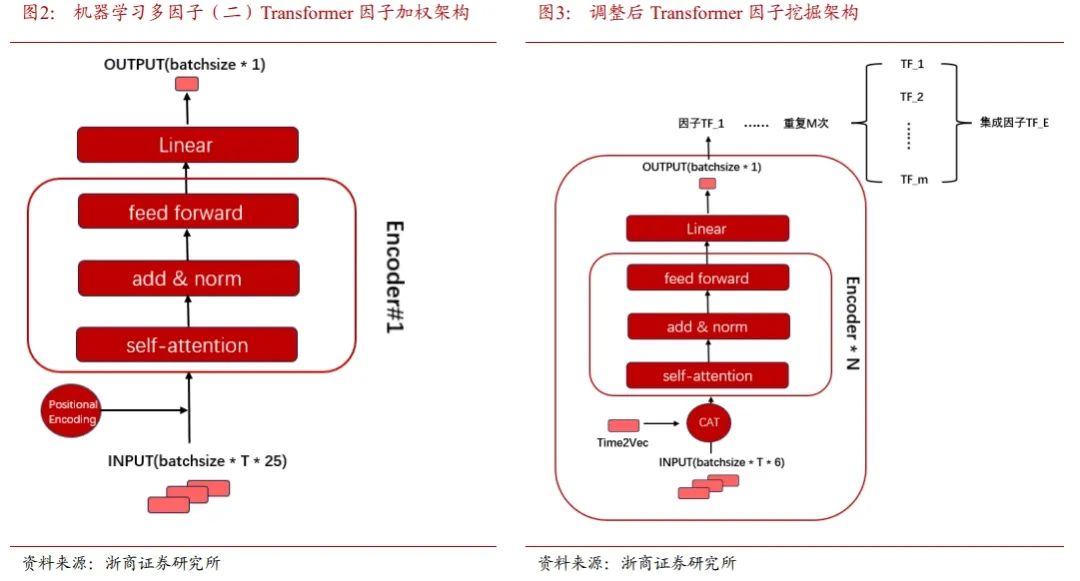
损失函数方面,本文测试了MSELoss, -IC, MSELoss -λ*IC三种损失计算的方法。不同损失函数的选取对模型输出的结果影响不明显

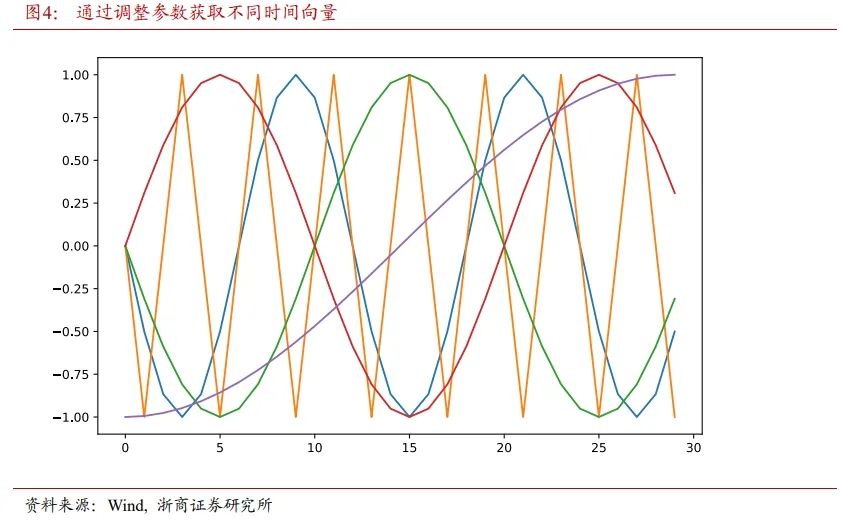
图4横坐标为时间步长,纵坐标为时间向量的值。通过调整ω和φ,可以得到不同周期和相位的时间向量。
2.2.2 弱化模型随机性
深度学习算法在多个方面受到随机变量的影响。不同的初始参数会影响模型的梯度大小和方向,进而影响模型的更新速度和路径,最终可能导致模型在训练过程中收敛到不同的局部最优解。数据集中的随机性也会对算法的结果产生影响。在模型训练的每个迭代中,随机抽样的数据批次可能会导致模型在不同迭代中学习不同的特征或模式,从而影响最终的结果。不同的优化器则可能会导致模型在参数空间中的轨迹不同,从而影响最终结果的质量和泛化能力。
为了弱化随机变量对模型输出的影响,本文对数据进行了增强,并集成多次训练结果。数据增强方面,为了增加模型的鲁棒性,训练集的喂入顺序不按照原始时间顺序,而是整个训练集打乱后随机抽选batch喂入。集成学习方面,本文随机选取60个种子,独立进行60次训练,对结果进行集成。
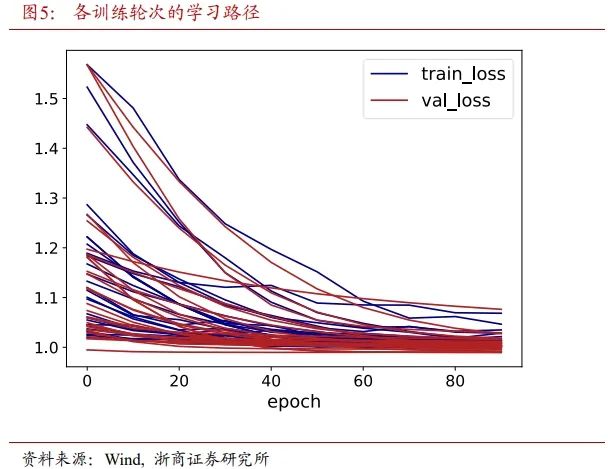
图5展示了各训练轮次所对应的学习路径。若连续10个Epoch,验证集损失不下降,停止该轮次的训练。绝大部分模型在训练到40个Epoch后,验证集损失已经收敛。虽然各个模型的初始位置不同,但是最终验证集损失都收敛到一个狭窄的区间。
03
因子检验
3.1. 因子ICIR
通过60轮独立训练得到60个TF因子。然后使用LGBM对这60个因子进行集成,得到最终的TF_E因子。对TF_E因子进行中性化之后,评价因子表现。2020年1月1日至2023年11月20日,持有20交易日,TF_E因子IC为16.39%,IR为1.68。
3.2. 因子分层测试
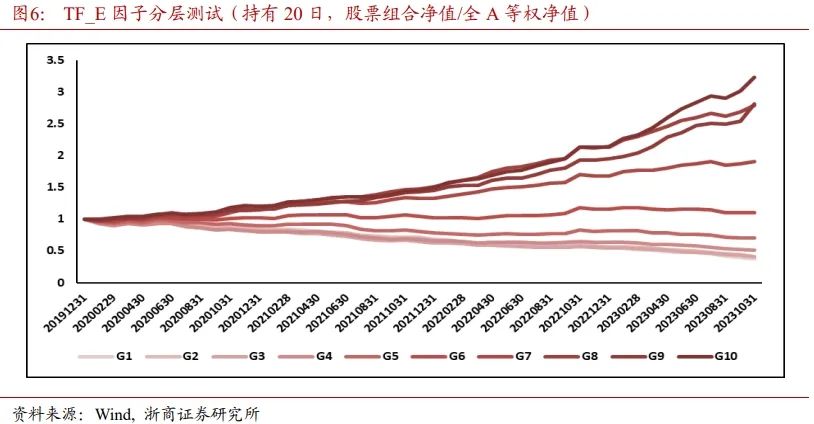
图6展示了TF_E因子的10分层效果,每一条曲线代表该层股票的组合净值/全A等权净值。整体上,TF_E因子的分层效果较好。
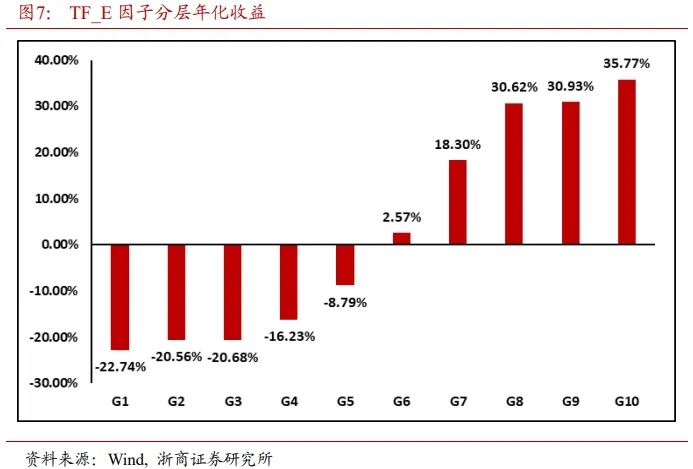
图7展示了TF_E因子的单调性。除第2和第3组的单调性走平之外,整体上,TF_E因子的分层年化收益呈现单调递增,单调性较好。
3.3. 因子相关性检测
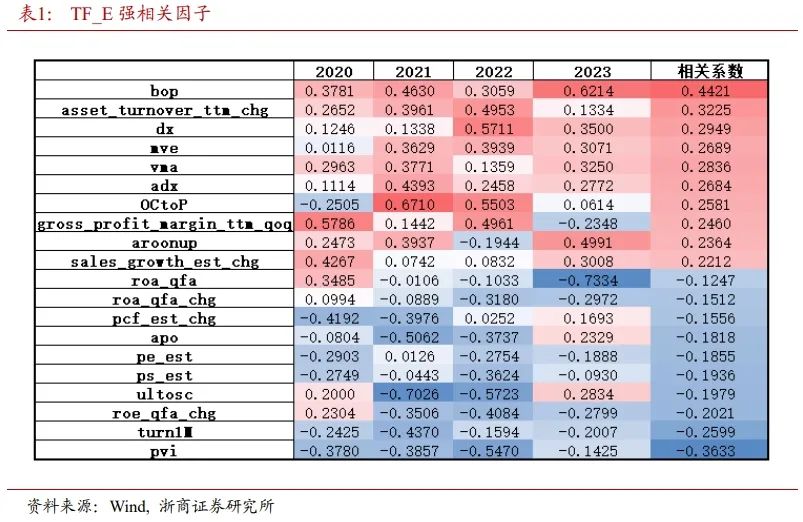
2020年以来,与TF_E正相关最强的因子主要是估值、资产周转和规模因子;与TF_E负相关最强的因子主要是资产收益和一致预期类因子。
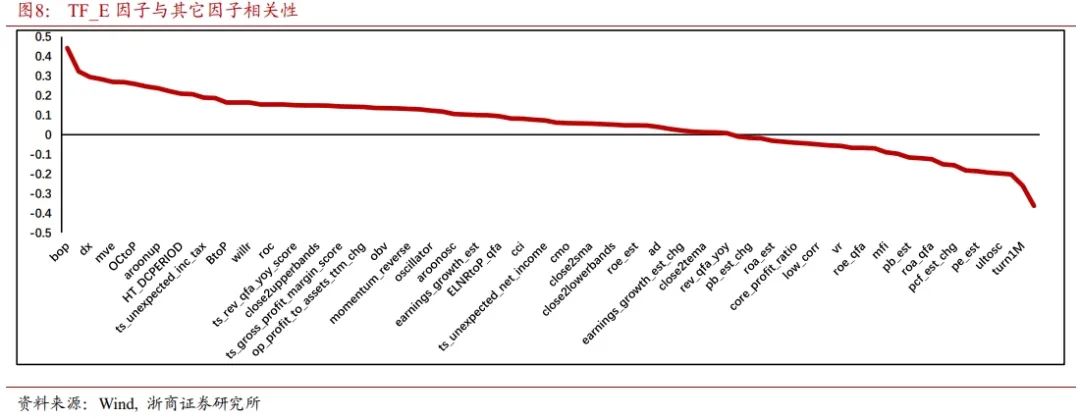
经过因子检验后可知,TF_E因子有效性强,因子收益稳定,分层效果良好,与现有基本面因子、技术类因子、预期类因子相关性较低。可以作为一个差异化的Alpha收益来源补充。
04
基于TF_E因子的指数增强策略
得到TF_E因子后,在2020年1月1日至2023年11月20日区间内(本章节进行实证检验统一使用该数据区间),构建主要宽基指数增强策略,并对比添加TF_E因子前后,各指增策略的绩效表现。
本章所构建的指数增强策略,采用的要素如表2所示。为避免空气指增,构建的指增策略对行业偏离和个股偏离做出比较严格的约束。

本文指增策略规定调仓频率为月频,绩效指标和回测曲线都是费后表现,费率设置为双边千分之四。
对于未添加TF_E因子的基准指增策略,本文使用浙商金工因子库进行指数增强,并规定大类因子的权重为等权,大类因子内部加权的方式为ICIR加权。得到基准指增策略后,再添加TF_E因子到技术类因子中,采取和基准策略相同的因子加权方式,以检验TF_E因子对于基准指增策略的边际收益贡献和回撤贡献。

如表3所示,添加TF_E因子后,各宽基指数的指增策略绩效表现都有显著提升,以沪深300和中证1000指增提升最为显著。沪深300和中证1000指增在添加TF_E因子后,超额净值的增幅大于1。信息比率方面,中证1000和中证500的信息比率提升大于2,TF_E因子能有效提升指增策略的性价比。

如表4所示,添加TF_E因子后,各指增策略换手率有所降低。原因在于,在上述三个基准成分内的个股,其在TF_E因子的暴露较稳定。如果仅使用TF_E因子构建指增策略,经测试,中证1000指增的月单边换手率为25%。其次,构建指增的因子增加后,单个因子权重降低,有助于平滑个股因子加权结果。
4.1. 中证1000指增策略
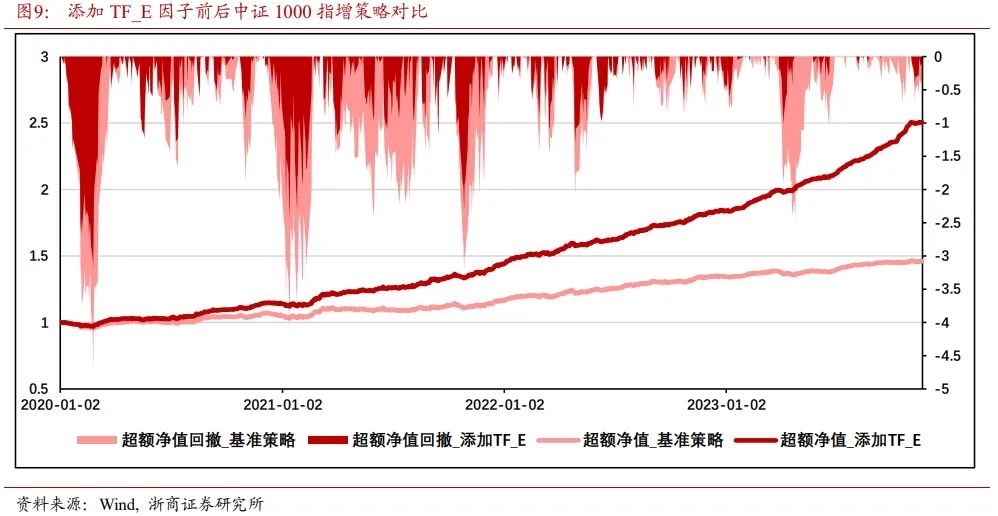
如图9所示,在未使用TF_E因子对中证1000指数进行增强时,策略已经能取得较稳健的收益。其超额净值为1.46,超额净值最大回撤发生在2020年1月,达到4.72%。
添加TF_E因子后,指增策略曲线表现更为平滑。其超额净值上升至2.51,超额净值最大回撤发生在2020年1月,降低至3.18%。TF_E因子边际贡献超额净值104.45%,超额最大回撤-1.54%。
4.2. 沪深300指增策略
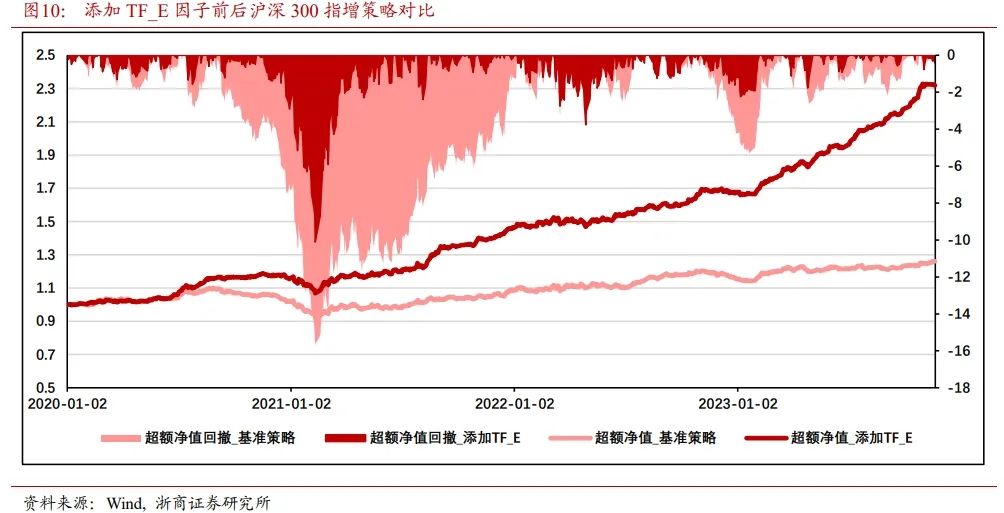
如图10所示,在未使用TF_E因子对沪深300指数进行增强时,策略收益低,回撤大。其超额净值仅1.26,超额净值最大回撤发生在2021年2月,达到15.66%。
添加TF_E因子对沪深300指数进行增强后,策略收益显著提升,最大超额回撤也有所收敛。策略超额净值2.32,超额净值最大回撤发生在2021年2月,达到10.11%。TF_E因子边际贡献超额净值105.72%,超额最大回撤-5.55%。
4.3. 中证500指增策略
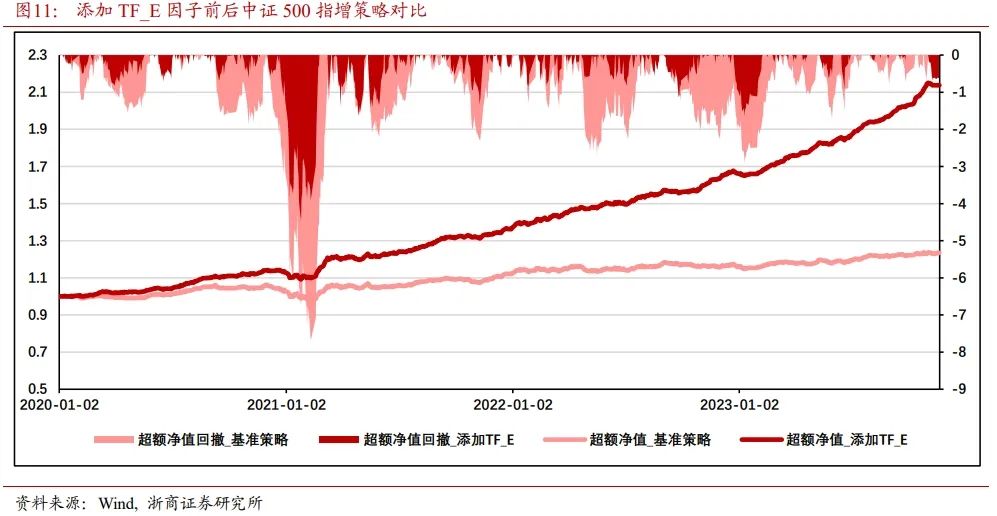
如图11所示,在未使用TF_E因子对中证500指数进行增强时,策略收益低,回撤较大。策略超额净值仅1.23,超额净值最大回撤发生在2021年1月,达到7.39%
添加TF_E因子对中证500指数进行增强后,策略收益显著提升,最大超额回撤有所收敛。策略超额净值2.14,超额净值最大回撤发生在2021年1月,达到4.47%。TF_E因子边际贡献超额净值90.32%,超额最大回撤-3.22%。
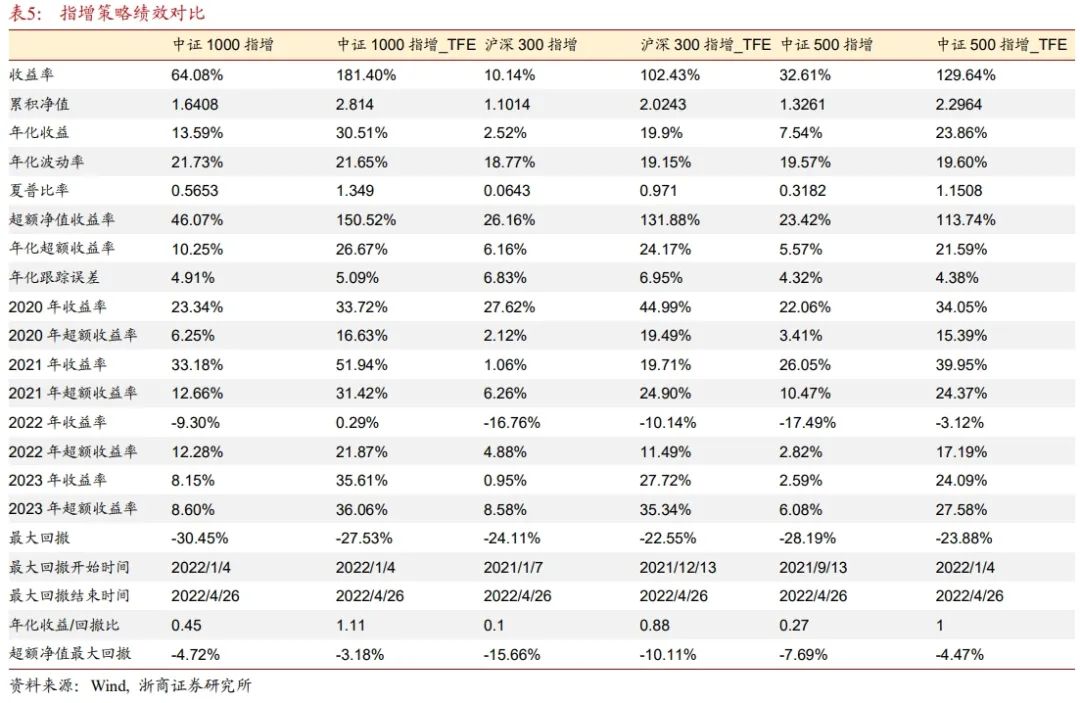
表5展示了各指增策略的绩效评价指标。添加了TF_E因子的指增策略相比未添加的策略,从收益,波动,回撤,夏普等多个方面对比,都有明显提升。
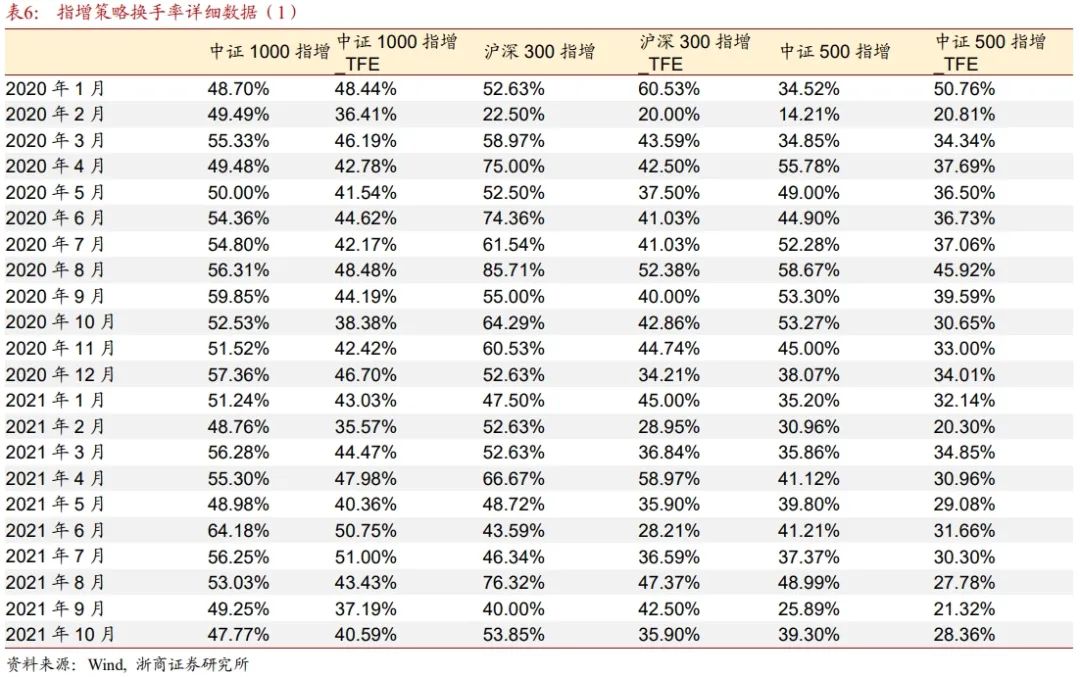
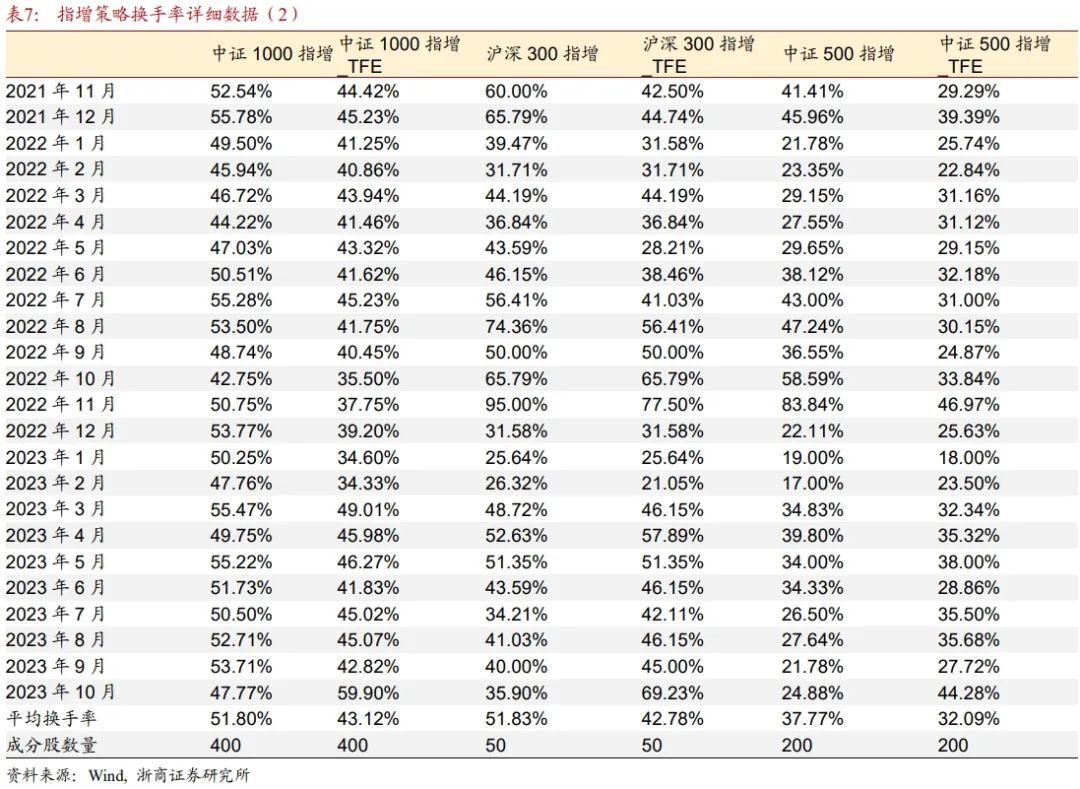
表6和表7详细列示了各指增策略的月度单边换手率数据。总体上来说,由于沪深300指增策略的成分股数量较少(成分股数量占基准成分的1/6),策略月度换手率高于其它两个策略(成分股数量占基准成分的2/5)。添加了TF_E因子后,各个策略在绝大多数月份,相比未添加TF_E因子,换手率都有所降低。
05
研究结论
前序报告研究过Transformer模型在因子加权端的应用,由于算法复杂度和样本量不匹配的原因,模型并未达到期望的目标。
本文通过数据提频,大幅增加训练样本,改变时间信息赋值方法,多轮训练结果集成的方式,使得Transformer模型可以达到预设的因子挖掘目标。
Transformer模型能有效提取股票价量时序信息中的特征。通过多轮训练并集成后的TF_E因子,20日IC均值为16.39%,IR为1.68。因子有效性强,稳定性好。
通过Transformer挖掘出的因子,与现有的大类因子的相关性较低,因子收益来源较独立,可以作为传统基本面,技术面和预期类因子库的差异化补充。
在现有因子池进行指增策略构建的基础上,TF_E因子带来边际贡献。以中证1000指增策略为例,TF_E因子贡献超额净值回报104.45%,贡献超额最大回撤-1.54%,贡献换手率-8.68%。其它指增策略也有类似的提升效果。
本文也测试了3种损失函数(MSELoss, -IC, MSELoss-λ*IC)对模型结果的影响,并未发现不同的损失函数对模型结果造成显著影响。
06
风险提示
模型测算风险:超参数设定对深度学习模型结果有较大影响;收益指标等指标均限于一定测试时间和测试样本得到,收益指标不代表未来。
模型失效风险:机器学习模型基于历史数据进行测算,不能直接代表未来,仅供参考。
数据风险:未来的数据分布和特征可能与历史数据分布不一致,从而造成模型失效。
报告作者:
陈奥林 从业证书编号 S1230523040002
陆达 从业证书编号 S1230122070032
详细报告请查看2023年8月26日发布的浙商证券金融工程专题报告《指数增强产品:回撤结束了吗?》
法律声明:
本公众号为浙商证券金工团队设立。本公众号不是浙商证券金工团队研究报告的发布平台,所载的资料均摘自浙商证券研究所已发布的研究报告或对报告的后续解读,内容仅供浙商证券研究所客户参考使用,其他任何读者在订阅本公众号前,请自行评估接收相关推送内容的适当性,使用本公众号内容应当寻求专业投资顾问的指导和解读,浙商证券不因任何订阅本公众号的行为而视其为浙商证券的客户。
本公众号所载的资料摘自浙商证券研究所已发布的研究报告的部分内容和观点,或对已经发布报告的后续解读。订阅者如因摘编、缺乏相关解读等原因引起理解上歧义的,应以报告发布当日的完整内容为准。请注意,本资料仅代表报告发布当日的判断,相关的研究观点可根据浙商证券后续发布的研究报告在不发出通知的情形下作出更改,本订阅号不承担更新推送信息或另行通知义务,后续更新信息请以浙商证券正式发布的研究报告为准。
本公众号所载的资料、工具、意见、信息及推测仅提供给客户作参考之用,不构成任何投资、法律、会计或税务的最终操作建议,浙商证券及相关研究团队不就本公众号推送的内容对最终操作建议做出任何担保。任何订阅人不应凭借本公众号推送信息进行具体操作,订阅人应自主作出投资决策并自行承担所有投资风险。在任何情况下,浙商证券及相关研究团队不对任何人因使用本公众号推送信息所引起的任何损失承担任何责任。市场有风险,投资需谨慎。
浙商证券及相关内容提供方保留对本公众号所载内容的一切法律权利,未经书面授权,任何人或机构不得以任何方式修改、转载或者复制本公众号推送信息。若征得本公司同意进行引用、转发的,需在允许的范围内使用,并注明出处为“浙商证券研究所”,且不得对内容进行任何有悖原意的引用、删节和修改。
廉洁声明:
我司及业务合作方在开展证券业务及相关活动中,应恪守国家法律法规和廉洁自律的规定,遵守相关行业准则,遵守社会公德、商业道德、职业道德和行为规范,公平竞争,合规经营,忠实勤勉,诚实守信,不直接或者间接向他人输送不正当利益或者谋取不正当利益。
本篇文章来源于微信公众号: Allin君行